Multi-Agent Retrieval-Augmented Framework for Evidence-Based Counterspeech Against Health Misinformation
作者: Anirban Saha Anik, Xiaoying Song, Elliott Wang, Bryan Wang, Bengisu Yarimbas, Lingzi Hong
分类: cs.CL
发布日期: 2025-07-09 (更新: 2025-07-27)
备注: Accepted for publication at COLM 2025
期刊: Second Conference on Language Modeling (COLM 2025)
💡 一句话要点
提出多智能体检索增强框架,用于生成针对健康虚假信息的循证反驳言论
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反驳言论生成 健康虚假信息 多智能体系统 检索增强生成 大型语言模型
📋 核心要点
- 现有方法在生成反驳虚假信息的言论时,依赖的证据有限,且对最终输出的控制较弱。
- 论文提出多智能体检索增强框架,利用多个LLM协同优化知识检索、证据增强和响应优化,提升反驳言论质量。
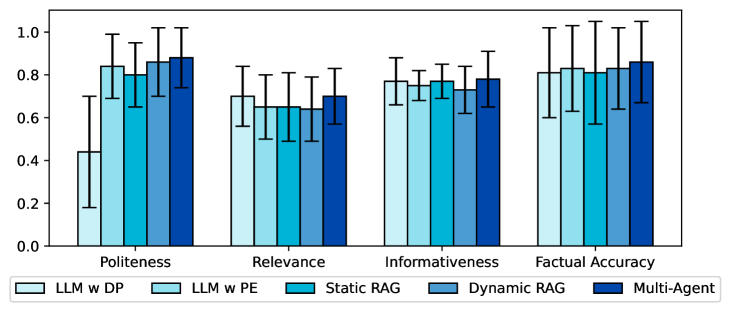
- 实验表明,该方法在多个指标上优于基线,且具有良好的泛化能力,人工评估也显示了其优越性。
📝 摘要(中文)
本文提出了一种多智能体检索增强框架,用于生成针对健康虚假信息的反驳言论。该框架结合了多个大型语言模型(LLMs),以优化知识检索、证据增强和响应优化。该方法整合了静态和动态证据,确保生成的反驳言论具有相关性、充分的事实依据和时效性。实验结果表明,该方法在礼貌性、相关性、信息量和事实准确性方面均优于基线方法,证明了其在生成高质量反驳言论方面的有效性。此外,消融研究验证了框架中每个组件的必要性。交叉评估表明,该系统可以很好地推广到不同的健康虚假信息主题和数据集。人工评估表明,优化显著提高了反驳言论的质量,并获得了人类偏好。
🔬 方法详解
问题定义:论文旨在解决健康领域虚假信息泛滥的问题,现有方法生成的反驳言论证据不足、质量不高,且缺乏对生成过程的有效控制。这使得反驳言论的说服力和可信度受到影响,难以有效对抗虚假信息的传播。
核心思路:论文的核心思路是利用多智能体协作的方式,将反驳言论的生成过程分解为知识检索、证据增强和响应优化三个阶段,并分别由不同的LLM智能体负责。通过这种方式,可以充分利用每个智能体的优势,提高反驳言论的质量和可控性。同时,整合静态和动态证据,确保反驳言论的时效性和准确性。
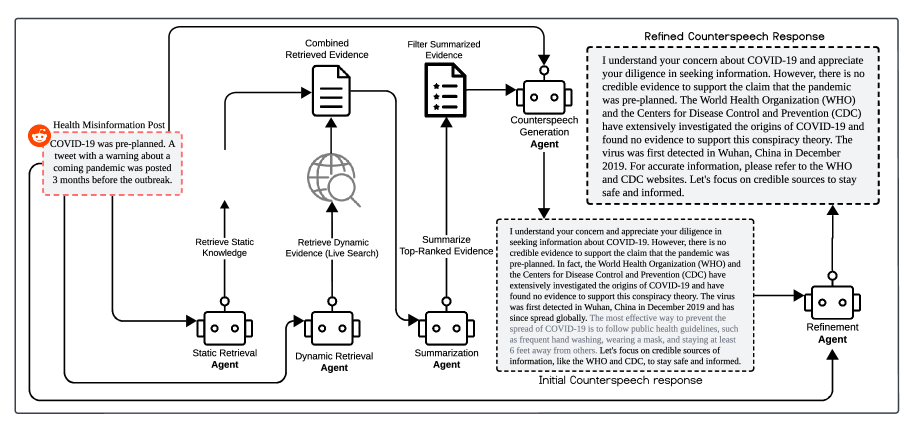
技术框架:该框架包含以下主要模块:1) 知识检索智能体:负责从知识库中检索与虚假信息相关的证据。2) 证据增强智能体:负责对检索到的证据进行增强,例如补充背景信息、引用权威来源等。3) 响应优化智能体:负责根据增强后的证据生成最终的反驳言论,并进行润色和优化。框架整合静态知识库(例如维基百科)和动态信息源(例如新闻报道),以确保证据的时效性。
关键创新:该方法的主要创新点在于多智能体协作框架的设计,它将反驳言论的生成过程分解为多个阶段,并由不同的LLM智能体负责。这种设计可以充分利用每个智能体的优势,提高反驳言论的质量和可控性。此外,整合静态和动态证据也是一个重要的创新点,它可以确保反驳言论的时效性和准确性。与现有方法相比,该方法更加灵活和可扩展,可以适应不同的虚假信息类型和场景。
关键设计:论文中使用了多个LLM,具体型号未知。知识检索智能体可能使用了基于向量相似度的检索方法,证据增强智能体可能使用了提示工程(Prompt Engineering)技术,响应优化智能体可能使用了强化学习或微调技术。具体的参数设置、损失函数和网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
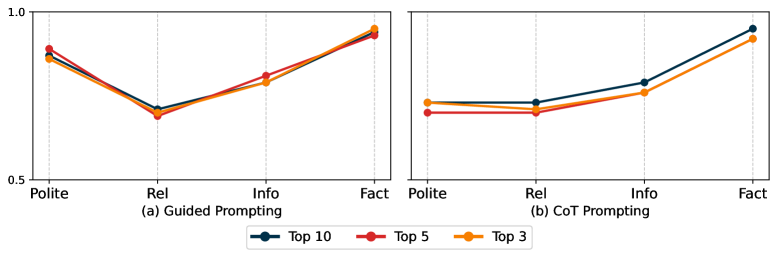
实验结果表明,该方法在礼貌性、相关性、信息量和事实准确性方面均优于基线方法。消融研究验证了框架中每个组件的必要性。交叉评估表明,该系统可以很好地推广到不同的健康虚假信息主题和数据集。人工评估表明,优化显著提高了反驳言论的质量,并获得了人类偏好。具体提升幅度未知。
🎯 应用场景
该研究成果可应用于社交媒体平台、在线健康社区等场景,用于自动生成针对健康虚假信息的反驳言论,提高公众对健康信息的辨别能力,减少虚假信息对个人和社会造成的危害。未来,该技术还可以扩展到其他领域的虚假信息对抗,例如政治、经济等。
📄 摘要(原文)
Large language models (LLMs) incorporated with Retrieval-Augmented Generation (RAG) have demonstrated powerful capabilities in generating counterspeech against misinformation. However, current studies rely on limited evidence and offer less control over final outputs. To address these challenges, we propose a Multi-agent Retrieval-Augmented Framework to generate counterspeech against health misinformation, incorporating multiple LLMs to optimize knowledge retrieval, evidence enhancement, and response refinement. Our approach integrates both static and dynamic evidence, ensuring that the generated counterspeech is relevant, well-grounded, and up-to-date. Our method outperforms baseline approaches in politeness, relevance, informativeness, and factual accuracy, demonstrating its effectiveness in generating high-quality counterspeech. To further validate our approach, we conduct ablation studies to verify the necessity of each component in our framework. Furthermore, cross evaluations show that our system generalizes well across diverse health misinformation topics and datasets. And human evaluations reveal that refinement significantly enhances counterspeech quality and obtains human preference.