KV Cache Steering for Controlling Frozen LLMs
作者: Max Belitsky, Dawid J. Kopiczko, Michael Dorkenwald, M. Jehanzeb Mirza, James R. Glass, Cees G. M. Snoek, Yuki M. Asano
分类: cs.CL, cs.AI
发布日期: 2025-07-11 (更新: 2025-09-26)
💡 一句话要点
提出KV缓存引导方法,无需微调即可控制冻结LLM的推理行为
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存 语言模型引导 思维链推理 零样本学习 模型控制
📋 核心要点
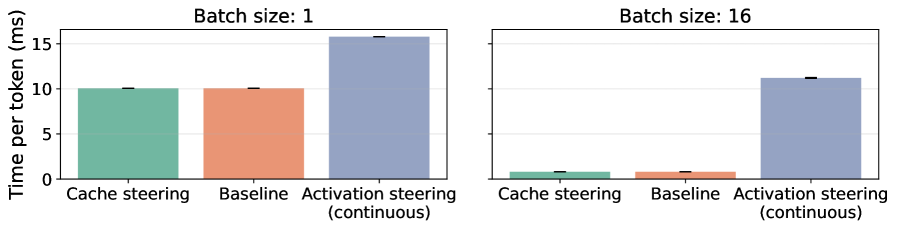
- 现有激活引导方法需要连续干预,导致推理延迟高、超参数不稳定,集成困难。
- 提出KV缓存引导,通过一次性干预KV缓存,实现对冻结LLM推理行为的隐式控制。
- 实验表明,该方法能有效诱导CoT推理,提升模型在GPQA、MATH等数据集上的性能。
📝 摘要(中文)
本文提出了一种名为缓存引导的轻量级方法,通过对键值缓存进行一次性干预,隐式地引导语言模型。为了验证其有效性,我们将缓存引导应用于诱导小型语言模型进行思维链推理。我们的方法从推理轨迹中构建引导向量,这些轨迹可以从教师模型(例如GPT-4o)或现有的人工标注中获得,从而将模型行为转变为更明确的多步骤推理,而无需微调或提示修改。在各种推理基准上的实验评估表明,缓存引导改善了模型推理的定性结构和定量任务性能。额外的实验表明,该方法还可以扩展到更大的模型,并在具有挑战性的数据集(如GPQA和MATH)上产生进一步的收益。与需要连续干预的先前激活引导技术相比,我们的一次性缓存引导在推理延迟、超参数稳定性和与现有推理API的易于集成方面具有显著优势。除了单纯的推理诱导之外,我们还表明缓存引导能够可控地转移推理风格(例如,逐步、因果、类比),使其成为行为级指导语言模型的实用工具。
🔬 方法详解
问题定义:现有激活引导技术通常需要持续的干预,这导致了推理延迟的增加,超参数调整的复杂性,以及与现有推理API的集成困难。论文旨在解决如何在不进行微调或复杂提示工程的情况下,控制和引导冻结的大型语言模型(LLM)的推理行为,特别是诱导模型进行思维链(Chain-of-Thought, CoT)推理。
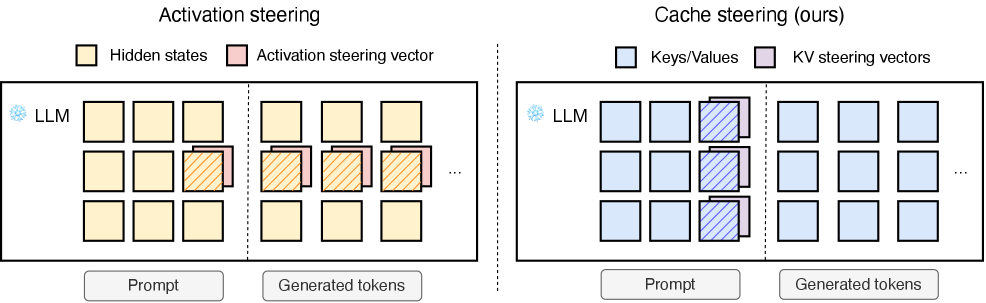
核心思路:论文的核心思路是利用LLM的Key-Value (KV) 缓存。KV缓存存储了先前token的上下文信息,通过直接修改KV缓存,可以在不改变模型参数的情况下影响后续token的生成。通过构建“引导向量”,将期望的推理行为(例如CoT推理)注入到KV缓存中,从而引导模型产生期望的输出。
技术框架:该方法主要包含以下几个阶段:1) 收集推理轨迹:从教师模型(如GPT-4o)或人工标注中获取期望的推理过程样本。2) 构建引导向量:基于推理轨迹,计算出能够代表期望推理行为的向量。3) KV缓存干预:将引导向量添加到目标模型的KV缓存中,从而影响模型的后续推理过程。整个过程无需微调模型参数。
关键创新:该方法的关键创新在于:1) 一次性干预:与需要连续干预的激活引导方法不同,KV缓存引导只需要一次性干预,显著降低了推理延迟。2) 隐式引导:通过修改KV缓存,实现对模型行为的隐式控制,无需修改模型参数或提示。3) 可控的推理风格转移:能够实现不同推理风格(如逐步、因果、类比)的转移。
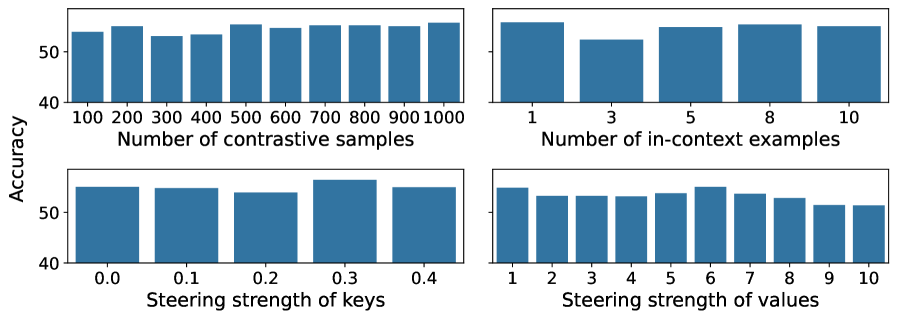
关键设计:引导向量的构建是关键。具体来说,对于CoT推理,可以使用教师模型生成的CoT推理轨迹,计算每个token对应的KV表示,然后将这些KV表示进行聚合(例如,取平均),得到一个代表CoT推理的引导向量。在推理时,将该引导向量添加到目标模型的KV缓存中,从而引导模型进行CoT推理。论文可能还涉及一些超参数的调整,例如引导向量的缩放比例等,以平衡引导效果和模型自身的推理能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,KV缓存引导能够有效提升小型语言模型的推理能力,在多个推理基准测试中取得了显著的性能提升。例如,在GPQA和MATH等具有挑战性的数据集上,该方法也取得了进一步的收益。与传统的激活引导方法相比,该方法具有更低的推理延迟和更高的超参数稳定性。
🎯 应用场景
该研究成果可应用于多种场景,例如:提升小型语言模型的推理能力,无需昂贵的微调成本;控制LLM的推理风格,使其更符合特定任务的需求;在教育领域,引导学生进行更清晰、更结构化的思考;在对话系统中,控制对话的走向和内容。
📄 摘要(原文)
We propose cache steering, a lightweight method for implicit steering of language models via a one-shot intervention applied directly to the key-value cache. To validate its effectiveness, we apply cache steering to induce chain-of-thought reasoning in small language models. Our approach constructs steering vectors from reasoning traces, obtained either from teacher models (e.g., GPT-4o) or existing human annotations, that shift model behavior toward more explicit, multi-step reasoning without fine-tuning or prompt modifications. Experimental evaluations on diverse reasoning benchmarks demonstrate that cache steering improves both the qualitative structure of model reasoning and quantitative task performance. Additional experiments show that the method also scales to larger models and yields further gains on challenging datasets such as GPQA and MATH. Compared to prior activation steering techniques that require continuous interventions, our one-shot cache steering offers substantial advantages in terms of inference latency, hyperparameter stability, and ease of integration with existing inference APIs. Beyond mere reasoning induction, we show that cache steering enables controllable transfer of reasoning styles (e.g., stepwise, causal, analogical), making it a practical tool for behavior-level guidance of language models.