SynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
作者: Krithika Ramesh, Daniel Smolyak, Zihao Zhao, Nupoor Gandhi, Ritu Agarwal, Margrét Bjarnadóttir, Anjalie Field
分类: cs.CL
发布日期: 2025-07-09 (更新: 2025-11-03)
备注: EMNLP 2025 System Demonstration
💡 一句话要点
SynthTextEval:面向高风险领域的合成文本生成与评估工具包
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成文本 数据生成 隐私保护 AI评估 高风险领域
📋 核心要点
- 现有方法缺乏对合成文本在下游任务中的效用、公平性、隐私风险等多维度的综合评估。
- SynthTextEval工具包通过提供生成和评估模块,支持用户自定义合成数据并进行多维度评估。
- 该工具包在医疗保健和法律等高风险领域的数据集上进行了验证,展示了其功能和有效性。
📝 摘要(中文)
本文介绍SynthTextEval,一个用于全面评估合成文本的工具包。大型语言模型(LLM)输出的流畅性使得合成文本在许多应用中具有潜在可行性,例如降低在高风险领域开发和部署AI系统时隐私泄露的风险。然而,实现这一潜力需要在多个维度上对合成数据进行有原则且一致的评估:其在下游系统中的效用、这些系统的公平性、隐私泄露的风险、与源文本的一般分布差异以及领域专家的定性反馈。SynthTextEval允许用户对他们上传或使用工具包的生成模块生成的合成数据进行所有这些维度的评估。虽然我们的工具包可以运行在任何数据上,但我们重点介绍了它在两个高风险领域(医疗保健和法律)的数据集上的功能和有效性。通过整合和标准化评估指标,我们旨在提高合成文本的可行性,进而提高AI开发中的隐私保护。
🔬 方法详解
问题定义:目前缺乏一个统一的、多维度的合成文本评估框架,尤其是在医疗和法律等高风险领域。现有方法通常只关注单一指标,无法全面衡量合成数据的质量、效用、公平性和隐私风险。这阻碍了合成文本在实际应用中的可靠部署。
核心思路:SynthTextEval的核心思路是提供一个全面的工具包,允许用户生成合成文本,并从多个维度对其进行评估。通过整合多种评估指标,包括下游任务性能、公平性指标、隐私泄露风险等,SynthTextEval旨在提供对合成数据质量的整体视图。这样可以帮助研究人员和开发人员更好地理解合成数据的优缺点,并选择最适合其特定需求的合成数据生成方法。
技术框架:SynthTextEval包含两个主要模块:生成模块和评估模块。生成模块允许用户使用各种合成数据生成技术生成文本。评估模块则提供了一系列评估指标,用于衡量合成数据的质量、效用、公平性和隐私风险。用户可以上传自己的数据或使用工具包内置的生成模块生成数据,然后使用评估模块进行多维度评估。整个流程旨在简化合成数据的生成和评估过程,并提供标准化的评估指标。
关键创新:SynthTextEval的关键创新在于其综合性的评估框架,该框架涵盖了合成数据的多个重要维度,而不仅仅是传统的文本质量指标。此外,该工具包还提供了易于使用的界面和标准化的评估流程,使得研究人员和开发人员可以轻松地生成和评估合成数据。这种综合性和易用性使得SynthTextEval成为一个有价值的工具,可以促进合成数据在各个领域的应用。
关键设计:SynthTextEval的关键设计包括:1) 多样化的评估指标,涵盖效用、公平性、隐私等多个维度;2) 模块化的架构,允许用户轻松添加新的生成方法和评估指标;3) 用户友好的界面,简化了合成数据的生成和评估过程;4) 针对高风险领域(如医疗和法律)的特定评估指标和数据集。
🖼️ 关键图片

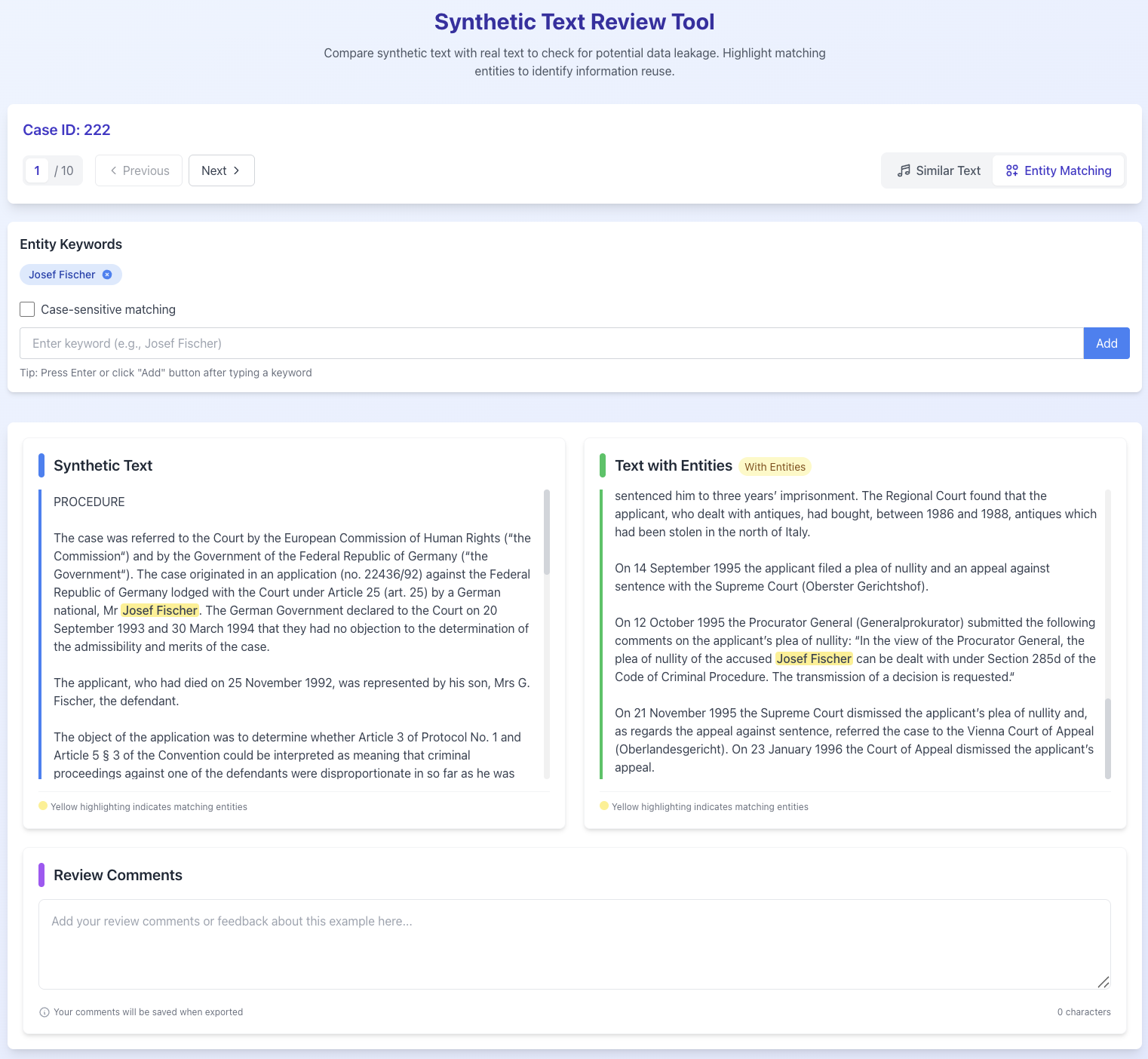

📊 实验亮点
SynthTextEval在医疗和法律领域的数据集上进行了实验验证,展示了其在评估合成数据质量、效用、公平性和隐私风险方面的有效性。该工具包提供了一系列标准化的评估指标,并允许用户自定义评估流程,从而提高了合成数据评估的效率和可靠性。具体性能数据未知,但论文强调了工具包的功能和有效性。
🎯 应用场景
SynthTextEval可广泛应用于需要隐私保护的AI系统开发,尤其是在医疗、法律等高风险领域。通过生成和评估合成数据,可以降低真实数据的使用风险,同时保证AI模型的性能和公平性。该工具包有助于推动合成数据在各个领域的应用,并促进AI技术的安全可靠发展。
📄 摘要(原文)
We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.