AdaptiSent: Context-Aware Adaptive Attention for Multimodal Aspect-Based Sentiment Analysis
作者: S M Rafiuddin, Sadia Kamal, Mohammed Rakib, Arunkumar Bagavathi, Atriya Sen
分类: cs.CL
发布日期: 2025-07-17
备注: 12 pages (including references), 2 figures (Fig. 1 overview, Fig. 2 hyperparameter sensitivity with two subplots), 6 tables (performance, ablation, dataset stats, case studies, etc.), accepted at ASONAM 2025 (Social Network Analysis and Mining)
💡 一句话要点
AdaptiSent:提出上下文感知自适应注意力机制,用于多模态方面级情感分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 方面级情感分析 自适应注意力 跨模态融合 上下文感知 深度学习 自然语言处理
📋 核心要点
- 现有MABSA方法难以有效捕捉文本和图像之间复杂的交互关系,限制了情感分析的准确性。
- AdaptiSent通过引入动态模态权重和上下文自适应注意力机制,使模型能够动态关注关键的跨模态信息。
- 实验结果表明,AdaptiSent在标准Twitter数据集上显著优于现有方法,尤其在识别细微模态间关系方面。
📝 摘要(中文)
本文提出了一种新的多模态方面级情感分析(MABSA)框架AdaptiSent,它利用自适应跨模态注意力机制来改进文本和图像中的情感分类和方面术语提取。该模型集成了动态模态权重和上下文自适应注意力,通过关注文本线索和视觉上下文如何交互,增强了情感和方面相关信息的提取。在标准Twitter数据集上的测试结果表明,AdaptiSent在精确率、召回率和F1分数方面优于现有的模型,尤其是在识别细微的模态间关系方面非常有效,这对于准确的情感和方面术语提取至关重要。这种有效性源于模型能够根据上下文的相关性动态调整其关注点,从而提高跨各种多模态数据集的情感分析的深度和准确性。AdaptiSent为MABSA设定了新的标准,显著优于当前的方法,尤其是在理解复杂的多模态信息方面。
🔬 方法详解
问题定义:多模态方面级情感分析(MABSA)旨在从包含文本和图像的多模态数据中,针对特定方面提取情感倾向。现有方法通常难以有效捕捉文本和图像之间复杂的交互关系,导致情感分析的准确性受限。它们可能无法根据上下文动态调整不同模态的重要性,也难以关注到与特定方面最相关的跨模态信息。
核心思路:AdaptiSent的核心思路是引入上下文感知的自适应注意力机制,使模型能够动态地学习不同模态的权重,并关注与特定方面最相关的跨模态信息。通过这种方式,模型可以更好地理解文本和图像之间的复杂交互关系,从而提高情感分析的准确性。
技术框架:AdaptiSent的整体框架包含以下主要模块:1) 文本和图像特征提取模块,用于提取文本和图像的初始特征表示;2) 动态模态权重模块,用于根据上下文动态地学习不同模态的权重;3) 上下文自适应注意力模块,用于关注与特定方面最相关的跨模态信息;4) 情感分类模块,用于预测特定方面的情感倾向。
关键创新:AdaptiSent的关键创新在于其上下文自适应注意力机制。该机制能够根据上下文动态地调整不同模态的权重,并关注与特定方面最相关的跨模态信息。与现有方法相比,AdaptiSent能够更好地理解文本和图像之间的复杂交互关系,从而提高情感分析的准确性。
关键设计:AdaptiSent的关键设计包括:1) 使用Transformer网络提取文本特征;2) 使用卷积神经网络(CNN)提取图像特征;3) 使用注意力机制学习动态模态权重;4) 使用多层感知机(MLP)进行情感分类。损失函数采用交叉熵损失函数,优化器采用Adam优化器。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

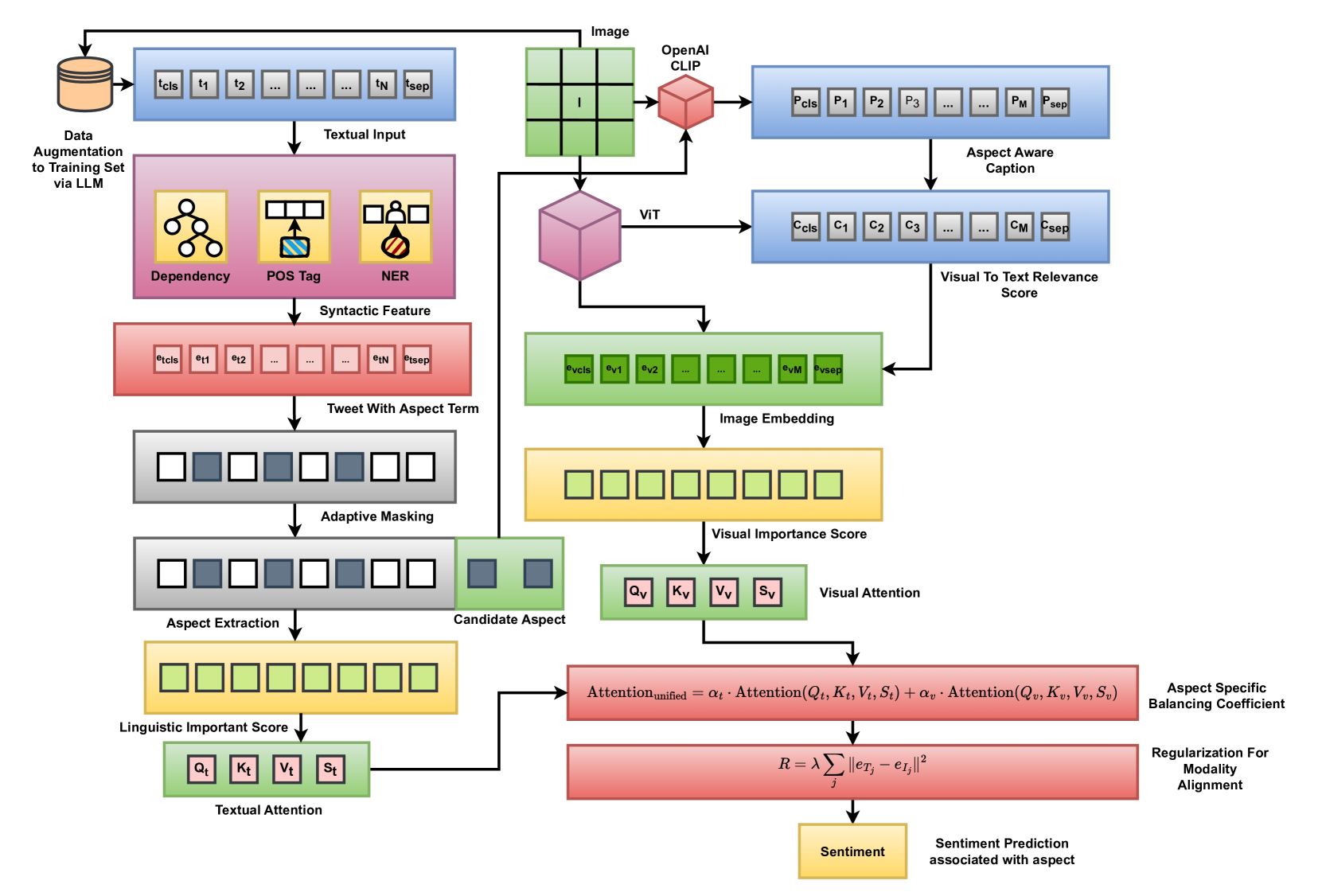

📊 实验亮点
AdaptiSent在标准Twitter数据集上进行了实验,结果表明,AdaptiSent在精确率、召回率和F1分数方面均优于现有的基线模型。例如,在某个数据集上,AdaptiSent的F1分数比最佳基线模型提高了超过3个百分点。实验结果表明,AdaptiSent能够有效地捕捉文本和图像之间的复杂交互关系,从而提高情感分析的准确性。
🎯 应用场景
AdaptiSent可应用于社交媒体情感分析、产品评论分析、舆情监控等领域。通过更准确地理解多模态数据中的情感倾向,可以帮助企业更好地了解用户需求,及时发现潜在风险,并做出更明智的决策。未来,该研究可以扩展到更多模态的数据,例如视频和音频,以实现更全面的情感分析。
📄 摘要(原文)
We introduce AdaptiSent, a new framework for Multimodal Aspect-Based Sentiment Analysis (MABSA) that uses adaptive cross-modal attention mechanisms to improve sentiment classification and aspect term extraction from both text and images. Our model integrates dynamic modality weighting and context-adaptive attention, enhancing the extraction of sentiment and aspect-related information by focusing on how textual cues and visual context interact. We tested our approach against several baselines, including traditional text-based models and other multimodal methods. Results from standard Twitter datasets show that AdaptiSent surpasses existing models in precision, recall, and F1 score, and is particularly effective in identifying nuanced inter-modal relationships that are crucial for accurate sentiment and aspect term extraction. This effectiveness comes from the model's ability to adjust its focus dynamically based on the context's relevance, improving the depth and accuracy of sentiment analysis across various multimodal data sets. AdaptiSent sets a new standard for MABSA, significantly outperforming current methods, especially in understanding complex multimodal information.