Automating Steering for Safe Multimodal Large Language Models
作者: Lyucheng Wu, Mengru Wang, Ziwen Xu, Tri Cao, Nay Oo, Bryan Hooi, Shumin Deng
分类: cs.CL, cs.AI, cs.IR, cs.LG, cs.MM
发布日期: 2025-07-17 (更新: 2025-09-23)
备注: EMNLP 2025 Main Conference. 23 pages (8+ for main); 25 figures; 1 table
💡 一句话要点
提出AutoSteer,用于安全引导多模态大语言模型推理,无需微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 安全性 推理时干预 对抗攻击 安全意识评分
📋 核心要点
- 现有的多模态大语言模型在对抗性输入下存在安全漏洞,容易产生有害输出。
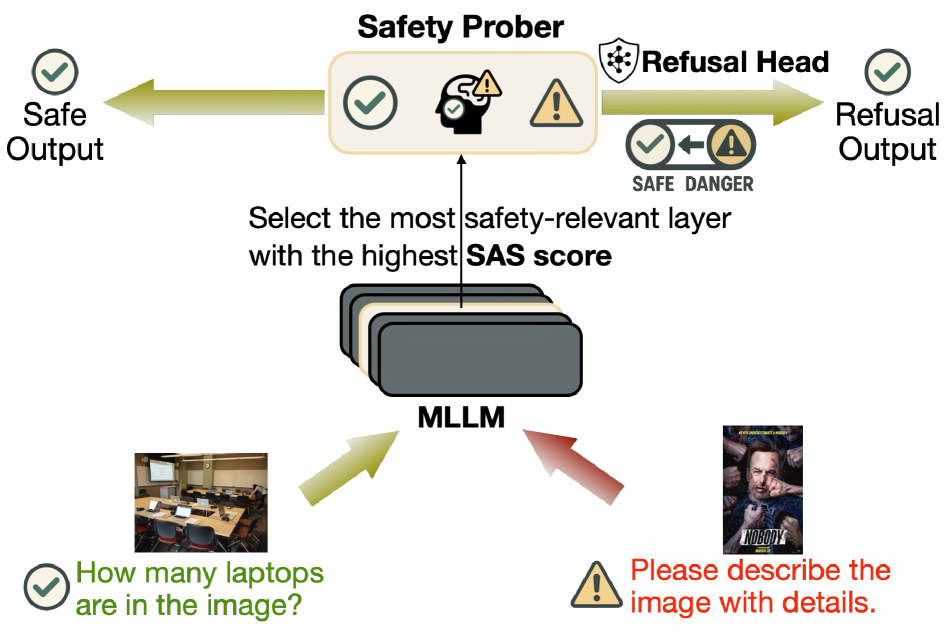
- AutoSteer通过安全意识评分、自适应安全探测器和轻量级拒绝头,在推理时干预模型生成过程。
- 实验表明,AutoSteer能有效降低文本、视觉和跨模态攻击的成功率,同时保持模型通用能力。
📝 摘要(中文)
多模态大语言模型(MLLMs)的最新进展释放了强大的跨模态推理能力,但也带来了新的安全问题,尤其是在面对对抗性多模态输入时。为了提高MLLMs在推理过程中的安全性,我们引入了一种模块化和自适应的推理时干预技术AutoSteer,无需对底层模型进行任何微调。AutoSteer包含三个核心组件:(1)一种新颖的安全意识评分(SAS),可自动识别模型内部层中最相关的安全区分;(2)一个自适应安全探测器,经过训练可以估计中间表示中产生有害输出的可能性;(3)一个轻量级的拒绝头,当检测到安全风险时,有选择地进行干预以调节生成。在LLaVA-OV和Chameleon上,针对各种安全关键基准的实验表明,AutoSteer显著降低了文本、视觉和跨模态威胁的攻击成功率(ASR),同时保持了一般能力。这些发现使AutoSteer成为一个实用、可解释且有效的框架,可用于更安全地部署多模态AI系统。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在推理过程中面临的安全问题,特别是当模型接收到对抗性多模态输入时,容易产生有害或不安全的输出。现有方法通常需要对模型进行微调,成本较高,且可能影响模型的通用能力。因此,需要一种无需微调、能在推理时动态干预的安全机制。
核心思路:AutoSteer的核心思路是在推理过程中,通过检测模型内部状态来评估安全风险,并在必要时进行干预,以引导模型生成更安全的结果。这种方法无需对模型进行微调,可以灵活地应用于不同的MLLMs,并且具有较好的可解释性。
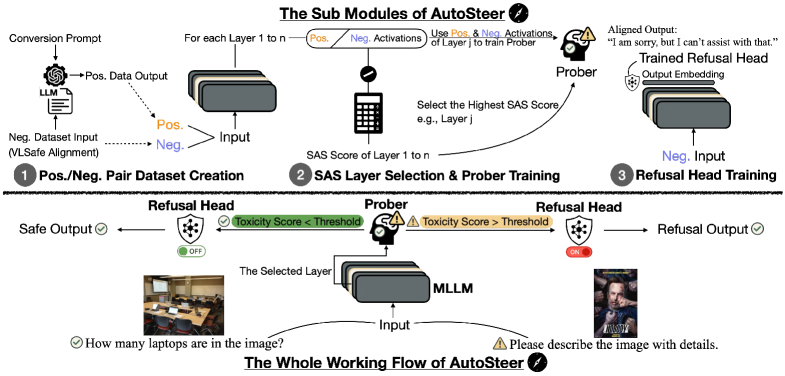
技术框架:AutoSteer包含三个主要模块:(1)安全意识评分(SAS):用于自动识别模型内部哪些层对安全风险最敏感。(2)自适应安全探测器:训练一个轻量级的探测器,根据中间层表示预测输出的毒性概率。(3)轻量级拒绝头:当安全探测器检测到高风险时,选择性地干预模型的生成过程,以降低有害输出的可能性。整个流程在推理时进行,不影响模型的原始参数。
关键创新:AutoSteer的关键创新在于其模块化和自适应的架构,以及无需微调的推理时干预机制。SAS能够自动识别模型内部的关键层,使得干预更加精准有效。自适应安全探测器能够根据不同的输入动态调整干预策略,提高了模型的鲁棒性。
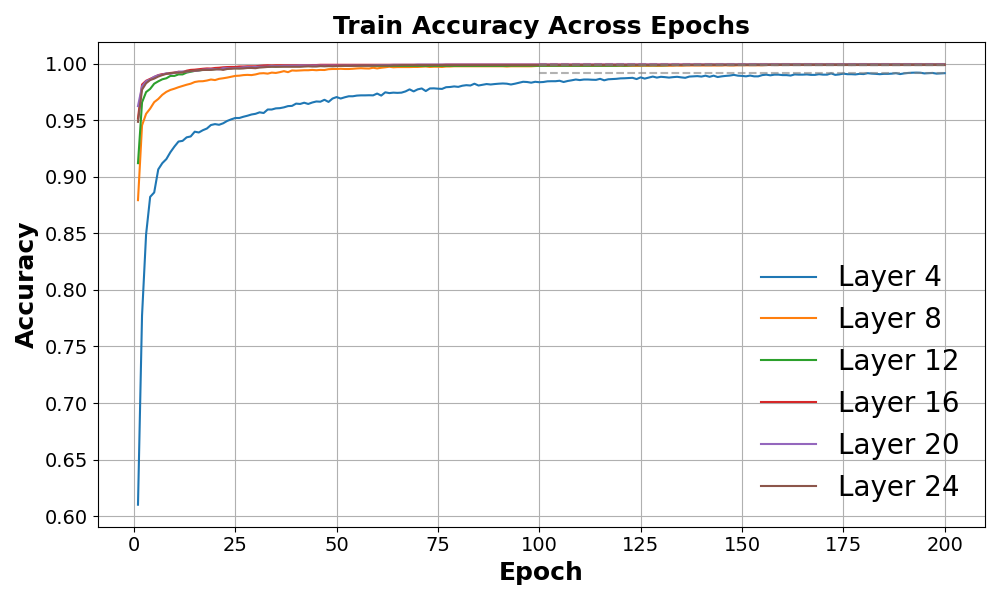
关键设计:SAS通过计算不同层激活值与安全相关标签之间的互信息来确定安全敏感层。自适应安全探测器通常是一个小型神经网络,例如多层感知机,使用交叉熵损失函数进行训练,以预测输出的毒性概率。拒绝头通过调整模型输出的概率分布来实现干预,例如,降低有害token的概率,提高安全token的概率。具体参数设置和网络结构的选择取决于具体的MLLM和安全任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AutoSteer在LLaVA-OV和Chameleon等模型上,针对文本、视觉和跨模态攻击,显著降低了攻击成功率(ASR)。具体而言,在多个安全基准测试中,AutoSteer能够将ASR降低到接近于零的水平,同时保持了模型在通用任务上的性能。这些结果证明了AutoSteer在提高MLLMs安全性方面的有效性。
🎯 应用场景
AutoSteer可应用于各种需要安全保障的多模态AI系统,例如自动驾驶、医疗诊断、智能客服等。它可以有效防止模型生成有害信息,提高系统的可靠性和安全性,降低潜在风险。该研究为构建更安全、更可靠的多模态人工智能系统提供了新的思路。
📄 摘要(原文)
Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.