From Words to Proverbs: Evaluating LLMs Linguistic and Cultural Competence in Saudi Dialects with Absher
作者: Renad Al-Monef, Hassan Alhuzali, Nora Alturayeif, Ashwag Alasmari
分类: cs.CL, cs.AI
发布日期: 2025-07-14 (更新: 2025-12-21)
💡 一句话要点
提出Absher基准,评估LLM在沙特方言中的语言和文化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 沙特方言 文化理解 评估基准 阿拉伯语NLP
📋 核心要点
- 现有LLM在处理沙特阿拉伯等语言文化多样性地区的方言和文化细微差别方面存在不足。
- 论文提出Absher基准,包含18000+多选题,覆盖沙特主要方言的语言和文化理解。
- 实验结果表明,现有LLM在文化推断和语境理解方面存在明显差距,需加强方言感知训练。
📝 摘要(中文)
随着大型语言模型(LLMs)在阿拉伯语自然语言处理应用中变得越来越重要,评估它们对区域方言和文化细微差别的理解至关重要,尤其是在像沙特阿拉伯这样语言多样化的环境中。本文介绍Absher,这是一个综合基准,专门用于评估LLMs在主要沙特方言中的性能。Absher包含超过18,000个多项选择题,涵盖六个不同的类别:含义、真/假、填空、语境使用、文化解释和位置识别。这些问题来源于精心策划的方言词汇、短语和谚语数据集,这些数据来自沙特阿拉伯的各个地区。我们评估了几种最先进的LLMs,包括多语言和特定于阿拉伯语的模型。我们还详细介绍了它们的能力和局限性。我们的结果揭示了显著的性能差距,尤其是在需要文化推断或语境理解的任务中。我们的研究结果强调,迫切需要进行方言感知训练和文化对齐的评估方法,以提高LLMs在实际阿拉伯语应用中的性能。
🔬 方法详解
问题定义:论文旨在解决LLM在理解和处理沙特阿拉伯方言及其文化背景方面的不足。现有方法主要集中在标准阿拉伯语上,忽略了方言的复杂性和文化独特性,导致LLM在实际应用中表现不佳。现有方法缺乏针对沙特方言的综合评估基准。
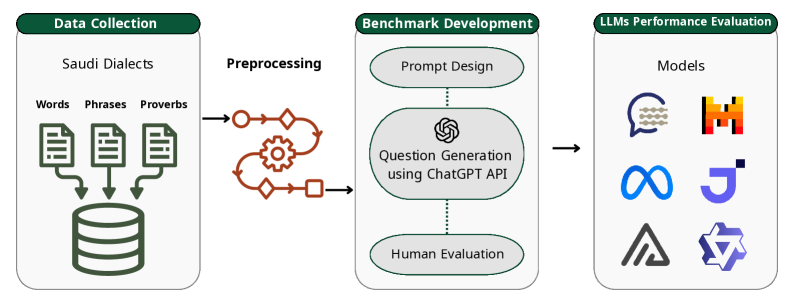
核心思路:论文的核心思路是构建一个全面的、多维度的基准数据集Absher,用于系统性地评估LLM在沙特方言和文化理解方面的能力。通过设计不同类型的题目,考察LLM在词汇、语法、语境、文化等多个层面的理解程度,从而揭示LLM的优势和不足。
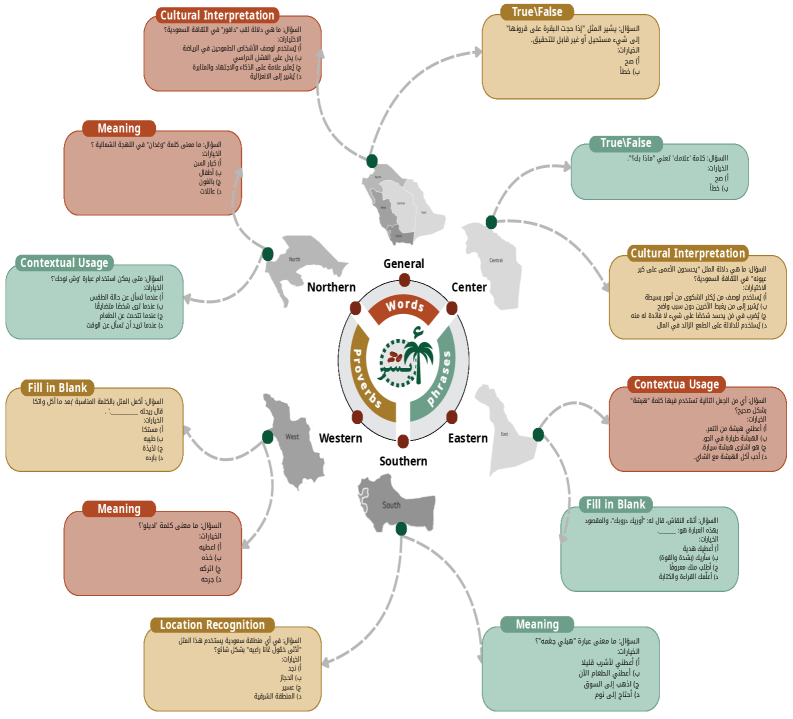
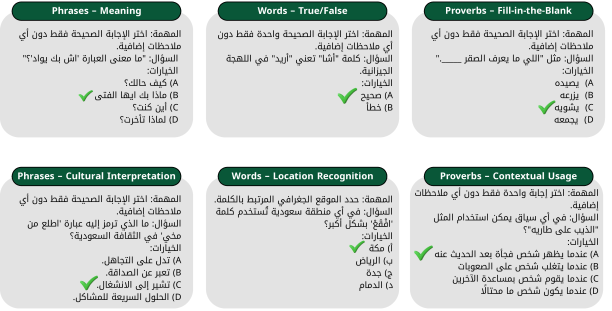
技术框架:Absher基准包含六个主要类别:含义(词汇释义)、真/假(陈述判断)、填空(语法和语境理解)、语境使用(实际应用)、文化解释(文化内涵理解)和位置识别(地理知识)。数据集来源于沙特阿拉伯不同地区的方言词汇、短语和谚语。评估流程包括:1) 选择待评估的LLM;2) 将Absher中的问题输入LLM;3) 记录LLM的答案;4) 根据预定义的评估指标,计算LLM在各个类别上的性能。
关键创新:Absher基准的主要创新在于其专注于沙特阿拉伯方言和文化,填补了现有阿拉伯语NLP评估的空白。它不仅考察LLM的语言能力,还深入评估其文化理解能力,更全面地反映了LLM在实际应用中的表现。此外,Absher的多样化题型设计,能够更细致地揭示LLM在不同方面的优势和不足。
关键设计:Absher数据集包含超过18,000个多项选择题,确保了评估的全面性和可靠性。每个问题都经过专家审核,保证了其准确性和文化相关性。评估指标包括准确率、召回率和F1值等,用于量化LLM在各个类别上的性能。数据集的构建过程中,充分考虑了沙特阿拉伯不同地区的方言差异,力求覆盖尽可能多的方言变体。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有LLM在Absher基准上的表现参差不齐,尤其是在文化解释和语境使用方面存在明显差距。多语言模型和特定于阿拉伯语的模型在不同类别上的表现各有优劣,但总体而言,都需要进一步加强对方言和文化的理解。例如,在文化解释类别中,一些模型的准确率仅为个位数,表明其对沙特阿拉伯文化的理解非常有限。
🎯 应用场景
该研究成果可应用于开发更智能、更贴近沙特阿拉伯用户需求的阿拉伯语LLM。例如,可以用于改进聊天机器人、语音助手、机器翻译等应用,使其能够更好地理解和回应用户的方言表达和文化背景。此外,Absher基准可以促进方言感知训练方法的研究,推动阿拉伯语NLP技术的进步。
📄 摘要(原文)
As large language models (LLMs) become increasingly central to Arabic NLP applications, evaluating their understanding of regional dialects and cultural nuances is essential, particularly in linguistically diverse settings like Saudi Arabia. This paper introduces Absher, a comprehensive benchmark specifically designed to assess LLMs performance across major Saudi dialects. \texttt{Absher} comprises over 18,000 multiple-choice questions spanning six distinct categories: Meaning, True/False, Fill-in-the-Blank, Contextual Usage, Cultural Interpretation, and Location Recognition. These questions are derived from a curated dataset of dialectal words, phrases, and proverbs sourced from various regions of Saudi Arabia. We evaluate several state-of-the-art LLMs, including multilingual and Arabic-specific models. We also provide detailed insights into their capabilities and limitations. Our results reveal notable performance gaps, particularly in tasks requiring cultural inference or contextual understanding. Our findings highlight the urgent need for dialect-aware training and culturally aligned evaluation methodologies to improve LLMs performance in real-world Arabic applications.