Advancing Retrieval-Augmented Generation for Structured Enterprise and Internal Data
作者: Chandana Cheerla
分类: cs.CL, cs.AI, cs.CE, cs.IR
发布日期: 2025-07-16
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种高级RAG框架,用于处理结构化企业内部数据,提升问答性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 结构化数据 企业数据 混合检索 元数据过滤 语义分块
📋 核心要点
- 现有RAG框架在处理企业内部的结构化和半结构化数据时存在困难,无法充分利用这些数据进行问答。
- 提出一种高级RAG框架,结合混合检索、元数据过滤、语义分块和表格结构保留,以提升检索和生成质量。
- 实验结果表明,该框架在准确性、完整性和相关性方面均优于传统方法,并在企业数据集上取得了显著的性能提升。
📝 摘要(中文)
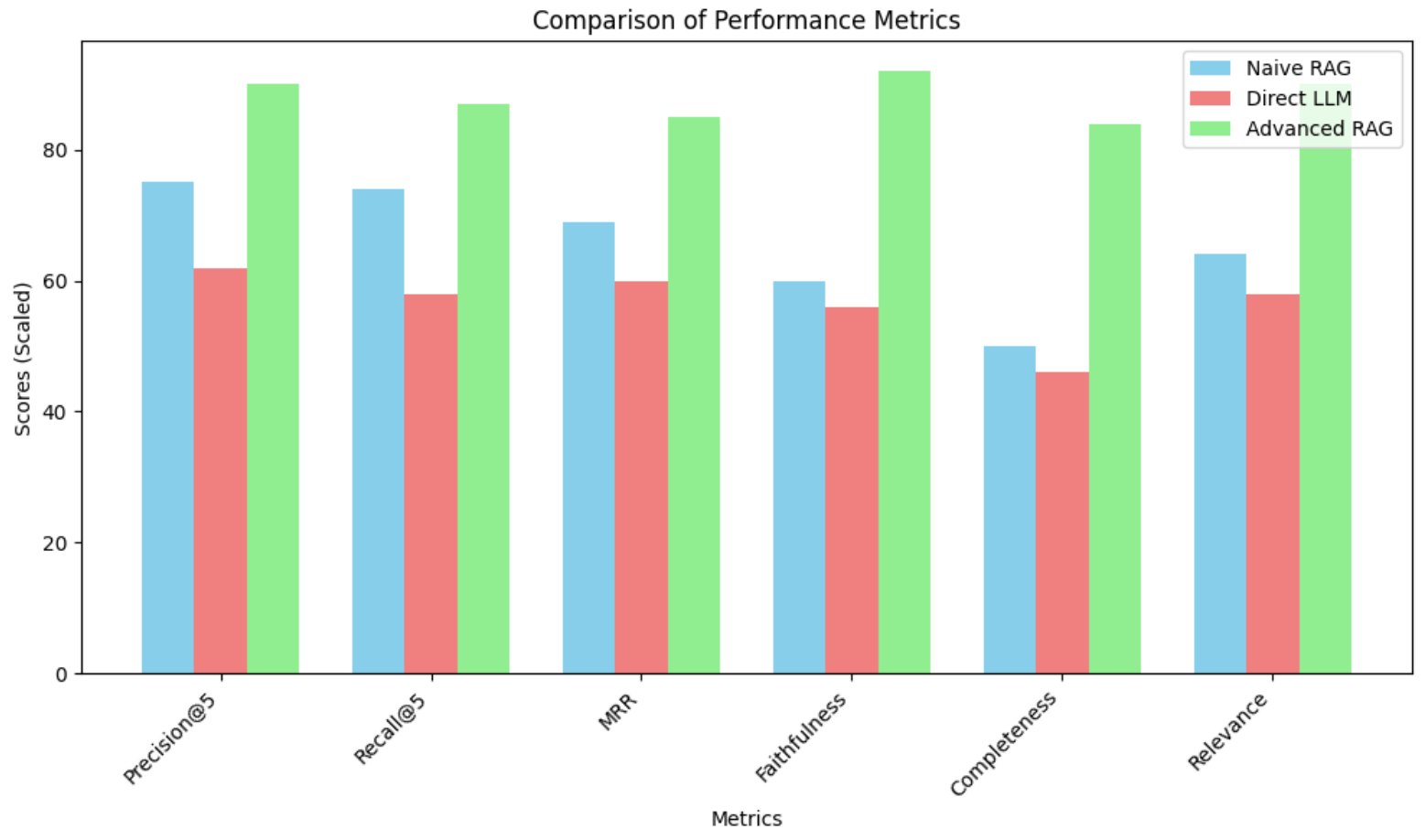
组织越来越多地依赖专有的企业数据(包括人力资源记录、结构化报告和表格文档)进行关键决策。大型语言模型(LLM)虽然具有强大的生成能力,但受到静态预训练、短上下文窗口以及处理异构数据格式的挑战的限制。传统的检索增强生成(RAG)框架解决了一些这些问题,但通常难以处理结构化和半结构化数据。本文提出了一种高级RAG框架,该框架结合了使用密集嵌入(all-mpnet-base-v2)和BM25的混合检索策略,并通过SpaCy NER的元数据感知过滤和交叉编码器重排序进行增强。该框架应用语义分块来保持文本连贯性,并保留表格数据结构以保持行-列完整性。量化索引优化了检索效率,而人机协作反馈和对话记忆提高了适应性。在企业数据集上的实验表明,性能有显著提高:Precision@5提高了15%(90 vs 75),Recall@5提高了13%(87 vs 74),Mean Reciprocal Rank提高了16%(0.85 vs 0.69)。定性评估显示,在5分制Likert量表上,Faithfulness(4.6 vs 3.0)、Completeness(4.2 vs 2.5)和Relevance(4.5 vs 3.2)的得分更高。这些结果证明了该框架在为企业任务提供准确、全面和上下文相关的响应方面的有效性。未来的工作包括扩展到多模态数据和集成基于代理的检索。
🔬 方法详解
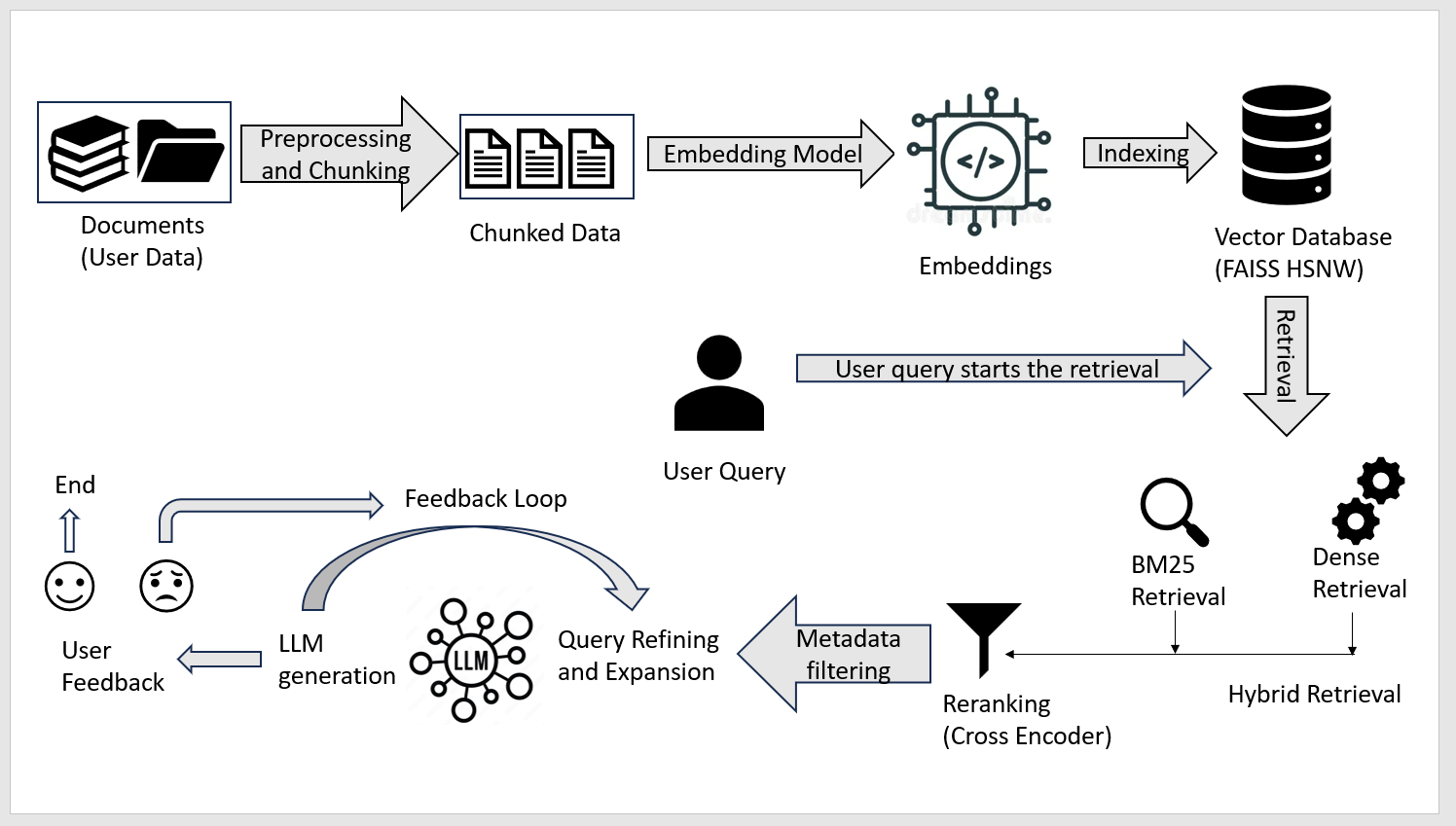
问题定义:论文旨在解决企业内部结构化和半结构化数据(如HR记录、报告、表格文档)的RAG问题。现有RAG方法难以有效处理这些数据,导致检索结果不准确、不完整,最终影响生成质量。痛点在于无法充分利用数据的结构化信息和元数据信息。
核心思路:论文的核心思路是结合多种检索策略,并针对结构化数据特点进行优化。通过混合检索提高召回率,利用元数据过滤提高精度,采用语义分块保持文本连贯性,并保留表格结构以保证数据的完整性。
技术框架:该框架包含以下主要模块:1) 混合检索:结合密集嵌入(all-mpnet-base-v2)和BM25进行检索,提高召回率。2) 元数据感知过滤:使用SpaCy NER提取实体,并根据元数据进行过滤,提高精度。3) 交叉编码器重排序:使用交叉编码器对检索结果进行重排序,进一步提高精度。4) 语义分块:将文本分割成语义相关的块,保持文本的连贯性。5) 表格结构保留:保留表格数据的行-列结构,避免信息丢失。6) 量化索引:优化检索效率。7) 人机协作反馈和对话记忆:提高框架的适应性。
关键创新:该框架的关键创新在于针对结构化企业数据,将混合检索、元数据过滤、语义分块和表格结构保留等技术有机结合,形成一个完整的RAG解决方案。与传统RAG方法相比,该框架能够更好地利用数据的结构化信息和元数据信息,从而提高检索和生成质量。
关键设计:论文中使用了预训练的密集嵌入模型all-mpnet-base-v2进行语义检索,并结合BM25进行互补。使用SpaCy NER进行实体识别,并根据实体类型进行元数据过滤。交叉编码器采用预训练模型进行微调,以提高重排序的准确性。语义分块的具体实现方式未知,但强调了保持文本连贯性的重要性。表格结构保留的具体实现方式也未知,但强调了保持行-列完整性的重要性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在企业数据集上取得了显著的性能提升。Precision@5提高了15%(90 vs 75),Recall@5提高了13%(87 vs 74),Mean Reciprocal Rank提高了16%(0.85 vs 0.69)。定性评估显示,Faithfulness、Completeness和Relevance等指标均有显著提升,证明了该框架的有效性。
🎯 应用场景
该研究成果可应用于企业内部知识库问答、智能客服、报告生成等场景。通过有效利用企业内部的结构化数据,可以提供更准确、更全面的信息服务,辅助决策,提高工作效率。未来可扩展到金融、医疗等领域,具有广泛的应用前景。
📄 摘要(原文)
Organizations increasingly rely on proprietary enterprise data, including HR records, structured reports, and tabular documents, for critical decision-making. While Large Language Models (LLMs) have strong generative capabilities, they are limited by static pretraining, short context windows, and challenges in processing heterogeneous data formats. Conventional Retrieval-Augmented Generation (RAG) frameworks address some of these gaps but often struggle with structured and semi-structured data. This work proposes an advanced RAG framework that combines hybrid retrieval strategies using dense embeddings (all-mpnet-base-v2) and BM25, enhanced by metadata-aware filtering with SpaCy NER and cross-encoder reranking. The framework applies semantic chunking to maintain textual coherence and retains tabular data structures to preserve row-column integrity. Quantized indexing optimizes retrieval efficiency, while human-in-the-loop feedback and conversation memory improve adaptability. Experiments on enterprise datasets show notable improvements: Precision@5 increased by 15 percent (90 versus 75), Recall@5 by 13 percent (87 versus 74), and Mean Reciprocal Rank by 16 percent (0.85 versus 0.69). Qualitative evaluations show higher scores in Faithfulness (4.6 versus 3.0), Completeness (4.2 versus 2.5), and Relevance (4.5 versus 3.2) on a 5-point Likert scale. These results demonstrate the framework's effectiveness in delivering accurate, comprehensive, and contextually relevant responses for enterprise tasks. Future work includes extending to multimodal data and integrating agent-based retrieval. The source code will be released at https://github.com/CheerlaChandana/Enterprise-Chatbot