MetaLint: Generalizable Idiomatic Code Quality Analysis through Instruction-Following and Easy-to-Hard Generalization
作者: Atharva Naik, Lawanya Baghel, Dhakshin Govindarajan, Darsh Agrawal, Daniel Fried, Carolyn Rose
分类: cs.SE, cs.CL, cs.LG
发布日期: 2025-07-15 (更新: 2025-09-28)
💡 一句话要点
MetaLint:通过指令跟随和由易到难泛化实现通用代码质量分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码质量分析 指令跟随 大型语言模型 泛化能力 代码规范
📋 核心要点
- 现有代码质量分析模型依赖静态数据,难以适应代码规范的演变和新的编程习惯。
- MetaLint通过指令跟随和由易到难的泛化,使模型能够适应新的或复杂的代码模式,无需重新训练。
- 实验表明,MetaLint训练的模型在检测和定位代码问题方面表现出色,尤其是在处理未见过的代码习惯用法时。
📝 摘要(中文)
大型语言模型在代码生成方面表现出色,但在代码质量分析方面面临挑战,因为它们受限于静态训练数据,难以适应不断发展的最佳实践。我们提出了MetaLint,一个指令跟随框架,将代码质量分析定义为基于高级规范检测和修复有问题的语义代码片段或代码习惯用法的任务。与在静态代码质量约定上训练模型的传统方法不同,MetaLint采用在具有动态约定的合成linter生成数据上进行指令调优,以支持由易到难的泛化,使模型无需重新训练即可适应新的或复杂的代码模式。为了评估这一点,我们构建了一个具有挑战性的习惯用法基准,该基准受到Python增强提案(PEP)等真实编码标准的启发,并评估MetaLint训练的模型是否具有适应性推理或仅仅是记忆。结果表明,MetaLint训练提高了对未见过的习惯用法的泛化能力。Qwen3-4B在手动策划且具有挑战性的PEP习惯用法检测基准上获得了70.37%的F1分数,在所有评估模型中实现了最高的召回率(70.43%)。对于定位,它达到了26.73%,对于其4B参数规模来说是一个强有力的结果,并且与更大的最先进模型(如o3-mini)相当,突出了其在面向未来的代码质量分析方面的潜力。此外,MetaLint训练实现了跨模型系列、模型规模、来自不同linter的合成数据和Java习惯用法的习惯用法检测的泛化,证明了我们方法的普遍适用性。我们计划发布我们的代码和数据,以实现可重复性和进一步的工作。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码质量分析中泛化能力不足的问题。现有方法通常在静态的代码质量约定上进行训练,无法适应不断发展的编程规范和新的代码模式,导致在实际应用中表现不佳。
核心思路:MetaLint的核心思路是将代码质量分析任务转化为一个指令跟随问题,通过在动态生成的、具有不同代码质量约定的合成数据上进行训练,提高模型的泛化能力。这种方法允许模型学习从高级规范中识别和修复代码中的问题,而无需依赖于预定义的规则。
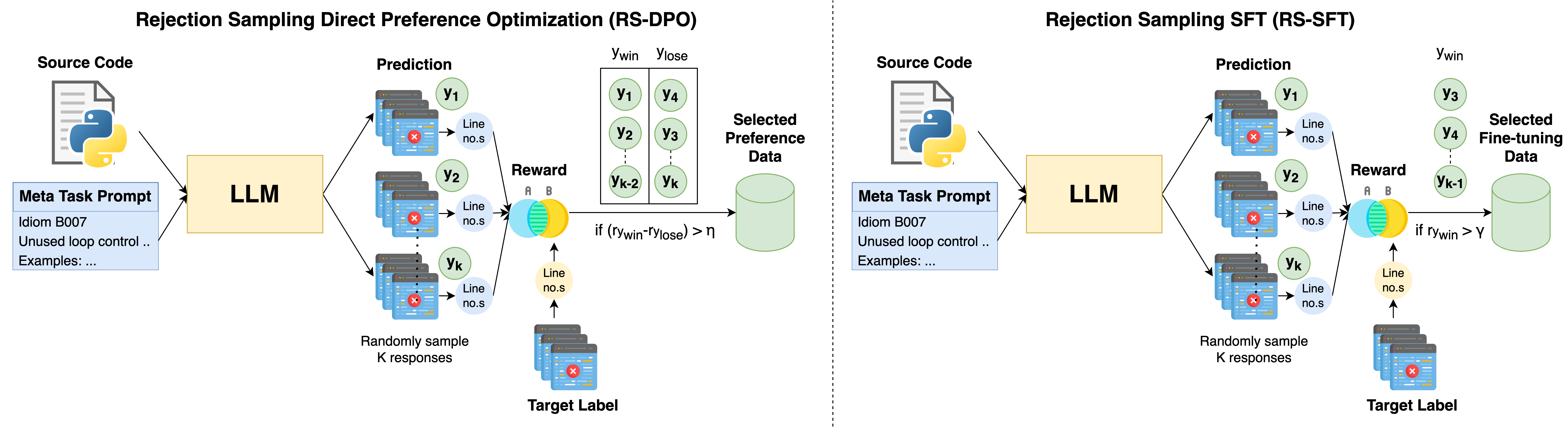
技术框架:MetaLint框架主要包含以下几个阶段:1) 使用代码linter生成带有不同代码质量约定的合成数据;2) 使用这些数据对大型语言模型进行指令调优,使其能够理解和遵循代码质量规范;3) 在真实的、具有挑战性的代码质量分析基准上评估模型的性能。框架的核心是指令调优过程,它使模型能够学习从高级规范中识别和修复代码中的问题。
关键创新:MetaLint的关键创新在于其使用合成数据进行指令调优,并采用由易到难的泛化策略。与传统的在静态数据上训练模型的方法不同,MetaLint能够适应新的或复杂的代码模式,而无需重新训练。此外,MetaLint还能够跨模型系列、模型规模和编程语言进行泛化,证明了其通用性。
关键设计:MetaLint的关键设计包括:1) 使用多种代码linter生成多样化的合成数据;2) 设计有效的指令模板,使模型能够理解代码质量规范;3) 采用由易到难的训练策略,逐步增加训练数据的难度;4) 使用F1分数、召回率和定位准确率等指标评估模型的性能。
🖼️ 关键图片


📊 实验亮点
MetaLint在PEP习惯用法检测基准上取得了显著成果,Qwen3-4B模型达到了70.37%的F1分数和70.43%的召回率,超过了其他评估模型。在代码定位方面,MetaLint也取得了26.73%的准确率,与更大的模型相当,证明了其在代码质量分析方面的潜力。
🎯 应用场景
MetaLint可应用于自动化代码审查、代码质量控制、软件开发工具和教育等领域。它可以帮助开发者提高代码质量,减少错误,并遵循最新的编程规范。此外,MetaLint还可以用于教育领域,帮助学生学习和掌握良好的编程习惯。
📄 摘要(原文)
Large Language Models, though successful in code generation, struggle with code quality analysis because they are limited by static training data and can't easily adapt to evolving best practices. We introduce MetaLint, an instruction-following framework that formulates code quality analysis as the task of detecting and fixing problematic semantic code fragments or code idioms based on high-level specifications. Unlike conventional approaches that train models on static code quality conventions, MetaLint employs instruction tuning on synthetic linter-generated data with dynamic conventions to support easy-to-hard generalization, enabling models to adapt to novel or complex code patterns without retraining. To evaluate this, we construct a benchmark of challenging idioms inspired by real-world coding standards such as Python Enhancement Proposals (PEPs) and assess whether MetaLint-trained models reason adaptively or simply memorize. Our results show that MetaLint training improves generalization to unseen idioms. Qwen3-4B attains a 70.37% F-score on a manually curated and challenging PEP idiom detection benchmark, achieving the highest recall (70.43%) among all evaluated models. For localization, it reaches 26.73%, which is a strong outcome for its 4B parameter size and comparable to larger state-of-the-art models such as o3-mini, highlighting its potential for future-proof code quality analysis. Furthermore, MetaLint training enables generalization in idiom detection across model families, model scales, synthetic data from diverse linters, and Java idioms, demonstrating the general applicability of our approach. We plan to release our code and data to enable reproducibility and further work.