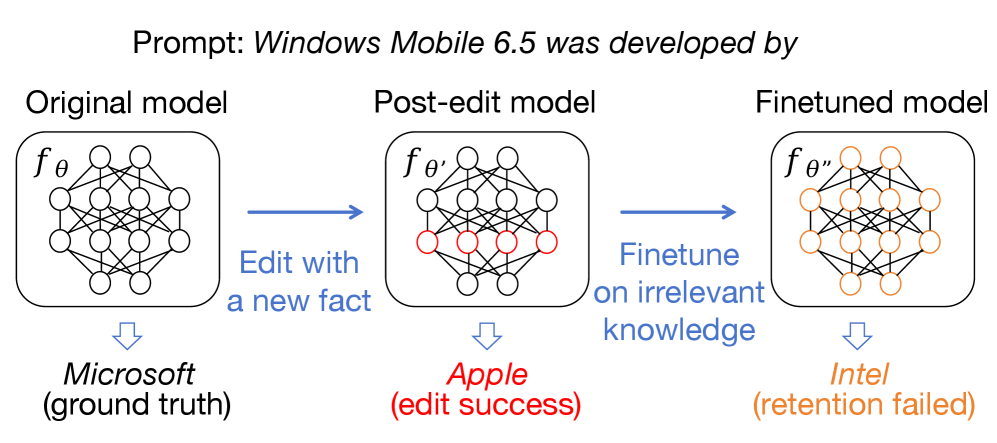
Retention analysis of edited knowledge after fine-tuning
作者: Fufang Wen, Shichang Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-14 (更新: 2025-10-24)
💡 一句话要点
研究微调对编辑后知识的遗忘效应,并提出增强知识保留的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识编辑 微调 知识保留 遗忘效应
📋 核心要点
- 现有模型编辑方法在更新LLM知识方面有效,但缺乏对微调后知识遗忘问题的深入研究。
- 该研究的核心在于分析微调对已编辑知识的影响,并探索提高知识保留率的方法。
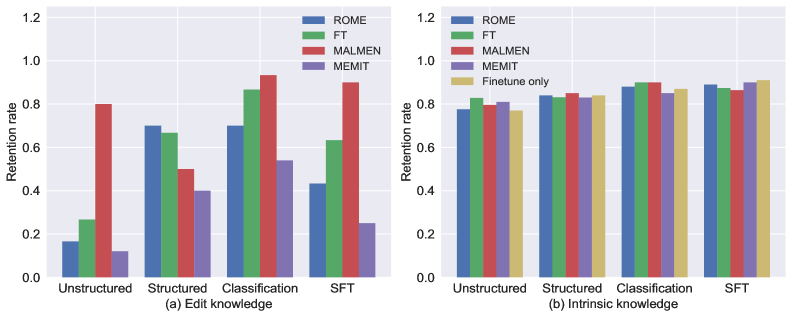
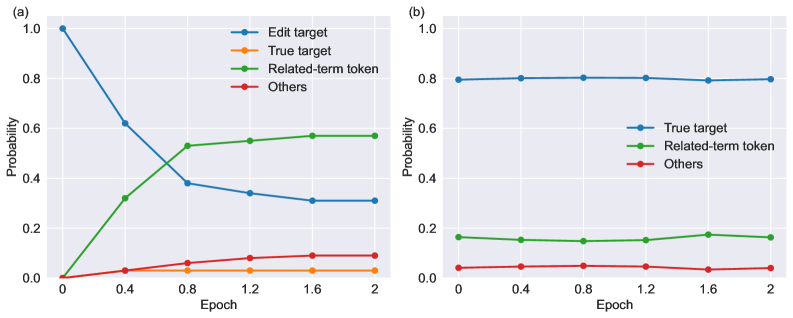
- 实验表明,编辑后的知识比预训练知识更容易在微调中被遗忘,但可以通过释义增强或冻结相关层来改善。
📝 摘要(中文)
大型语言模型(LLM)存储了海量知识,这些知识通常需要更新以纠正事实错误、整合新信息或调整模型行为。模型编辑方法作为一种高效的解决方案应运而生,它以远低于持续训练的计算成本,实现了局部和精确的知识修改。与此同时,LLM经常被微调以适应各种下游任务。然而,微调对先前编辑过的知识的影响仍然知之甚少。本文系统地研究了不同的微调目标如何与各种模型编辑技术相互作用。研究结果表明,与通过预训练获得的内在知识相比,编辑过的知识在微调过程中更容易被遗忘。该分析突出了当前编辑方法的一个关键局限性,并表明在实际部署中,评估下游微调下的编辑鲁棒性至关重要。我们进一步发现,通过用释义增强编辑知识或在微调阶段冻结与编辑内容相关的层,可以显著提高知识保留率,这为开发更强大的编辑算法提供了见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在经过知识编辑后,再进行下游任务微调时,已编辑知识容易被遗忘的问题。现有的模型编辑方法虽然能够高效地修改LLM中的知识,但缺乏对微调过程对已编辑知识稳定性的考量,导致编辑后的知识在微调后可能失效。
核心思路:论文的核心思路是系统性地研究不同微调目标与各种模型编辑技术之间的相互作用,从而揭示微调对已编辑知识的影响。通过实验分析,发现编辑后的知识比预训练获得的知识更容易在微调过程中被遗忘。为了解决这个问题,论文提出了两种增强知识保留的方法:一是通过用释义增强编辑知识,二是在微调阶段冻结与编辑内容相关的层。
技术框架:论文的技术框架主要包括三个部分:首先,选择合适的LLM和模型编辑方法;其次,设计不同的微调任务和目标;最后,评估微调后已编辑知识的保留情况。具体流程为:(1) 使用模型编辑方法对LLM进行知识编辑;(2) 使用不同的微调目标对编辑后的LLM进行微调;(3) 评估微调后LLM对已编辑知识的保留程度,并与未微调的模型进行比较;(4) 尝试使用释义增强和层冻结等方法来提高知识保留率。
关键创新:论文的关键创新在于:(1) 首次系统性地研究了微调对已编辑知识的影响,揭示了编辑后的知识更容易被遗忘的问题;(2) 提出了两种简单有效的增强知识保留的方法:释义增强和层冻结。与现有方法相比,该研究更关注微调过程对已编辑知识稳定性的影响,并提出了相应的解决方案。
关键设计:在实验设计方面,论文考虑了不同的模型编辑方法(如Knowledge Editor, MEMIT等)和微调目标(如分类、生成等)。在释义增强方面,论文使用了不同的释义生成策略,例如回译、同义词替换等。在层冻结方面,论文尝试了冻结不同层数的参数,并评估其对知识保留率的影响。损失函数方面,主要使用交叉熵损失函数进行微调。
🖼️ 关键图片
📊 实验亮点
实验结果表明,编辑后的知识在微调后更容易被遗忘。例如,在某些微调任务中,知识保留率下降了20%以上。然而,通过使用释义增强或冻结相关层,可以将知识保留率提高10%-15%。这些结果表明,论文提出的方法可以有效提高编辑后知识的鲁棒性。
🎯 应用场景
该研究成果可应用于需要频繁更新知识的LLM应用场景,例如问答系统、对话机器人等。通过提高编辑后知识的保留率,可以减少模型在微调后出现知识回退或错误回答的情况,从而提升用户体验和模型的可靠性。此外,该研究也为开发更鲁棒的模型编辑算法提供了新的思路。
📄 摘要(原文)
Large language models (LLMs) store vast amounts of knowledge, which often requires updates to correct factual errors, incorporate newly acquired information, or adapt model behavior. Model editing methods have emerged as efficient solutions for such updates, offering localized and precise knowledge modification at significantly lower computational cost than continual training. In parallel, LLMs are frequently fine-tuned for a wide range of downstream tasks. However, the effect of fine-tuning on previously edited knowledge remains poorly understood. In this work, we systematically investigate how different fine-tuning objectives interact with various model editing techniques. Our findings show that edited knowledge is substantially more susceptible to forgetting during fine-tuning than intrinsic knowledge acquired through pre-training. This analysis highlights a key limitation of current editing approaches and suggests that evaluating edit robustness under downstream fine-tuning is critical for their practical deployment. We further find that knowledge retention can be significantly improved by either augmenting edit knowledge with paraphrases or by freezing layers associated with edited content in fine-tuning stage, offering insight for developing more robust editing algorithms.