ExpliCIT-QA: Explainable Code-Based Image Table Question Answering
作者: Maximiliano Hormazábal Lagos, Álvaro Bueno Sáez, Pedro Alonso Doval, Jorge Alcalde Vesteiro, Héctor Cerezo-Costas
分类: cs.CL, cs.AI
发布日期: 2025-07-15
备注: This work has been accepted for presentation at the 24nd Portuguese Conference on Artificial Intelligence (EPIA 2025) and will be published in the proceedings by Springer in the Lecture Notes in Computer Science (LNCS) series. Please cite the published version when available
💡 一句话要点
提出ExplicIT-QA,解决图像表格问答的可解释性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像表格问答 可解释性 多模态学习 代码生成 思维链 TableVQA 自然语言解释
📋 核心要点
- 现有端到端TableVQA系统缺乏可解释性,难以追溯答案来源,限制了其在敏感领域的应用。
- ExplicIT-QA通过模块化设计,将问题分解为多步推理,并生成自然语言解释和可执行代码,提升透明度。
- 在TableVQA-Bench基准测试中,ExplicIT-QA展示了在可解释性和透明度方面的改进,为实际应用奠定基础。
📝 摘要(中文)
本文提出ExplicIT-QA,一个多模态流水线系统,扩展了我们之前用于表格问答的MRT方法,使其能够处理复杂的表格图像并提供可解释的答案。ExplicIT-QA采用模块化设计,包含:(1)多模态表格理解,使用思维链方法从表格图像中提取和转换内容;(2)基于语言的推理,生成自然语言的逐步解释来解决问题;(3)自动代码生成,基于推理步骤创建Python/Pandas脚本,并提供错误处理反馈;(4)代码执行,计算最终答案;(5)自然语言解释,描述答案的计算方式。该系统旨在提高透明度和可审计性:所有中间输出,包括解析的表格、推理步骤、生成的代码和最终答案,都可供检查。这种策略致力于弥合端到端TableVQA系统中的可解释性差距。我们在TableVQA-Bench基准上评估了ExplicIT-QA,并将其与现有基线进行了比较。结果表明,该系统在可解释性和透明度方面有所改进,为金融和医疗保健等需要审计结果的敏感领域的应用打开了大门。
🔬 方法详解
问题定义:论文旨在解决图像表格问答(TableVQA)领域中,现有端到端系统缺乏可解释性的问题。现有方法通常直接将图像和问题输入模型,输出答案,但中间过程不可见,难以理解模型做出决策的原因。这限制了TableVQA在金融、医疗等需要严格审计的领域的应用。
核心思路:ExplicIT-QA的核心思路是将复杂的TableVQA问题分解为一系列可解释的步骤,包括表格理解、语言推理、代码生成、代码执行和自然语言解释。通过显式地展示每个步骤的中间结果,例如解析后的表格、推理步骤、生成的代码等,提高系统的透明度和可审计性。
技术框架:ExplicIT-QA采用模块化流水线设计,主要包含以下五个模块: 1. 多模态表格理解:使用Chain-of-Thought方法从表格图像中提取和转换内容。 2. 语言推理:生成自然语言的逐步解释来解决问题。 3. 自动代码生成:基于推理步骤创建Python/Pandas脚本,并提供错误处理反馈。 4. 代码执行:执行生成的代码,计算最终答案。 5. 自然语言解释:描述答案的计算方式。 每个模块的输出都可供检查,从而实现端到端的可追溯性。
关键创新:ExplicIT-QA的关键创新在于其显式的、基于代码的推理过程。与传统的端到端模型不同,ExplicIT-QA不是直接预测答案,而是生成可执行的Python/Pandas代码来计算答案。这种方法不仅提高了可解释性,还允许系统利用现有的数据处理工具和库,从而提高了准确性和鲁棒性。
关键设计:论文中没有详细描述具体的参数设置、损失函数、网络结构等技术细节。但从整体框架来看,关键设计在于模块化的结构和基于代码的推理方式。具体实现细节可能依赖于各个模块所采用的具体技术,例如,多模态表格理解模块可能使用OCR和视觉Transformer等技术,语言推理模块可能使用大型语言模型等。
🖼️ 关键图片
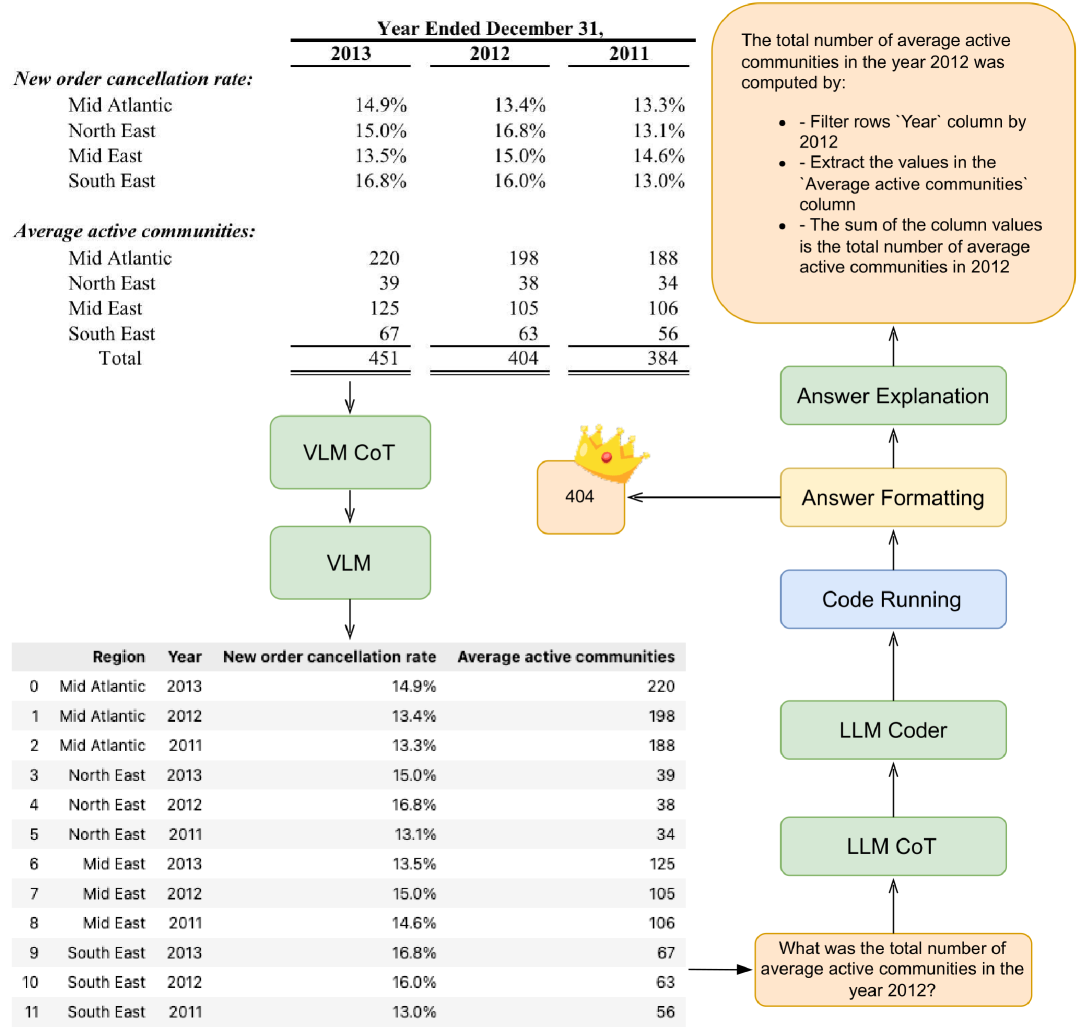
📊 实验亮点
论文在TableVQA-Bench基准测试中评估了ExplicIT-QA,并与现有基线进行了比较。结果表明,ExplicIT-QA在可解释性和透明度方面有所改进。虽然论文没有给出具体的性能数据,但强调了ExplicIT-QA在提升模型可解释性方面的优势,这对于实际应用至关重要。
🎯 应用场景
ExplicIT-QA具有广泛的应用前景,尤其是在金融、医疗保健等需要高度可信和可审计的领域。例如,在金融领域,该系统可以用于自动分析财务报表,并解释其分析结果,帮助投资者做出更明智的决策。在医疗保健领域,该系统可以用于分析医学图像中的表格数据,并解释其诊断结果,辅助医生进行诊断。
📄 摘要(原文)
We present ExpliCIT-QA, a system that extends our previous MRT approach for tabular question answering into a multimodal pipeline capable of handling complex table images and providing explainable answers. ExpliCIT-QA follows a modular design, consisting of: (1) Multimodal Table Understanding, which uses a Chain-of-Thought approach to extract and transform content from table images; (2) Language-based Reasoning, where a step-by-step explanation in natural language is generated to solve the problem; (3) Automatic Code Generation, where Python/Pandas scripts are created based on the reasoning steps, with feedback for handling errors; (4) Code Execution to compute the final answer; and (5) Natural Language Explanation that describes how the answer was computed. The system is built for transparency and auditability: all intermediate outputs, parsed tables, reasoning steps, generated code, and final answers are available for inspection. This strategy works towards closing the explainability gap in end-to-end TableVQA systems. We evaluated ExpliCIT-QA on the TableVQA-Bench benchmark, comparing it with existing baselines. We demonstrated improvements in interpretability and transparency, which open the door for applications in sensitive domains like finance and healthcare where auditing results are critical.