Distillation versus Contrastive Learning: How to Train Your Rerankers
作者: Zhichao Xu, Zhiqi Huang, Shengyao Zhuang, Vivek Srikumar
分类: cs.CL, cs.IR
发布日期: 2025-07-11 (更新: 2025-11-06)
备注: IJCNLP-AACL 2025 Findings
💡 一句话要点
对比学习与知识蒸馏:用于训练文本重排序器的有效策略研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本重排序 对比学习 知识蒸馏 信息检索 跨编码器
📋 核心要点
- 现有的文本重排序器训练方法,如对比学习和知识蒸馏,缺乏在实际场景下的有效性对比研究。
- 该论文通过对比学习和知识蒸馏两种策略,训练不同大小和架构的重排序器,分析其性能差异。
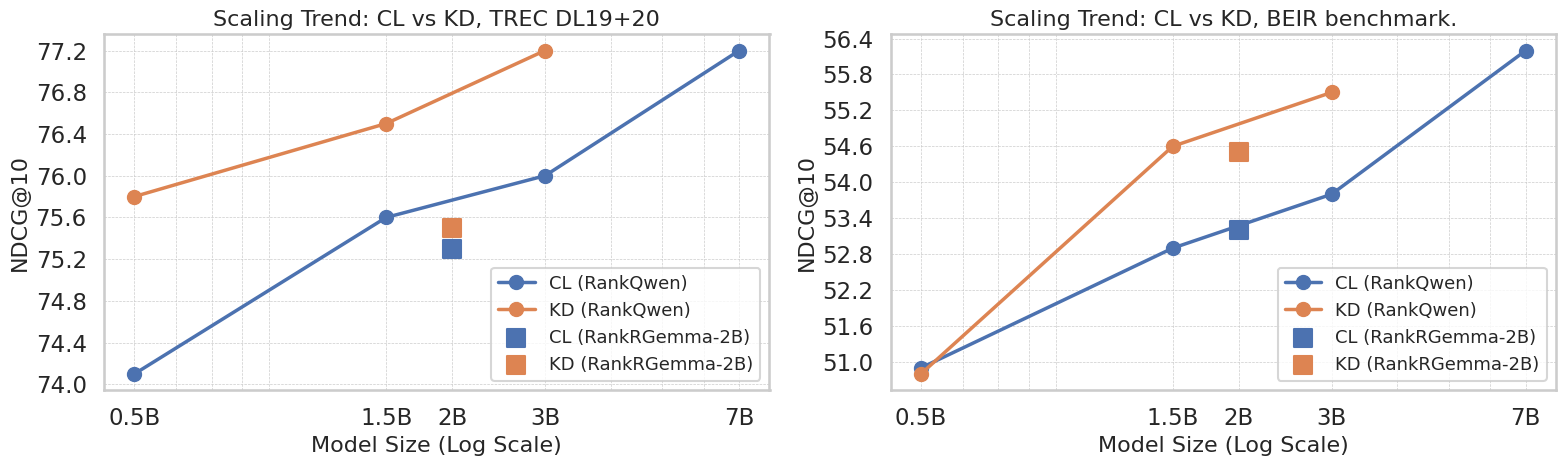
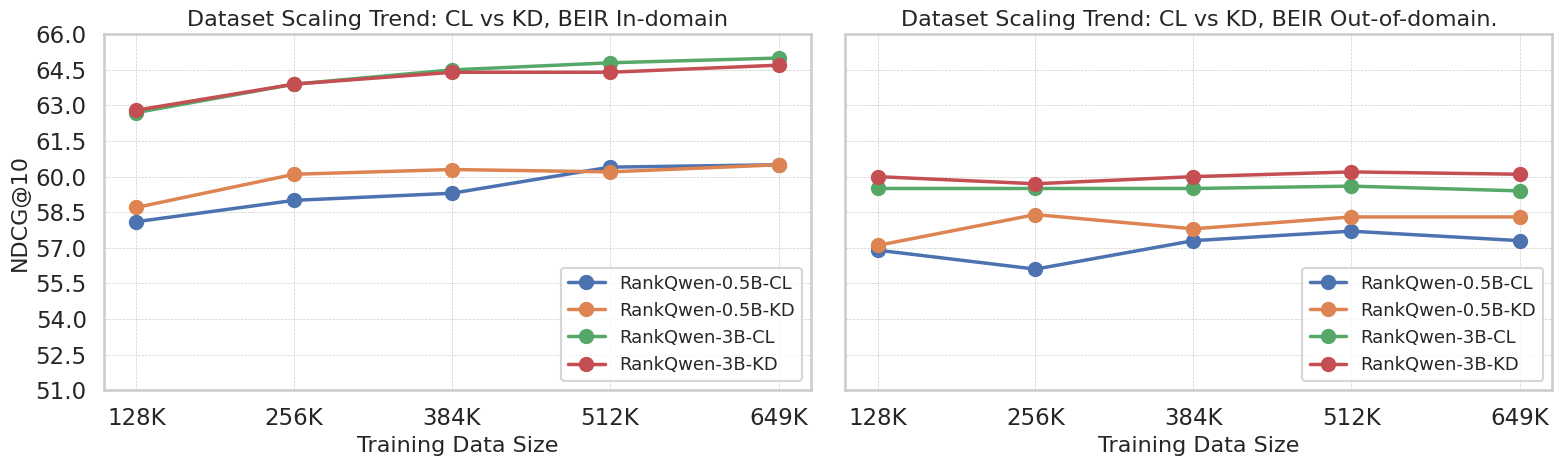
- 实验结果表明,从更优教师模型蒸馏时,知识蒸馏优于对比学习,但同等容量教师模型蒸馏优势不明显。
📝 摘要(中文)
训练有效的文本重排序器对于信息检索至关重要。目前广泛使用的两种策略是:对比学习(直接优化真实标签)和知识蒸馏(从更大的重排序器迁移知识)。虽然这两种方法都得到了广泛的研究,但仍需要对它们在实际条件下训练跨编码器重排序器的有效性进行清晰的比较。本文通过使用相同的数据,利用对比学习模型作为蒸馏教师,训练不同大小(0.5B、1.5B、3B、7B)和架构(Transformer、Recurrent)的重排序器,从而对这些策略进行了实证比较。结果表明,当从性能更优越的教师模型进行蒸馏时,知识蒸馏通常比对比学习产生更好的领域内和领域外排序性能。这一发现与学生模型的大小和架构一致。然而,从相同容量的教师模型进行蒸馏并不能提供相同的优势,尤其是在领域外任务中。这些发现为基于可用的教师模型选择训练策略提供了实用的指导。如果可以访问更大的、性能更优越的教师模型,我们建议使用知识蒸馏来训练较小的重排序器;在没有教师模型的情况下,对比学习仍然是一个强大的基线。我们提供了代码实现以方便复现。
🔬 方法详解
问题定义:论文旨在解决文本重排序器训练策略选择的问题。现有方法,如对比学习和知识蒸馏,在训练跨编码器重排序器时,缺乏在实际条件下的有效性对比,导致难以选择合适的训练策略。特别是,在不同模型大小和架构下,以及在领域内和领域外数据上,两种方法的优劣势尚不明确。
核心思路:论文的核心思路是通过实证研究,系统地比较对比学习和知识蒸馏在训练文本重排序器时的性能。通过控制变量,例如模型大小、模型架构、训练数据和教师模型,来分析两种方法的优劣势,并为实际应用提供指导。核心在于探究知识蒸馏是否始终优于对比学习,以及教师模型的能力对蒸馏效果的影响。
技术框架:整体框架包括以下几个主要步骤:1) 数据准备:使用相同的数据集训练所有模型。2) 模型选择:选择不同大小(0.5B, 1.5B, 3B, 7B)和架构(Transformer, Recurrent)的重排序器作为学生模型。3) 教师模型:使用一个强大的对比学习模型作为知识蒸馏的教师模型。4) 训练:分别使用对比学习和知识蒸馏训练学生模型。5) 评估:在领域内和领域外数据集上评估模型的排序性能。
关键创新:论文的关键创新在于系统性地比较了对比学习和知识蒸馏在训练文本重排序器时的性能,并分析了教师模型能力对蒸馏效果的影响。之前的研究通常只关注单个方法,而忽略了两种方法在不同条件下的对比。该研究为实际应用提供了更全面的指导,帮助用户根据可用的教师模型选择合适的训练策略。
关键设计:论文的关键设计包括:1) 使用不同大小和架构的学生模型,以评估方法的泛化能力。2) 使用一个强大的对比学习模型作为教师模型,以确保蒸馏的有效性。3) 在领域内和领域外数据集上评估模型的性能,以评估方法的鲁棒性。4) 对比学习使用标准的损失函数,如InfoNCE。知识蒸馏使用KL散度损失函数,将教师模型的输出概率分布作为目标。具体参数设置(如学习率、batch size等)根据模型大小和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,当从性能更优越的教师模型进行蒸馏时,知识蒸馏通常比对比学习产生更好的领域内和领域外排序性能。例如,使用7B参数的教师模型蒸馏得到的学生模型,在领域外数据集上的性能显著优于直接使用对比学习训练的模型。然而,从相同容量的教师模型进行蒸馏并不能提供相同的优势,尤其是在领域外任务中。
🎯 应用场景
该研究成果可应用于各种信息检索场景,例如搜索引擎、问答系统、推荐系统等。通过选择合适的训练策略,可以提高重排序器的性能,从而提升用户体验。该研究也为知识蒸馏在文本检索领域的应用提供了指导,有助于开发更高效的检索系统。
📄 摘要(原文)
Training effective text rerankers is crucial for information retrieval. Two strategies are widely used: contrastive learning (optimizing directly on ground-truth labels) and knowledge distillation (transferring knowledge from a larger reranker). While both have been studied extensively, a clear comparison of their effectiveness for training cross-encoder rerankers under practical conditions is needed. This paper empirically compares these strategies by training rerankers of different sizes (0.5B, 1.5B, 3B, 7B) and architectures (Transformer, Recurrent) using both methods on the same data, with a strong contrastive learning model acting as the distillation teacher. Our results show that knowledge distillation generally yields better in-domain and out-of-domain ranking performance than contrastive learning when distilling from a more performant teacher model. This finding is consistent across student model sizes and architectures. However, distilling from a teacher of the same capacity does not provide the same advantage, particularly for out-of-domain tasks. These findings offer practical guidance for choosing a training strategy based on available teacher models. We recommend using knowledge distillation to train smaller rerankers if a larger, more performant teacher is accessible; in its absence, contrastive learning remains a robust baseline. Our code implementation is made available to facilitate reproducbility.