A Language-Driven Framework for Improving Personalized Recommendations: Merging LLMs with Traditional Algorithms
作者: Aaron Goldstein, Ayan Dutta
分类: cs.IR, cs.CL, cs.LG
发布日期: 2025-07-09
💡 一句话要点
提出融合LLM的个性化推荐框架,提升传统算法对文本偏好的理解
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化推荐 大型语言模型 自然语言处理 奇异值分解 SVD++ 文本偏好 电影推荐
📋 核心要点
- 现有推荐算法难以理解和利用用户通过自然语言表达的个性化偏好。
- 利用LLM理解用户文本偏好,并融合到传统推荐算法的输出中,实现更精准的推荐。
- 实验表明,该框架在多个指标上显著优于传统SVD和SVD++算法,尽管计算成本略有增加。
📝 摘要(中文)
传统推荐算法无法根据用户提供的文本偏好进行个性化推荐,例如“我喜欢轻松幽默的喜剧”。近年来,大型语言模型(LLM)已成为自然语言处理领域最有前途的工具之一。本研究提出了一种新颖的框架,模拟密友根据对个人品味的了解来推荐项目的方式。我们利用LLM来增强电影推荐系统,通过改进传统算法的输出,并将其与基于语言的用户偏好输入相结合。我们采用奇异值分解(SVD)或SVD++算法来生成初始电影推荐,使用Surprise Python库实现,并在MovieLens-Latest-Small数据集上进行训练。我们使用留一法验证命中率和累积命中率来比较基础算法与LLM增强版本的性能。此外,为了将我们的框架与当前最先进的推荐系统进行比较,我们使用基于项目的分层0.75训练集和0.25测试集分割的评分和排名指标。我们的框架可以根据用户喜欢的电影自动生成偏好配置文件,或者允许手动指定偏好以获得更个性化的结果。使用自动化方法,我们的框架在使用的每个评估指标上都大大超过了SVD和SVD++(例如,累积命中率提高了约6倍,NDCG提高了约3.7倍等),但计算开销略有增加。
🔬 方法详解
问题定义:论文旨在解决传统推荐算法无法有效利用用户通过自然语言表达的个性化偏好这一问题。现有方法主要依赖于用户历史行为数据,难以理解用户深层次的偏好,例如用户对电影风格、演员、剧情等方面的具体要求。这导致推荐结果缺乏个性化,用户满意度不高。
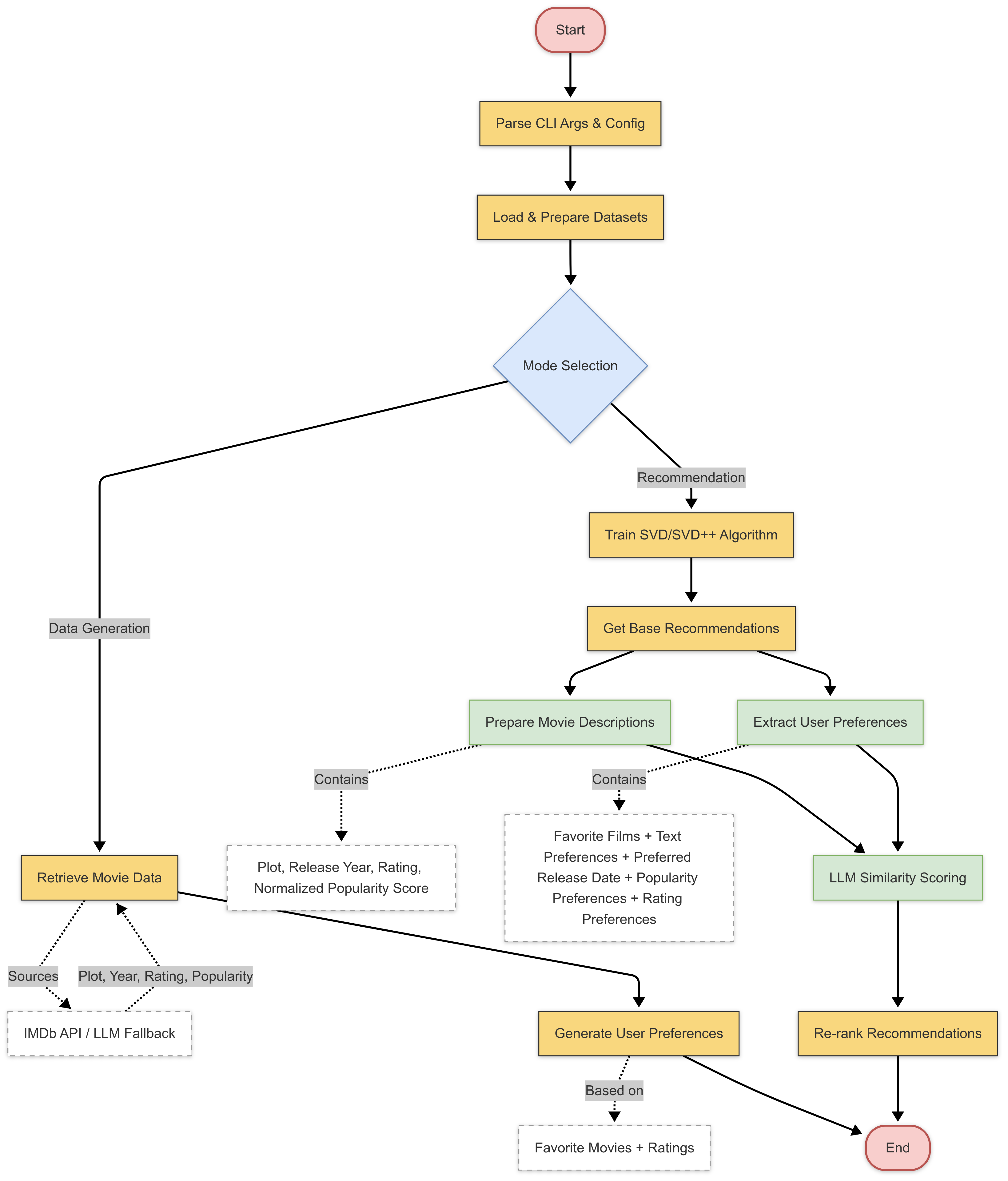
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的自然语言理解能力,将用户的文本偏好融入到推荐过程中。通过LLM理解用户偏好的语义信息,并将其与传统推荐算法的输出相结合,从而实现更精准、个性化的推荐。这种方法模拟了朋友之间基于对彼此了解进行推荐的方式。
技术框架:整体框架包含以下几个主要阶段:1) 用户偏好输入:用户可以通过文本描述自己的电影偏好,或者系统根据用户喜欢的电影自动生成偏好配置文件。2) 传统推荐算法:使用奇异值分解(SVD)或SVD++算法生成初始电影推荐列表。3) LLM增强:利用LLM理解用户偏好,并对初始推荐列表进行排序和过滤,选择更符合用户偏好的电影。4) 输出推荐结果:将LLM增强后的推荐列表呈现给用户。
关键创新:最重要的技术创新点在于将LLM与传统推荐算法相结合,利用LLM的自然语言理解能力来提升推荐系统的个性化程度。与现有方法相比,该框架能够更好地理解用户的文本偏好,并将其融入到推荐过程中,从而实现更精准的推荐。
关键设计:论文中没有详细描述LLM的具体选择和训练细节。关键设计可能包括:1) 如何将用户文本偏好转化为LLM可以理解的输入格式。2) 如何利用LLM对初始推荐列表进行排序和过滤。3) 如何平衡LLM的计算成本和推荐效果。论文使用了留一法验证命中率和累积命中率,以及基于项目的分层训练/测试集分割来评估模型性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在多个评估指标上显著优于传统的SVD和SVD++算法。例如,累积命中率提高了约6倍,NDCG提高了约3.7倍。这表明LLM在提升推荐系统个性化方面具有显著优势。虽然计算开销略有增加,但推荐效果的提升足以弥补这一不足。
🎯 应用场景
该研究成果可应用于各种需要个性化推荐的场景,例如电影、音乐、书籍、商品等。通过理解用户的文本偏好,可以提供更精准、个性化的推荐服务,提升用户体验和满意度。未来,该方法还可以扩展到其他领域,例如教育、医疗等,为用户提供更智能化的服务。
📄 摘要(原文)
Traditional recommendation algorithms are not designed to provide personalized recommendations based on user preferences provided through text, e.g., "I enjoy light-hearted comedies with a lot of humor". Large Language Models (LLMs) have emerged as one of the most promising tools for natural language processing in recent years. This research proposes a novel framework that mimics how a close friend would recommend items based on their knowledge of an individual's tastes. We leverage LLMs to enhance movie recommendation systems by refining traditional algorithm outputs and integrating them with language-based user preference inputs. We employ Singular Value Decomposition (SVD) or SVD++ algorithms to generate initial movie recommendations, implemented using the Surprise Python library and trained on the MovieLens-Latest-Small dataset. We compare the performance of the base algorithms with our LLM-enhanced versions using leave-one-out validation hit rates and cumulative hit rates. Additionally, to compare the performance of our framework against the current state-of-the-art recommendation systems, we use rating and ranking metrics with an item-based stratified 0.75 train, 0.25 test split. Our framework can generate preference profiles automatically based on users' favorite movies or allow manual preference specification for more personalized results. Using an automated approach, our framework overwhelmingly surpassed SVD and SVD++ on every evaluation metric used (e.g., improvements of up to ~6x in cumulative hit rate, ~3.7x in NDCG, etc.), albeit at the cost of a slight increase in computational overhead.