DATE-LM: Benchmarking Data Attribution Evaluation for Large Language Models
作者: Cathy Jiao, Yijun Pan, Emily Xiao, Daisy Sheng, Niket Jain, Hanzhang Zhao, Ishita Dasgupta, Jiaqi W. Ma, Chenyan Xiong
分类: cs.CL
发布日期: 2025-07-12 (更新: 2025-10-25)
备注: NeurIPS 2025 Datasets and Benchmarks Track
💡 一句话要点
DATE-LM:用于评估大型语言模型数据归因方法的统一基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据归因 大型语言模型 基准测试 模型评估 可解释性
📋 核心要点
- 现有数据归因方法缺乏针对大型语言模型(LLM)的系统性评估,阻碍了其在实际LLM应用中的有效应用。
- DATE-LM基准通过训练数据选择、毒性/偏见过滤和事实归因三个关键任务,统一评估数据归因方法的性能。
- 大规模实验表明,没有单一方法在所有任务中表现最佳,且方法性能对任务设计敏感,并提供公开排行榜。
📝 摘要(中文)
数据归因方法旨在量化训练数据对模型输出的影响,这对于大型语言模型(LLM)研究和应用至关重要,包括数据集管理、模型可解释性和数据价值评估。然而,目前缺乏针对LLM的数据归因方法的系统性评估。为此,我们提出了DATE-LM(语言模型中的数据归因评估),这是一个统一的基准,通过实际的LLM应用来评估数据归因方法。DATE-LM通过三个关键任务衡量归因质量:训练数据选择、毒性和偏见过滤以及事实归因。我们的基准易于使用,使研究人员能够配置和运行跨不同任务和LLM架构的大规模评估。此外,我们使用DATE-LM对现有的数据归因方法进行了大规模评估。结果表明,没有一种方法在所有任务中都占主导地位,数据归因方法与更简单的基线方法存在权衡,并且方法性能对特定任务的评估设计敏感。最后,我们发布了一个公共排行榜,用于快速比较方法并促进社区参与,希望DATE-LM可以作为未来LLM数据归因研究的基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)领域中数据归因方法缺乏系统性、统一评估的问题。现有方法难以在不同任务和模型架构上进行有效比较,阻碍了数据归因方法在数据集管理、模型可解释性和数据价值评估等实际应用中的发展。现有方法的痛点在于缺乏一个标准化的评估框架,无法客观地衡量不同数据归因方法在LLM上的性能。
核心思路:论文的核心思路是构建一个名为DATE-LM的统一基准,该基准包含多个具有代表性的LLM应用任务,并提供标准化的评估指标。通过在DATE-LM上评估不同的数据归因方法,可以系统地比较它们的性能,并识别出适用于特定任务的最佳方法。这种方法能够促进数据归因方法在LLM领域的应用和发展。
技术框架:DATE-LM基准主要包含以下几个组成部分: 1. 任务定义:定义了三个关键任务,包括训练数据选择、毒性/偏见过滤和事实归因,这些任务代表了LLM应用中数据归因的常见需求。 2. 数据集:为每个任务提供了相应的数据集,这些数据集涵盖了不同的领域和规模,以保证评估的全面性。 3. 评估指标:为每个任务定义了标准化的评估指标,用于衡量数据归因方法的性能。 4. 评估流程:提供了一套易于使用的评估流程,使研究人员能够方便地配置和运行大规模评估。
关键创新:DATE-LM的关键创新在于其统一性和全面性。它首次提供了一个专门针对LLM的数据归因评估基准,涵盖了多个关键任务和数据集,并提供了标准化的评估指标和流程。这使得研究人员能够系统地比较不同的数据归因方法,并识别出适用于特定任务的最佳方法。此外,DATE-LM还提供了一个公共排行榜,促进了社区的参与和合作。
关键设计:DATE-LM的关键设计包括: 1. 任务选择:选择了训练数据选择、毒性/偏见过滤和事实归因三个任务,这些任务代表了LLM应用中数据归因的常见需求。 2. 数据集构建:为每个任务构建了相应的数据集,这些数据集涵盖了不同的领域和规模,以保证评估的全面性。 3. 评估指标设计:为每个任务设计了标准化的评估指标,例如,训练数据选择任务可以使用选择数据的有效性作为指标,毒性/偏见过滤任务可以使用过滤后的数据毒性/偏见程度作为指标,事实归因任务可以使用归因结果的准确性作为指标。
🖼️ 关键图片

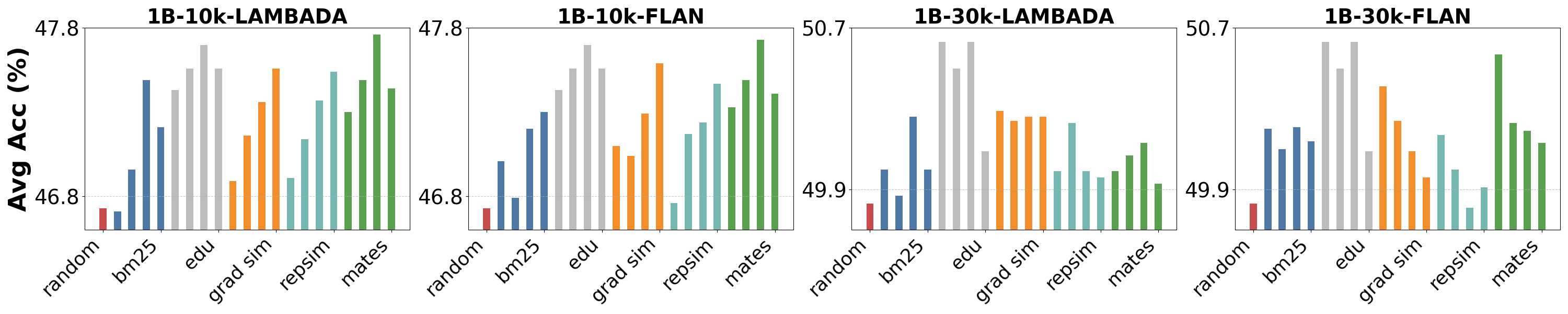

📊 实验亮点
实验结果表明,没有单一的数据归因方法在所有任务中都表现最佳,不同的方法在不同的任务上各有优劣。此外,研究还发现,数据归因方法的性能对任务特定的评估设计非常敏感。DATE-LM基准的发布,为研究人员提供了一个统一的平台,可以更方便地比较和评估不同的数据归因方法,从而推动该领域的发展。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的开发和应用中,例如,可以利用数据归因方法进行数据集的清洗和优化,提高模型的性能和安全性;可以用于模型的可解释性分析,帮助理解模型的决策过程;还可以用于数据价值评估,为数据交易提供依据。未来,该研究有望推动数据归因方法在LLM领域的更广泛应用,促进LLM技术的进步。
📄 摘要(原文)
Data attribution methods quantify the influence of training data on model outputs and are becoming increasingly relevant for a wide range of LLM research and applications, including dataset curation, model interpretability, data valuation. However, there remain critical gaps in systematic LLM-centric evaluation of data attribution methods. To this end, we introduce DATE-LM (Data Attribution Evaluation in Language Models), a unified benchmark for evaluating data attribution methods through real-world LLM applications. DATE-LM measures attribution quality through three key tasks -- training data selection, toxicity/bias filtering, and factual attribution. Our benchmark is designed for ease of use, enabling researchers to configure and run large-scale evaluations across diverse tasks and LLM architectures. Furthermore, we use DATE-LM to conduct a large-scale evaluation of existing data attribution methods. Our findings show that no single method dominates across all tasks, data attribution methods have trade-offs with simpler baselines, and method performance is sensitive to task-specific evaluation design. Finally, we release a public leaderboard for quick comparison of methods and to facilitate community engagement, with the motivation that DATE-LM can serve as a foundation for future data attribution research in LLMs.