Using Large Language Models for Legal Decision-Making in Austrian Value-Added Tax Law: An Experimental Study
作者: Marina Luketina, Andrea Benkel, Christoph G. Schuetz
分类: cs.CL
发布日期: 2025-07-11
备注: 26 pages, 5 figures, 6 tables
💡 一句话要点
利用大型语言模型辅助奥地利增值税法法律决策
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 法律决策 增值税法 微调 检索增强生成 税务咨询 自动化决策
📋 核心要点
- 税务咨询中,客户以自然语言描述案例,对税务专业人员提出了自动化决策和减少工作量的需求,但现有方法难以有效处理。
- 论文探索了微调和检索增强生成(RAG)两种方法,旨在提升大型语言模型(LLM)在增值税法律决策中的性能。
- 实验结果表明,适当配置的LLM可以有效支持税务专业人员完成增值税任务,并提供法律依据,但仍需改进以处理隐性知识。
📝 摘要(中文)
本文对大型语言模型(LLM)在奥地利和欧盟增值税(VAT)法律框架内辅助法律决策的能力进行了实验性评估。在税务咨询实践中,客户通常用自然语言描述案例,这使得LLM成为支持自动化决策和减少税务专业人员工作量的理想选择。鉴于法律依据和充分论证的要求,LLM产生幻觉的倾向构成了一项重大挑战。实验重点关注两种常用的增强LLM性能的方法:微调和检索增强生成(RAG)。本研究将这些方法应用于教科书案例和税务咨询公司的真实案例,以系统地确定基于LLM的系统的最佳配置,并评估LLM的法律推理能力。研究结果强调了使用LLM通过自动化日常任务和提供初步分析来支持税务顾问的潜力,但由于法律领域的敏感性,目前的原型尚未准备好实现完全自动化。研究结果表明,经过适当配置的LLM可以有效地支持税务专业人员完成增值税任务,并为决策提供法律依据。然而,在处理隐性客户知识和特定背景文档方面仍然存在局限性,这突显了未来需要整合结构化背景信息。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在奥地利和欧盟增值税(VAT)法律框架下辅助法律决策的问题。现有方法,即直接使用未经调整的LLM,在法律推理和提供法律依据方面存在不足,容易产生幻觉,无法满足法律领域对准确性和可靠性的高要求。税务咨询实践中,客户以自然语言描述案例,这增加了LLM理解和处理的难度。
核心思路:论文的核心思路是通过微调和检索增强生成(RAG)两种方法来增强LLM在增值税法律决策中的能力。微调旨在使LLM更好地适应特定的法律领域知识和推理模式,RAG则通过检索相关法律文档来增强LLM的知识储备,从而减少幻觉并提高决策的准确性。
技术框架:整体框架包含数据准备、模型训练/微调、检索模块构建和评估四个主要阶段。数据准备阶段收集并整理增值税相关的法律文本、案例和客户咨询记录。模型训练/微调阶段使用准备好的数据对LLM进行微调,使其适应法律领域的特定任务。检索模块构建阶段构建一个可以从法律文档中检索相关信息的系统。评估阶段使用教科书案例和真实案例来评估LLM的法律推理能力和决策准确性。
关键创新:论文的关键创新在于系统性地比较和评估了微调和RAG两种方法在增值税法律决策中的效果,并针对法律领域的特殊需求进行了优化。此外,论文还使用了真实世界的税务咨询案例,使得研究结果更具实际意义和参考价值。
关键设计:论文中,微调过程可能涉及调整LLM的学习率、训练轮数和损失函数权重等参数,以优化其在法律领域的表现。RAG的设计可能包括选择合适的向量数据库、相似度度量方法和检索策略,以确保能够检索到最相关的法律文档。具体的损失函数和网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
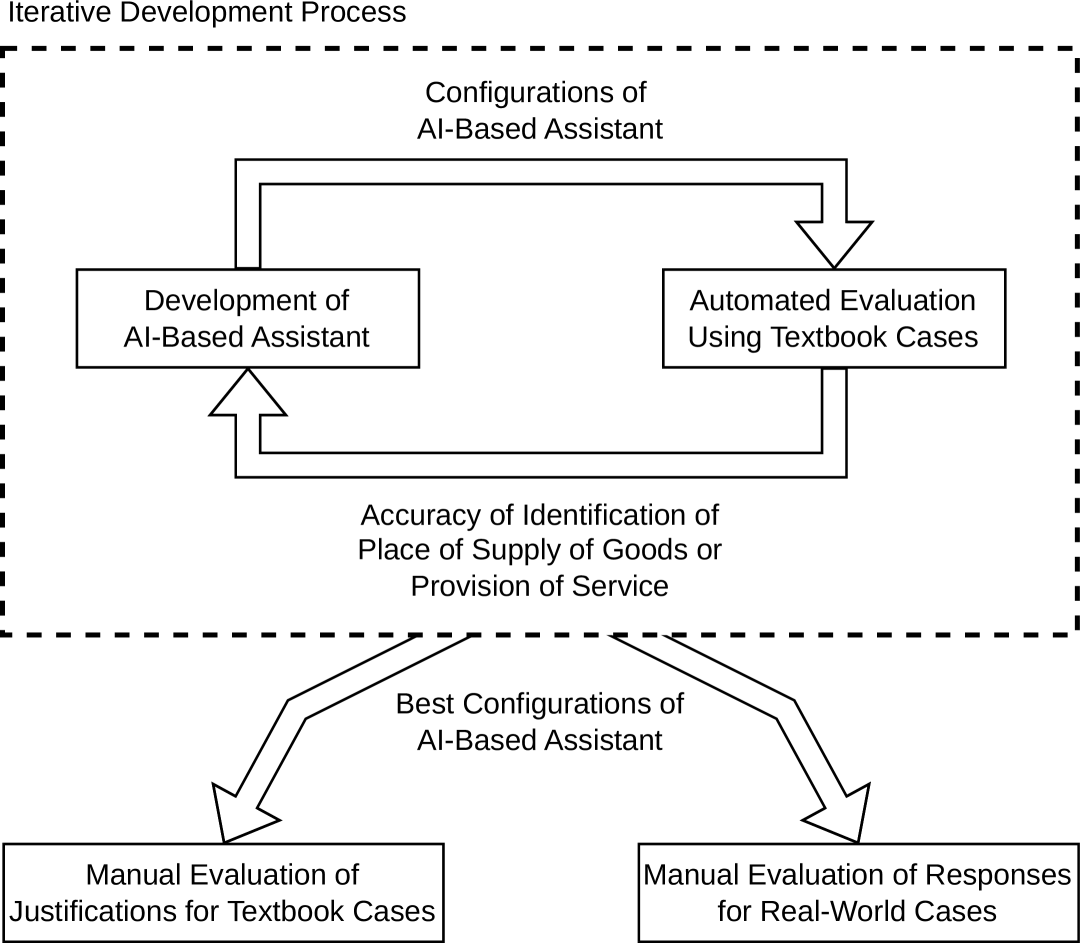
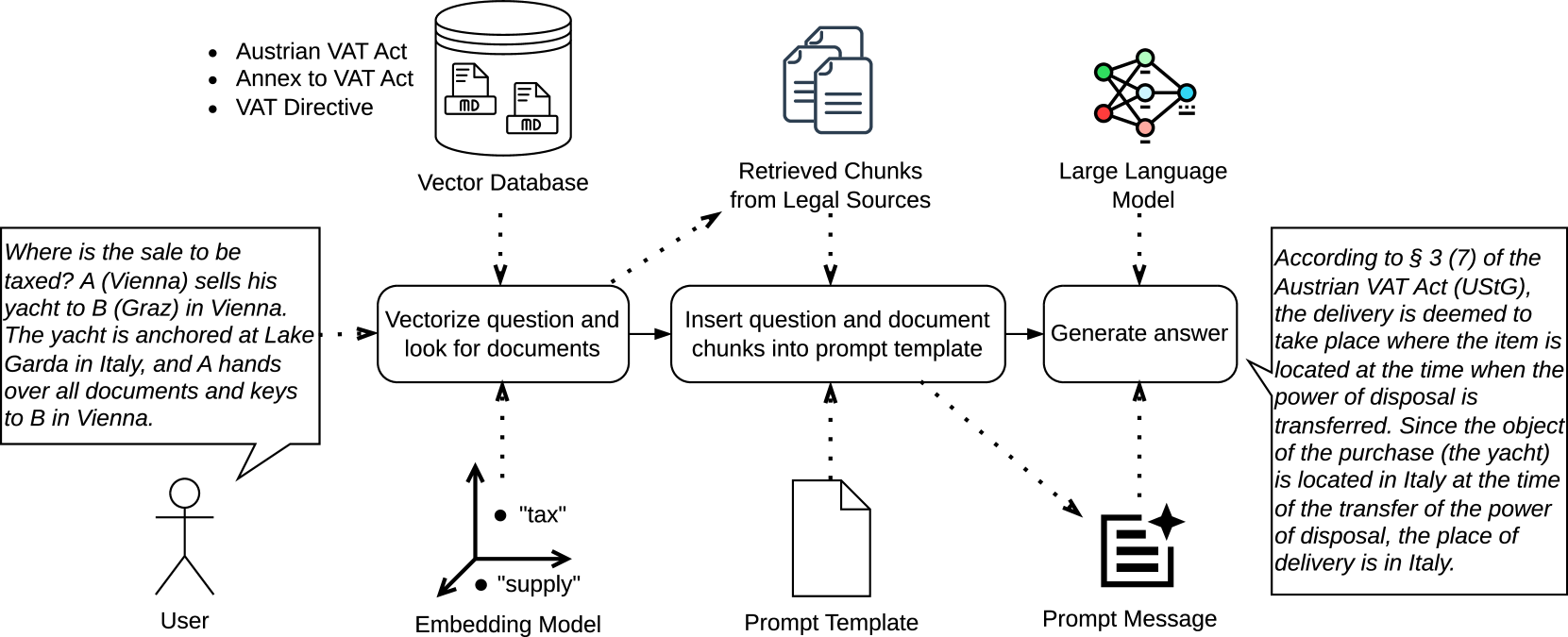

📊 实验亮点
实验结果表明,经过适当配置的LLM可以有效地支持税务专业人员完成增值税任务,并为决策提供法律依据。虽然具体的性能数据和提升幅度在摘要中未明确给出,但研究强调了LLM在自动化日常任务和提供初步分析方面的潜力。研究还指出了当前原型在处理隐性客户知识和特定背景文档方面的局限性,为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于税务咨询、法律服务等领域,通过自动化部分法律决策过程,降低税务专业人员的工作负担,提高工作效率。未来,结合结构化背景信息和知识图谱,有望实现更智能、更可靠的法律决策支持系统,推动法律科技的发展。
📄 摘要(原文)
This paper provides an experimental evaluation of the capability of large language models (LLMs) to assist in legal decision-making within the framework of Austrian and European Union value-added tax (VAT) law. In tax consulting practice, clients often describe cases in natural language, making LLMs a prime candidate for supporting automated decision-making and reducing the workload of tax professionals. Given the requirement for legally grounded and well-justified analyses, the propensity of LLMs to hallucinate presents a considerable challenge. The experiments focus on two common methods for enhancing LLM performance: fine-tuning and retrieval-augmented generation (RAG). In this study, these methods are applied on both textbook cases and real-world cases from a tax consulting firm to systematically determine the best configurations of LLM-based systems and assess the legal-reasoning capabilities of LLMs. The findings highlight the potential of using LLMs to support tax consultants by automating routine tasks and providing initial analyses, although current prototypes are not ready for full automation due to the sensitivity of the legal domain. The findings indicate that LLMs, when properly configured, can effectively support tax professionals in VAT tasks and provide legally grounded justifications for decisions. However, limitations remain regarding the handling of implicit client knowledge and context-specific documentation, underscoring the need for future integration of structured background information.