Beyond Single Models: Enhancing LLM Detection of Ambiguity in Requests through Debate
作者: Ana Davila, Jacinto Colan, Yasuhisa Hasegawa
分类: cs.CL, cs.HC
发布日期: 2025-07-16
备注: Accepted at the 2025 SICE Festival with Annual Conference (SICE FES)
期刊: 2025 SICE Festival with Annual Conference (SICE FES)
💡 一句话要点
提出多代理辩论框架以增强LLM对请求歧义的检测能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 歧义检测 多代理系统 辩论机制 自然语言处理
📋 核心要点
- 现有大型语言模型在处理用户请求时,常常面临歧义问题,导致理解和响应的准确性不足。
- 本文提出了一种多代理辩论框架,通过引入多个LLM模型进行协作,增强了对请求歧义的检测和解决能力。
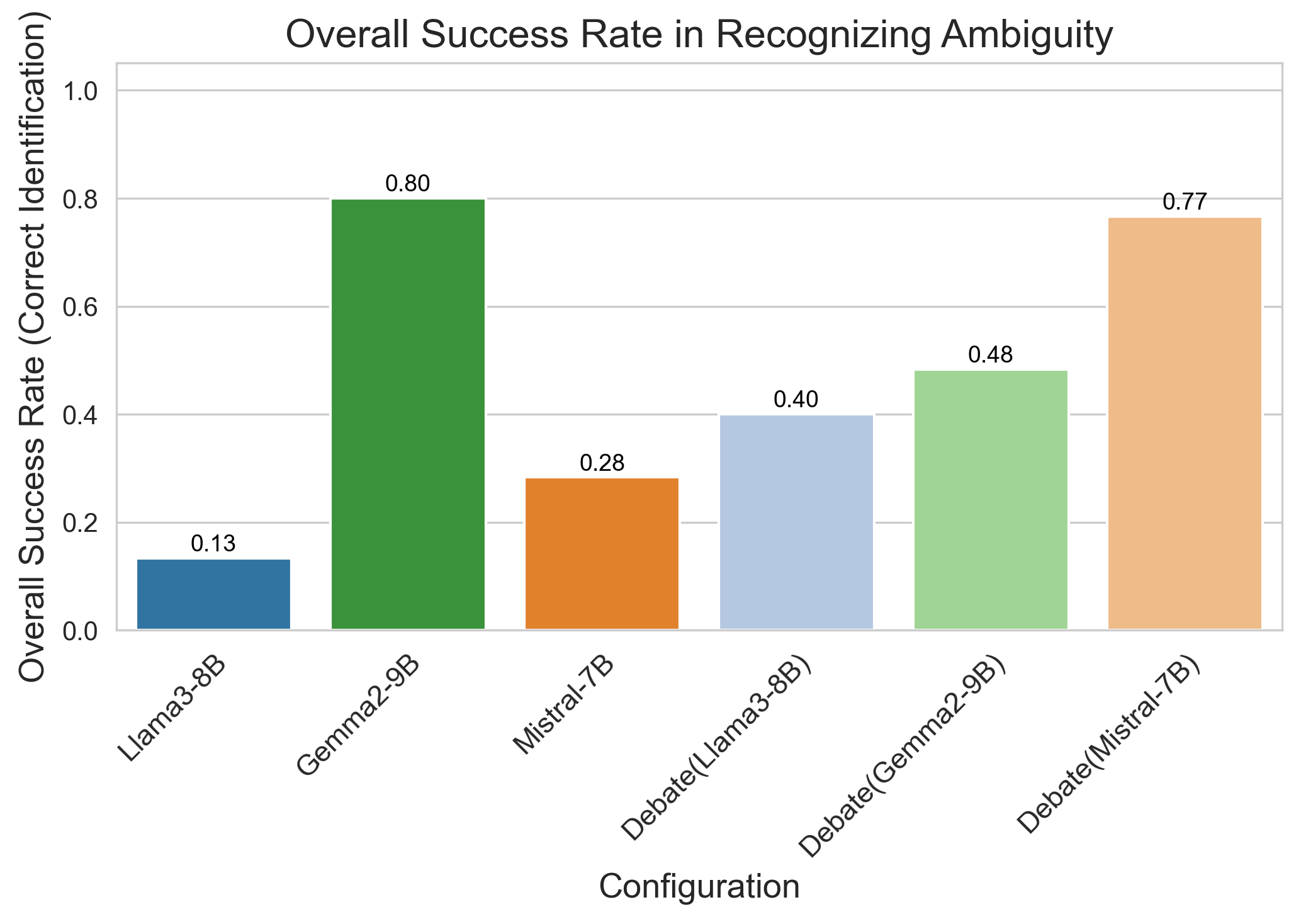
- 实验结果表明,辩论框架显著提高了Llama3-8B和Mistral-7B的性能,Mistral-7B主导的辩论成功率达到76.7%。
📝 摘要(中文)
大型语言模型(LLMs)在理解和生成自然语言方面表现出色,但在处理用户请求的歧义时面临挑战。为了解决这一问题,本文提出并评估了一种多代理辩论框架,旨在超越单一模型的能力。该框架由三种LLM架构(Llama3-8B、Gemma2-9B和Mistral-7B变体)和一个包含多样化歧义的数据集组成。实验结果显示,辩论框架显著提升了Llama3-8B和Mistral-7B变体的表现,Mistral-7B主导的辩论达到了76.7%的成功率,尤其在复杂歧义和高效共识方面表现突出。这些发现强调了辩论框架作为增强LLM能力的有效方法,为开发更强大和适应性强的语言理解系统提供了重要见解。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在处理用户请求时的歧义检测和理解能力不足的问题。现有方法通常依赖单一模型,难以有效处理复杂的歧义情况。
核心思路:通过引入多代理辩论框架,利用多个LLM模型之间的协作与竞争,提升对请求歧义的检测和解决能力。这种设计能够促进模型间的信息交流,从而提高整体性能。
技术框架:该框架包含三个主要的LLM架构(Llama3-8B、Gemma2-9B和Mistral-7B变体),并使用一个包含多样化歧义的数据集进行训练和评估。模型通过辩论的方式进行交互,形成共识。
关键创新:最重要的创新点在于引入了多代理辩论机制,使得多个模型能够在面对复杂歧义时进行有效的协作。这与传统的单一模型方法形成了鲜明对比,显著提升了理解能力。
关键设计:在模型训练中,采用了特定的损失函数以鼓励模型间的辩论和信息共享。参数设置方面,针对不同模型的特性进行了优化,以确保辩论过程的高效性和准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Mistral-7B主导的辩论达到了76.7%的成功率,显著高于各自的基线模型。这一提升尤其在处理复杂歧义和实现高效共识方面表现突出,验证了多代理辩论框架的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能客服系统、虚拟助手和人机交互界面等。通过增强LLM对请求歧义的理解能力,可以提升用户体验,减少误解和错误响应的发生,从而在实际应用中具有重要价值和影响。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated significant capabilities in understanding and generating human language, contributing to more natural interactions with complex systems. However, they face challenges such as ambiguity in user requests processed by LLMs. To address these challenges, this paper introduces and evaluates a multi-agent debate framework designed to enhance detection and resolution capabilities beyond single models. The framework consists of three LLM architectures (Llama3-8B, Gemma2-9B, and Mistral-7B variants) and a dataset with diverse ambiguities. The debate framework markedly enhanced the performance of Llama3-8B and Mistral-7B variants over their individual baselines, with Mistral-7B-led debates achieving a notable 76.7% success rate and proving particularly effective for complex ambiguities and efficient consensus. While acknowledging varying model responses to collaborative strategies, these findings underscore the debate framework's value as a targeted method for augmenting LLM capabilities. This work offers important insights for developing more robust and adaptive language understanding systems by showing how structured debates can lead to improved clarity in interactive systems.