RLEP: Reinforcement Learning with Experience Replay for LLM Reasoning
作者: Hongzhi Zhang, Jia Fu, Jingyuan Zhang, Kai Fu, Qi Wang, Fuzheng Zhang, Guorui Zhou
分类: cs.CL
发布日期: 2025-07-10
备注: https://github.com/Kwai-Klear/RLEP
🔗 代码/项目: GITHUB
💡 一句话要点
RLEP:通过经验回放增强LLM推理的强化学习方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 经验回放 推理能力 数学问题求解
📋 核心要点
- 现有LLM强化学习训练不稳定,策略可能逐渐偏离预训练权重,导致训练困难。
- RLEP通过收集并回放高质量轨迹,引导模型学习有希望的推理路径,避免无效探索。
- 实验表明,RLEP能以更少的更新次数达到甚至超越基线性能,显著提升数学推理准确率。
📝 摘要(中文)
本文提出了一种名为RLEP(Reinforcement Learning with Experience rePlay)的框架,用于提升大型语言模型(LLM)的强化学习效果。该框架分为两个阶段:首先,收集经过验证的高质量轨迹;然后,在后续训练中回放这些轨迹。在每个更新步骤中,策略在混合了新生成的rollout和回放成功案例的mini-batch上进行优化。通过回放高质量的样本,RLEP引导模型远离无效的探索,将学习集中在有希望的推理路径上,从而实现更快的收敛和更强的最终性能。在Qwen2.5-Math-7B基础模型上,RLEP以更少的更新次数达到基线峰值精度,并最终超越它,在AIME-2024上的准确率从38.2%提高到39.9%,在AIME-2025上的准确率从19.8%提高到22.3%,在AMC-2023上的准确率从77.0%提高到82.2%。代码、数据集和检查点已公开。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在进行强化学习时,面临训练不稳定和策略漂移的问题。即,强化学习训练过程中,模型容易偏离其预训练的权重分布,导致性能下降或收敛速度缓慢。尤其是在复杂的推理任务中,探索空间巨大,模型容易陷入无效的探索,难以找到有效的推理路径。
核心思路:RLEP的核心思路是利用经验回放机制,将高质量的成功推理轨迹存储起来,并在后续的强化学习训练过程中重复利用这些轨迹。通过回放这些“成功经验”,RLEP能够引导模型朝着更有希望的方向探索,避免无效的尝试,从而加速学习过程并提高最终性能。
技术框架:RLEP框架包含两个主要阶段:1) 轨迹收集阶段:利用LLM生成推理轨迹,并对轨迹进行验证,筛选出高质量的成功轨迹。验证方法未知,但推测是基于奖励信号或外部知识库。2) 强化学习训练阶段:在每个更新步骤中,RLEP使用一个mini-batch来优化策略,该mini-batch包含两部分数据:一部分是新生成的rollout,另一部分是从经验回放缓冲区中采样的高质量轨迹。通过混合这两种数据,RLEP能够兼顾探索和利用,避免过拟合到新数据或遗忘已学知识。
关键创新:RLEP的关键创新在于将经验回放机制引入到LLM的强化学习训练中,并将其应用于复杂的推理任务。与传统的强化学习方法相比,RLEP能够更有效地利用已有的成功经验,从而提高学习效率和最终性能。此外,RLEP通过混合新生成数据和回放数据,平衡了探索和利用,避免了过拟合和策略漂移的问题。
关键设计:关于轨迹验证的具体方法未知。经验回放缓冲区的大小和采样策略未知。用于混合新生成数据和回放数据的比例未知。强化学习算法的选择未知,但推测使用了常见的策略梯度算法,例如PPO或SAC。奖励函数的设计未知,但推测是基于推理结果的正确性或与外部知识库的一致性。
🖼️ 关键图片

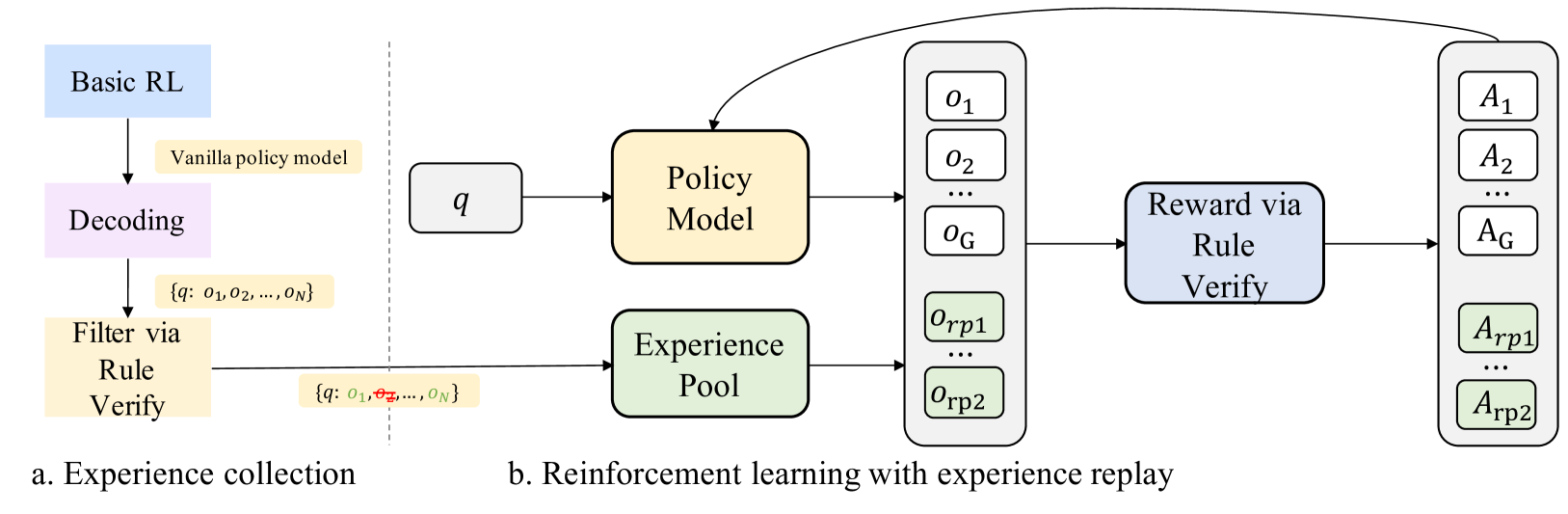

📊 实验亮点
RLEP在Qwen2.5-Math-7B模型上进行了实验,结果表明,RLEP能够以更少的更新次数达到基线峰值精度,并最终超越它。具体来说,在AIME-2024数据集上,准确率从38.2%提高到39.9%,提升了1.7%;在AIME-2025数据集上,准确率从19.8%提高到22.3%,提升了2.5%;在AMC-2023数据集上,准确率从77.0%提高到82.2%,提升了5.2%。这些结果表明,RLEP能够显著提升LLM在数学推理任务上的性能。
🎯 应用场景
RLEP方法可应用于各种需要复杂推理能力的大型语言模型,例如数学问题求解、代码生成、知识问答等。该方法能够提升LLM在这些任务上的准确率和效率,使其在教育、科研、金融等领域具有更广泛的应用前景。未来,RLEP的思路可以扩展到其他类型的任务和模型,例如多模态学习和机器人控制。
📄 摘要(原文)
Reinforcement learning (RL) for large language models is an energy-intensive endeavor: training can be unstable, and the policy may gradually drift away from its pretrained weights. We present \emph{RLEP}\, -- \,Reinforcement Learning with Experience rePlay\, -- \,a two-phase framework that first collects verified trajectories and then replays them during subsequent training. At every update step, the policy is optimized on mini-batches that blend newly generated rollouts with these replayed successes. By replaying high-quality examples, RLEP steers the model away from fruitless exploration, focuses learning on promising reasoning paths, and delivers both faster convergence and stronger final performance. On the Qwen2.5-Math-7B base model, RLEP reaches baseline peak accuracy with substantially fewer updates and ultimately surpasses it, improving accuracy on AIME-2024 from 38.2% to 39.9%, on AIME-2025 from 19.8% to 22.3%, and on AMC-2023 from 77.0% to 82.2%. Our code, datasets, and checkpoints are publicly available at https://github.com/Kwai-Klear/RLEP to facilitate reproducibility and further research.