Logit Arithmetic Elicits Long Reasoning Capabilities Without Training
作者: Yunxiang Zhang, Muhammad Khalifa, Lechen Zhang, Xin Liu, Ayoung Lee, Xinliang Frederick Zhang, Farima Fatahi Bayat, Lu Wang
分类: cs.CL, cs.AI
发布日期: 2025-07-17
💡 一句话要点
提出ThinkLogit,无需训练即可激发大模型长推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长推理 logits算术 知识迁移 偏好优化 大型语言模型 解码时干预 无训练学习
📋 核心要点
- 现有大型语言模型在长推理方面存在潜力,但需要额外的训练才能有效激发。
- ThinkLogit利用logits算术,通过小型引导模型在解码时调整大型目标模型,实现长推理。
- ThinkLogit及其DPO变体在数学数据集上显著提升了推理性能,且能迁移强化学习习得的技能。
📝 摘要(中文)
大型推理模型(LRM)可以通过包含回溯和自我纠正等认知策略的长链式思考(CoT)进行复杂的推理。最近的研究表明,一些模型本身就具有这些长推理能力,可以通过额外的训练来解锁。本文研究了是否可以在没有任何训练的情况下激发这种行为。为此,我们提出了一种解码时方法ThinkLogit,它利用logits算术来调整目标大型LM,使用一个更小的模型作为引导器进行长推理。然后,我们表明,通过使用从目标模型和引导模型中采样的正确/不正确推理对,使用偏好优化训练引导模型,可以进一步提高性能——我们称之为ThinkLogit-DPO。实验表明,当使用R1-Distill-Qwen-1.5B(一个比Qwen2.5-32B小21倍的模型)引导时,ThinkLogit和ThinkLogit-DPO在四个数学数据集上实现了pass@1相对改进分别为26%和29%。最后,我们表明ThinkLogit可以转移通过强化学习获得的长推理技能,与Qwen2.5-32B基础模型相比,pass@1相对提高了13%。这项工作提出了一种计算效率高的方法,可以用最少或无需额外训练来激发大型模型中的长推理能力。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)虽然具备一定的推理能力,但要充分发挥其在复杂推理任务中的潜力,通常需要大量的训练数据和计算资源。尤其是在长链式推理(long chain-of-thought, CoT)场景下,模型容易出现推理中断或错误累积的问题。因此,如何在不进行额外训练的情况下,有效激发LLM的长推理能力是一个重要的研究问题。
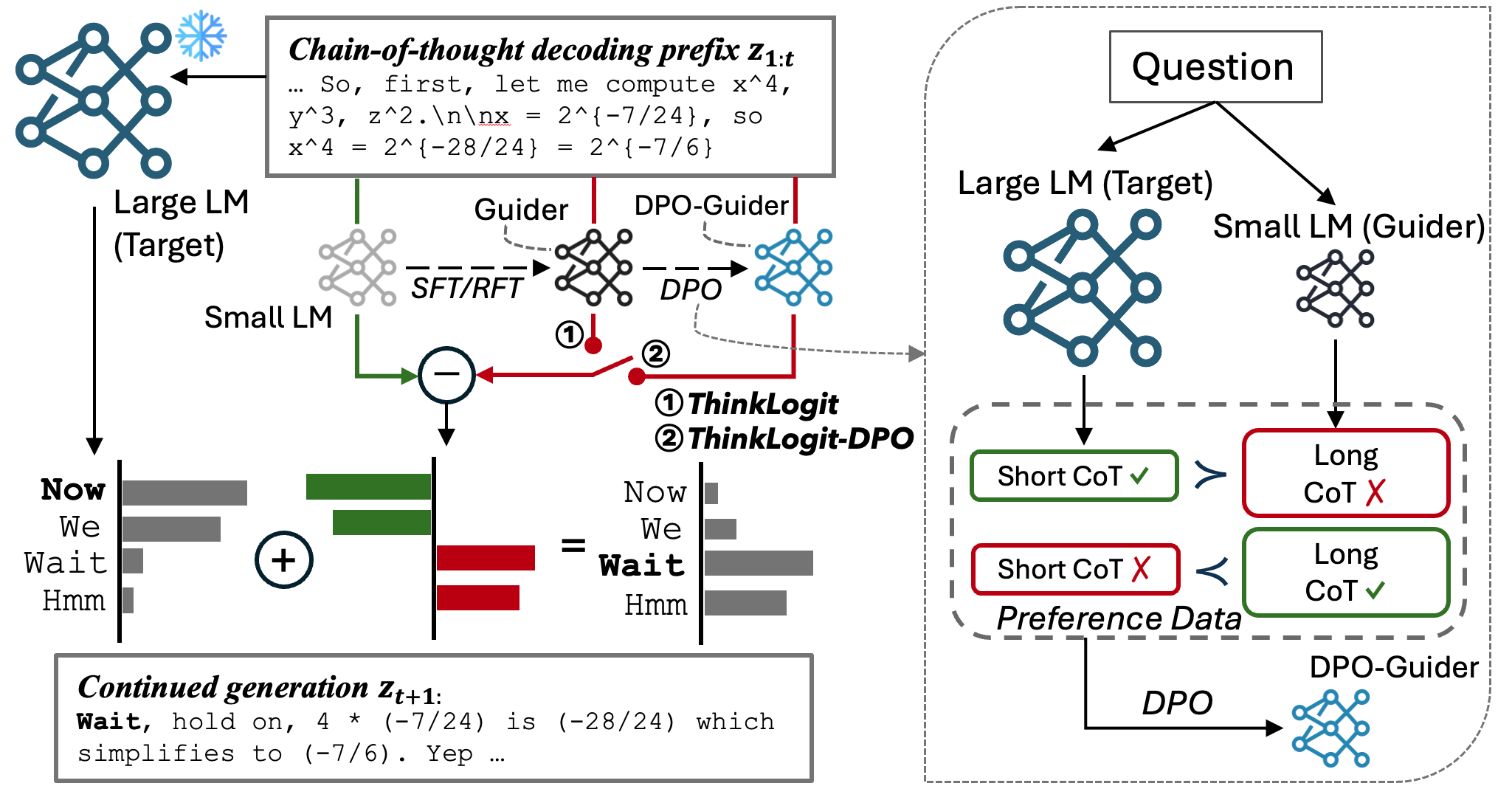
核心思路:ThinkLogit的核心思路是利用一个较小的引导模型(guider model)来影响大型目标模型(target model)的logits输出,从而引导其进行更有效的长推理。具体来说,通过logits算术,将引导模型的logits信息融入到目标模型的logits中,使得目标模型的输出更倾向于引导模型认为正确的方向。这种方法无需对目标模型进行任何训练,即可提升其推理能力。
技术框架:ThinkLogit的整体框架包括两个主要部分:一个大型的目标语言模型和一个较小的引导模型。在推理过程中,首先使用目标模型和引导模型分别生成logits。然后,使用logits算术将引导模型的logits信息融入到目标模型的logits中。最后,使用修改后的logits进行解码,生成最终的推理结果。ThinkLogit-DPO在此基础上,使用偏好优化(Preference Optimization)方法训练引导模型,使其更好地引导目标模型进行推理。
关键创新:ThinkLogit的关键创新在于提出了一种无需训练即可激发大型模型长推理能力的方法。通过logits算术,将小型引导模型的知识迁移到大型目标模型中,实现了计算效率和性能的平衡。此外,ThinkLogit-DPO通过偏好优化进一步提升了引导模型的质量,从而提高了整体的推理性能。
关键设计:ThinkLogit的关键设计包括logits算术的具体公式,以及ThinkLogit-DPO中偏好优化的损失函数。logits算术的具体公式决定了引导模型对目标模型的影响程度。偏好优化的损失函数则用于训练引导模型,使其能够更好地区分正确和错误的推理路径。具体参数设置(例如logits融合的权重)需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ThinkLogit和ThinkLogit-DPO在四个数学数据集上,使用R1-Distill-Qwen-1.5B引导Qwen2.5-32B时,pass@1相对改进分别达到26%和29%。此外,ThinkLogit能够将通过强化学习获得的长推理技能迁移到目标模型,使pass@1相对提高了13%。这些结果表明ThinkLogit是一种有效的长推理能力激发方法。
🎯 应用场景
ThinkLogit可应用于各种需要复杂推理的场景,如数学问题求解、代码生成、知识图谱推理等。该方法降低了对大型模型进行微调的成本,使得在资源有限的情况下也能有效提升模型的推理能力。未来,可以探索将ThinkLogit应用于更多领域,并研究如何进一步优化引导模型的训练方法。
📄 摘要(原文)
Large reasoning models (LRMs) can do complex reasoning via long chain-of-thought (CoT) involving cognitive strategies such as backtracking and self-correction. Recent studies suggest that some models inherently possess these long reasoning abilities, which may be unlocked via extra training. Our work first investigates whether we can elicit such behavior without any training. To this end, we propose a decoding-time approach, ThinkLogit, which utilizes logits arithmetic (Liu et al., 2024) to tune a target large LM for long reasoning using a substantially smaller model as guider. We then show that we can further boost performance by training the guider model with preference optimization over correct/incorrect reasoning pairs sampled from both the target and guider model -- a setup we refer to as ThinkLogit-DPO. Our experiments demonstrate that ThinkLogit and ThinkLogit-DPO achieve a relative improvement in pass@1 by 26% and 29%, respectively, over four mathematical datasets using the Qwen2.5-32B when guided by R1-Distill-Qwen-1.5B -- a model 21x smaller. Lastly, we show that ThinkLogit can transfer long reasoning skills acquired through reinforcement learning, improving pass@1 by 13% relative compared to the Qwen2.5-32B base model. Our work presents a computationally-efficient method to elicit long reasoning in large models with minimal or no additional training.