MultiVox: A Benchmark for Evaluating Voice Assistants for Multimodal Interactions
作者: Ramaneswaran Selvakumar, Ashish Seth, Nishit Anand, Utkarsh Tyagi, Sonal Kumar, Sreyan Ghosh, Dinesh Manocha
分类: cs.MM, cs.CL, cs.HC
发布日期: 2025-07-14 (更新: 2025-09-25)
💡 一句话要点
MultiVox:用于评估多模态交互语音助手的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音助手 多模态交互 基准测试 副语言特征 视觉线索
📋 核心要点
- 现有语音助手评估基准缺乏对细粒度语音特征和环境声学背景的理解能力,无法全面评估多模态交互。
- MultiVox基准旨在通过整合口语和视觉线索,特别是副语言语音特征,来评估语音助手的多模态理解能力。
- 对10个先进模型的评估表明,现有模型在生成上下文相关的响应方面存在困难,与人类的表现差距明显。
📝 摘要(中文)
大型语言模型(LLM)的快速发展使全能模型能够作为语音助手,理解口语对话。这些模型可以处理文本以外的多模态输入,如语音和视觉数据,从而实现更具上下文感知能力的交互。然而,目前的基准测试未能全面评估这些模型生成上下文感知响应的能力,尤其是在隐式理解细粒度的语音特征(如音高、情感、音色和音量)或环境声学背景(如背景声音)方面。此外,它们未能充分评估模型将副语言线索与互补视觉信号对齐以告知其响应的能力。为了解决这些差距,我们推出了 MultiVox,这是第一个旨在评估语音助手整合口语和视觉线索(包括副语言语音特征)以实现真正多模态理解的全能语音助手基准。具体来说,MultiVox 包括 1000 个人工标注和录制的语音对话,涵盖不同的副语言特征和一系列视觉线索,如图像和视频。我们对 10 个最先进模型的评估表明,尽管人类擅长这些任务,但当前模型始终难以产生上下文相关的响应。
🔬 方法详解
问题定义:现有语音助手评估基准无法充分评估模型对语音中细微情感、音调等副语言信息的理解,以及对环境声音的感知能力。此外,现有基准也缺乏对语音和视觉信息融合能力的有效评估,导致模型在多模态交互场景下的表现不佳。
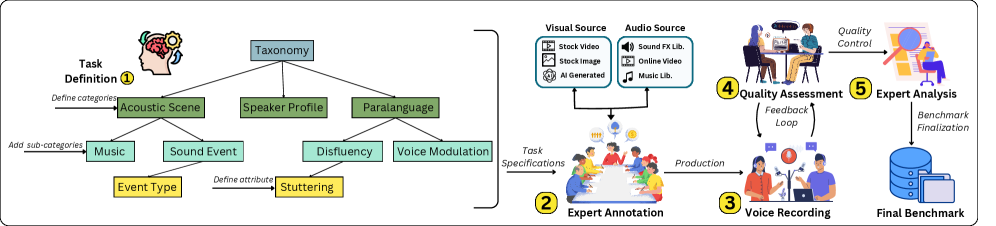
核心思路:MultiVox的核心思路是构建一个包含丰富副语言特征和多样视觉线索的数据集,用于全面评估语音助手在多模态环境下的理解和响应能力。通过引入人工标注的语音对话和相应的视觉信息,MultiVox能够更真实地模拟实际应用场景,从而更准确地评估模型的性能。
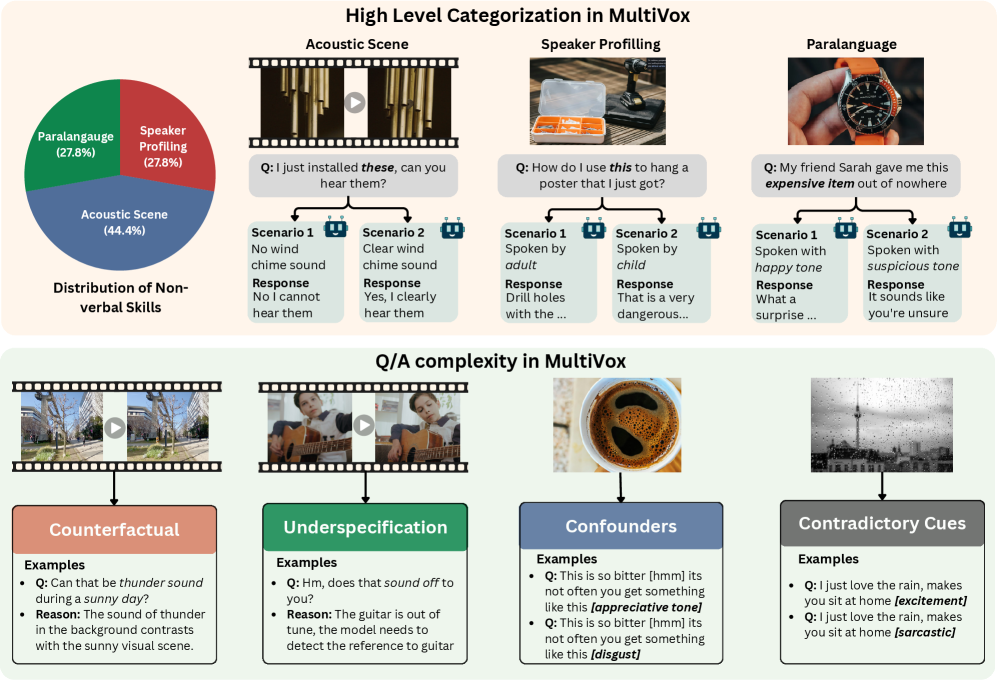
技术框架:MultiVox基准包含1000个人工标注和录制的语音对话,每个对话都包含丰富的副语言特征(如音高、情感、音色和音量)以及相关的视觉线索(如图像和视频)。评估过程包括将语音和视觉信息输入到语音助手模型中,然后评估模型生成的响应是否与上下文一致,并能够正确理解和利用副语言信息和视觉线索。
关键创新:MultiVox的关键创新在于其对副语言信息的关注和对多模态融合能力的评估。与现有基准相比,MultiVox更注重评估模型对语音中细微情感和语气的理解,以及模型将语音和视觉信息融合以生成更自然和上下文相关的响应的能力。
关键设计:MultiVox数据集的设计考虑了多种因素,包括副语言特征的多样性、视觉线索的相关性以及对话场景的真实性。数据集中的语音对话由人工录制,并经过专业标注,以确保数据的质量和准确性。视觉线索包括图像和视频,涵盖了各种场景和对象,以增加评估的全面性。
🖼️ 关键图片

📊 实验亮点
对10个最先进模型的评估结果显示,这些模型在MultiVox基准上的表现与人类存在显著差距,表明现有模型在理解和利用副语言信息以及融合多模态信息方面仍有很大的提升空间。例如,模型在识别语音中的情感和理解视觉场景中的上下文信息方面表现不佳,导致生成的响应与实际情况不符。
🎯 应用场景
MultiVox基准的推出将促进语音助手在多模态交互方面的研究和发展。它可以应用于开发更智能、更自然的语音助手,这些助手能够更好地理解人类的情感和意图,并能够根据环境和视觉信息做出更合适的响应。这将在智能家居、车载系统、教育和医疗等领域具有广泛的应用前景。
📄 摘要(原文)
The rapid progress of Large Language Models (LLMs) has empowered omni models to act as voice assistants capable of understanding spoken dialogues. These models can process multimodal inputs beyond text, such as speech and visual data, enabling more context-aware interactions. However, current benchmarks fall short in comprehensively evaluating how well these models generate context-aware responses, particularly when it comes to implicitly understanding fine-grained speech characteristics, such as pitch, emotion, timbre, and volume or the environmental acoustic context such as background sounds. Additionally, they inadequately assess the ability of models to align paralinguistic cues with complementary visual signals to inform their responses. To address these gaps, we introduce MultiVox, the first omni voice assistant benchmark designed to evaluate the ability of voice assistants to integrate spoken and visual cues including paralinguistic speech features for truly multimodal understanding. Specifically, MultiVox includes 1000 human-annotated and recorded speech dialogues that encompass diverse paralinguistic features and a range of visual cues such as images and videos. Our evaluation on 10 state-of-the-art models reveals that, although humans excel at these tasks, current models consistently struggle to produce contextually grounded responses.