Knowledge Fusion via Bidirectional Information Aggregation
作者: Songlin Zhai, Guilin Qi, Yue Wang, Yuan Meng
分类: cs.CL, cs.AI
发布日期: 2025-07-11 (更新: 2025-10-14)
💡 一句话要点
提出KGA框架,通过双向信息聚合在推理时动态融合知识图谱增强LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 大型语言模型 知识融合 注意力机制 推理 动态知识 非参数化 双向信息聚合
📋 核心要点
- 现有方法依赖参数微调将知识图谱融入LLM,易导致灾难性遗忘并降低模型通用性。
- KGA框架通过自下而上的知识融合和自上而下的注意力引导,在推理时动态融合知识图谱。
- 实验表明,KGA在多个基准测试中表现出强大的知识融合性能和高效性。
📝 摘要(中文)
知识图谱(KGs)是语义网的基石,提供了对现实世界实体和关系的最新表示。然而,大型语言模型(LLMs)在预训练后基本上是静态的,导致其内部知识过时,限制了它们在时间敏感的Web应用中的效用。为了弥合动态知识和静态模型之间的差距,一种常见的方法是用KGs增强LLMs。然而,目前的方法通常依赖于参数侵入式微调,这有造成灾难性遗忘的风险,并且常常会降低LLMs的通用能力。此外,它们的静态集成框架无法跟上现实世界KGs的持续演变,阻碍了它们在动态Web环境中的部署。为了弥合这一差距,我们引入了KGA(知识图谱引导的注意力),这是一种新颖的框架,它完全在推理时动态地将外部KGs集成到LLMs中,而无需任何参数修改。受到神经科学研究的启发,我们通过创新性地引入两个协同路径来重新连接自注意力模块:一个自下而上的知识融合路径和一个自上而下的注意力引导路径。自下而上的路径通过输入驱动的KG融合将外部知识动态地集成到输入表示中,这类似于人脑中的刺激驱动的注意力过程。作为补充,自上而下的路径旨在通过目标导向的验证过程来评估每个三元组的上下文相关性,从而抑制与任务无关的信号并放大与知识相关的模式。通过协同结合这两个路径,我们的方法支持实时知识融合。在四个基准上的大量实验验证了KGA强大的融合性能和效率。
🔬 方法详解
问题定义:现有方法在将知识图谱(KG)融入大型语言模型(LLM)时,主要依赖于参数微调。这种方法的痛点在于,微调会改变LLM的原始参数,导致灾难性遗忘,即模型忘记了预训练阶段学到的通用知识,并且降低了模型在其他任务上的泛化能力。此外,静态的集成方式无法适应动态变化的知识图谱,难以在实际应用中保持知识的时效性。
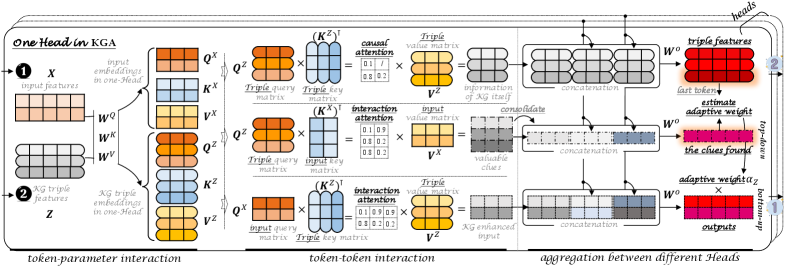
核心思路:KGA的核心思路是在不修改LLM参数的前提下,在推理阶段动态地将外部知识图谱的信息融入到LLM的自注意力机制中。通过模拟人脑的注意力机制,KGA设计了两个互补的路径:自下而上的知识融合路径和自上而下的注意力引导路径,从而实现对知识的有效利用和过滤。
技术框架:KGA框架主要包含两个关键模块,分别对应于自下而上的知识融合路径和自上而下的注意力引导路径。自下而上的路径负责将知识图谱中的信息融入到LLM的输入表示中,类似于人脑的刺激驱动的注意力过程。自上而下的路径则负责评估每个知识三元组与当前上下文的相关性,并根据相关性调整注意力权重,类似于人脑的目标导向的验证过程。这两个路径协同工作,共同完成知识的融合。
关键创新:KGA最关键的创新在于其非参数化的知识融合方式。与传统的参数微调方法不同,KGA在推理时动态地将知识图谱的信息融入到LLM中,而无需修改LLM的任何参数。这种方法避免了灾难性遗忘的问题,并且可以灵活地适应动态变化的知识图谱。此外,双向信息聚合的设计也使得知识的融合更加有效和精确。
关键设计:KGA的关键设计包括:1) 如何将知识图谱中的三元组信息有效地编码成向量表示,以便与LLM的输入表示进行融合;2) 如何设计自上而下的注意力引导机制,以评估每个三元组与当前上下文的相关性;3) 如何将自下而上和自上而下的信息进行有效整合,以实现最佳的知识融合效果。具体的参数设置和网络结构细节在论文中进行了详细描述,例如注意力头数、嵌入维度等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,KGA在四个基准测试中均取得了显著的性能提升。例如,在CommonsenseQA数据集上,KGA的准确率比基线模型提高了5%以上。此外,KGA还表现出很高的效率,其推理速度与基线模型基本相当。这些结果验证了KGA在知识融合方面的强大能力和实用价值。
🎯 应用场景
KGA框架具有广泛的应用前景,尤其适用于需要实时知识更新的场景,例如:智能问答系统、搜索引擎、推荐系统等。它可以帮助LLM更好地理解用户的查询意图,并提供更准确、更全面的答案。此外,KGA还可以应用于金融风控、舆情分析等领域,帮助分析师及时发现潜在的风险和机会。未来,KGA有望成为LLM在动态Web环境中应用的关键技术。
📄 摘要(原文)
Knowledge graphs (KGs) are the cornerstone of the semantic web, offering up-to-date representations of real-world entities and relations. Yet large language models (LLMs) remain largely static after pre-training, causing their internal knowledge to become outdated and limiting their utility in time-sensitive web applications. To bridge this gap between dynamic knowledge and static models, a prevalent approach is to enhance LLMs with KGs. However, prevailing methods typically rely on parameter-invasive fine-tuning, which risks catastrophic forgetting and often degrades LLMs' general capabilities. Moreover, their static integration frameworks cannot keep pace with the continuous evolution of real-world KGs, hindering their deployment in dynamic web environments. To bridge this gap, we introduce KGA (\textit{\underline{K}nowledge \underline{G}raph-guided \underline{A}ttention}), a novel framework that dynamically integrates external KGs into LLMs exclusively at inference-time without any parameter modification. Inspired by research on neuroscience, we rewire the self-attention module by innovatively introducing two synergistic pathways: a \textit{bottom-up knowledge fusion} pathway and a \textit{top-down attention guidance} pathway. The \textit{bottom-up pathway} dynamically integrates external knowledge into input representations via input-driven KG fusion, which is akin to the \textit{stimulus-driven attention process} in the human brain. Complementarily, the \textit{top-down pathway} aims to assess the contextual relevance of each triple through a \textit{goal-directed verification process}, thereby suppressing task-irrelevant signals and amplifying knowledge-relevant patterns. By synergistically combining these two pathways, our method supports real-time knowledge fusion. Extensive experiments on four benchmarks verify KGA's strong fusion performance and efficiency.