Evaluating Speech-to-Text x LLM x Text-to-Speech Combinations for AI Interview Systems
作者: Rumi Allbert, Nima Yazdani, Ali Ansari, Aruj Mahajan, Amirhossein Afsharrad, Seyed Shahabeddin Mousavi
分类: eess.AS, cs.CL
发布日期: 2025-07-15 (更新: 2025-08-21)
💡 一句话要点
评估STT x LLM x TTS组合在AI面试系统中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音对话系统 大型语言模型 语音转文本 文本转语音 人机交互 自动评估 用户体验
📋 核心要点
- 现有语音对话AI系统依赖STT、LLM和TTS的级联,但缺乏系统性的性能评估和组件选择指导。
- 论文提出了一种基于LLM-as-a-Judge的自动评估框架,用于评估不同STT x LLM x TTS组合的对话质量。
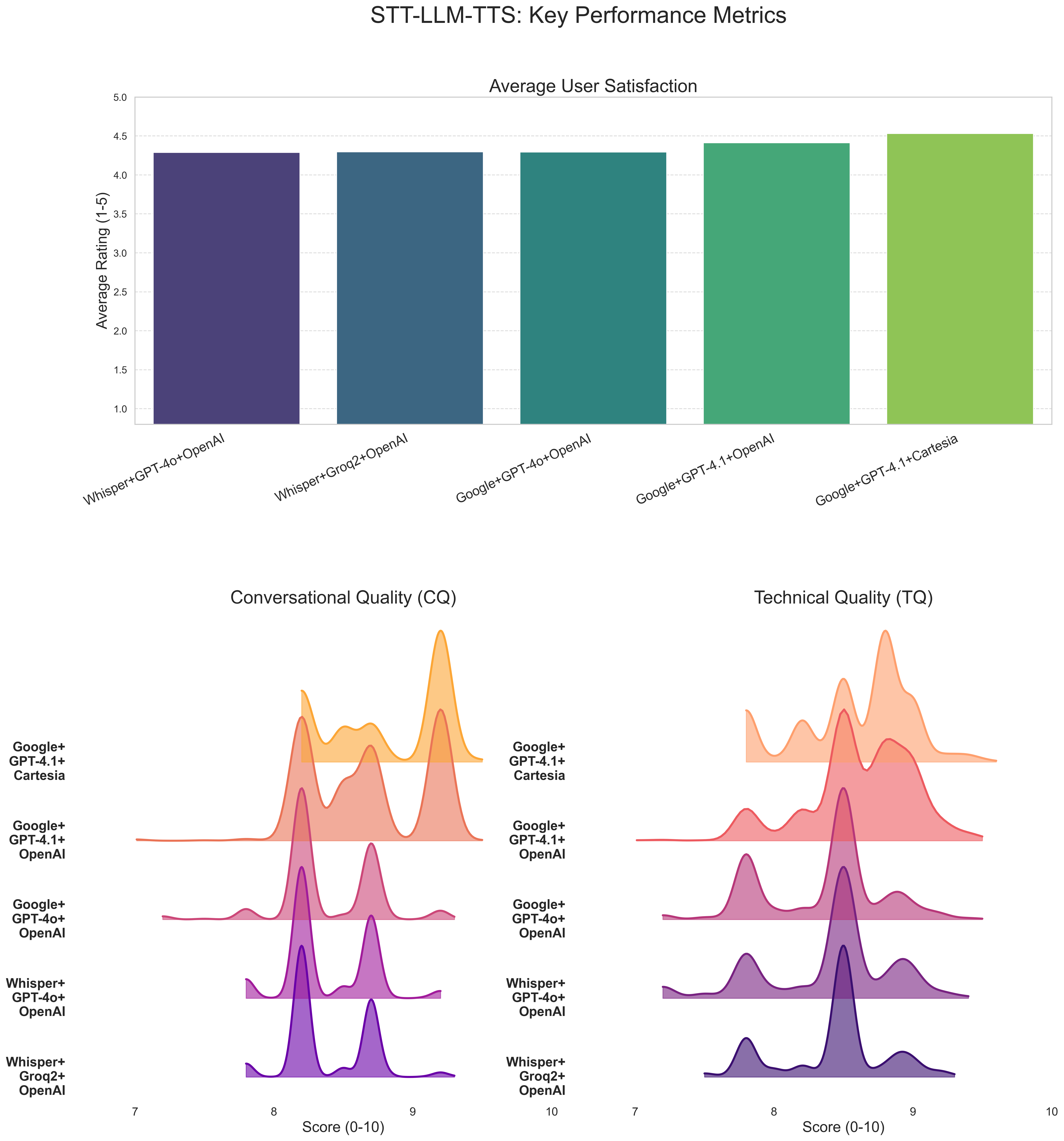
- 实验结果表明,Google STT、GPT-4.1和Cartesia TTS的组合在客观指标和用户满意度上表现最佳,但客观指标与用户满意度相关性弱。
📝 摘要(中文)
基于语音的对话式AI系统越来越多地依赖于级联架构,这些架构结合了语音转文本(STT)、大型语言模型(LLM)和文本转语音(TTS)组件。本文对STT x LLM x TTS堆栈进行了大规模的实证比较,使用的数据来自超过30万次AI进行的求职面试。我们使用LLM-as-a-Judge自动评估框架来评估对话质量、技术准确性和技能评估能力。对五个生产配置的分析表明,结合谷歌的STT、GPT-4.1和Cartesia的TTS的堆栈在客观质量指标和用户满意度得分方面均优于其他方案。令人惊讶的是,我们发现客观质量指标与用户满意度得分之间的相关性较弱,这表明基于语音的AI系统中的用户体验取决于技术性能之外的因素。我们的研究结果为多模态对话中组件的选择提供了实践指导,并为人机交互贡献了一种经过验证的评估方法。
🔬 方法详解
问题定义:论文旨在解决在语音对话AI系统中,如何选择最优的语音转文本(STT)、大型语言模型(LLM)和文本转语音(TTS)组件组合,以提升整体系统性能和用户体验的问题。现有方法缺乏大规模的、客观的评估框架,难以指导实际应用中的组件选择。
核心思路:论文的核心思路是构建一个基于LLM-as-a-Judge的自动评估框架,利用LLM强大的理解和推理能力,对不同STT x LLM x TTS组合生成的对话进行多维度评估,包括对话质量、技术准确性和技能评估能力。同时,结合用户满意度调查,分析客观指标与主观体验之间的关系。
技术框架:整体框架包含以下几个主要模块:1) 数据采集模块:从超过30万次AI面试中采样数据;2) STT模块:将语音转换为文本;3) LLM模块:处理文本输入,生成回复;4) TTS模块:将文本回复转换为语音;5) LLM-as-a-Judge评估模块:使用LLM对整个对话过程进行评估,输出客观质量指标;6) 用户满意度调查模块:收集用户对对话体验的主观评价。
关键创新:论文的关键创新在于:1) 构建了一个大规模的STT x LLM x TTS组合评估数据集;2) 提出了基于LLM-as-a-Judge的自动评估框架,该框架能够客观、高效地评估对话质量;3) 揭示了客观质量指标与用户满意度之间的弱相关性,强调了用户体验在语音对话AI系统中的重要性。
关键设计:LLM-as-a-Judge评估模块的设计是关键。具体而言,使用GPT-4.1作为评估者,并设计了详细的prompt,引导LLM从对话质量、技术准确性和技能评估能力三个维度进行评分。同时,采用了Likert量表来收集用户满意度数据,并使用统计方法分析客观指标与主观体验之间的关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Google STT、GPT-4.1和Cartesia TTS的组合在客观质量指标(对话质量、技术准确性和技能评估能力)和用户满意度得分方面均优于其他方案。但客观质量指标与用户满意度得分之间的相关性较弱,表明用户体验受多种因素影响,不仅仅是技术性能。
🎯 应用场景
该研究成果可应用于各种语音对话AI系统,如智能客服、虚拟助手、在线教育等。通过选择最优的STT、LLM和TTS组件组合,可以显著提升系统性能和用户体验,提高工作效率和服务质量。未来,该研究方法可扩展到其他多模态对话系统,为人机交互提供更智能、更自然的解决方案。
📄 摘要(原文)
Voice-based conversational AI systems increasingly rely on cascaded architectures that combine speech-to-text (STT), large language models (LLMs), and text-to-speech (TTS) components. We present a large-scale empirical comparison of STT x LLM x TTS stacks using data sampled from over 300,000 AI-conducted job interviews. We used an LLM-as-a-Judge automated evaluation framework to assess conversational quality, technical accuracy, and skill assessment capabilities. Our analysis of five production configurations reveals that a stack combining Google's STT, GPT-4.1, and Cartesia's TTS outperforms alternatives in both objective quality metrics and user satisfaction scores. Surprisingly, we find that objective quality metrics correlate weakly with user satisfaction scores, suggesting that user experience in voice-based AI systems depends on factors beyond technical performance. Our findings provide practical guidance for selecting components in multimodal conversations and contribute a validated evaluation methodology for human-AI interactions.