Prompt Perturbations Reveal Human-Like Biases in Large Language Model Survey Responses
作者: Jens Rupprecht, Georg Ahnert, Markus Strohmaier
分类: cs.CL, cs.AI, cs.CY
发布日期: 2025-07-09 (更新: 2025-10-16)
💡 一句话要点
提示扰动揭示大型语言模型在调查问卷中类人的偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 调查问卷 提示工程 偏差分析 社会科学
📋 核心要点
- 现有研究缺乏对大型语言模型在社会调查中类人偏差的系统评估,无法保证其可靠性。
- 通过对问题和答案选项进行扰动,评估LLMs在世界价值观调查问题上的反应稳健性,揭示其偏差。
- 实验表明,LLMs存在近因偏差,且对语义变化和组合扰动敏感,提示设计至关重要。
📝 摘要(中文)
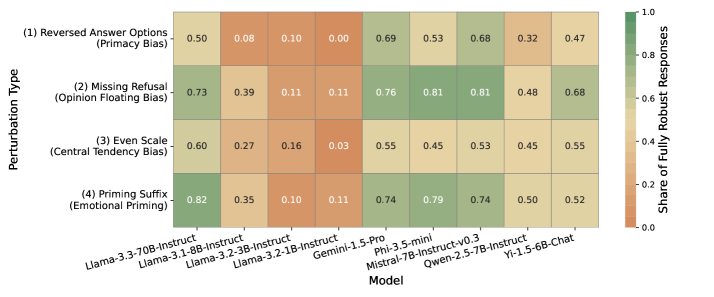
大型语言模型(LLMs)越来越多地被用作社会科学调查中人类受试者的替代品,但它们在应对中心倾向、意见漂浮和首因效应等已知类人反应偏差时的可靠性和敏感性尚不清楚。本研究调查了LLMs在规范性调查环境中的反应稳健性,我们使用来自世界价值观调查(WVS)的问题,对九个LLMs进行了测试,并对问题措辞和答案选项结构应用了一套全面的十种扰动,从而模拟了超过167,000次调查访谈。通过这样做,我们不仅揭示了LLMs对扰动的脆弱性,还表明所有测试模型都表现出一致的近因偏差,不成比例地偏爱最后呈现的答案选项。虽然较大的模型通常更稳健,但所有模型仍然对释义等语义变化和组合扰动敏感。这强调了在使用LLMs生成合成调查数据时,提示设计和稳健性测试的关键重要性。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLMs)在作为社会科学调查的代理时,是否会表现出与人类相似的反应偏差,例如中心倾向、意见漂浮和首因效应。现有方法缺乏对LLMs在这些方面的系统评估,无法保证其在模拟人类受试者时的可靠性。论文关注的痛点是LLMs可能存在的偏差会影响调查结果的准确性,从而误导社会科学研究。
核心思路:论文的核心思路是通过对调查问卷的提示(prompt)进行系统性的扰动,观察LLMs的反应变化,从而揭示其潜在的偏差。这种方法模拟了真实世界中调查问卷可能存在的各种变化,例如问题措辞的细微差异、答案选项的顺序变化等。通过分析LLMs在不同扰动下的反应模式,可以推断出其对特定偏差的敏感程度。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择世界价值观调查(WVS)中的问题作为测试用例;2) 选择九个不同的LLMs进行测试;3) 设计一套全面的十种扰动,包括问题措辞的释义、答案选项顺序的改变、增加噪音等;4) 对每个LLM在不同的扰动下进行多次模拟调查访谈;5) 分析LLMs的反应数据,识别其存在的偏差。
关键创新:该论文最重要的技术创新点在于其系统性的提示扰动方法。与以往的研究不同,该论文没有仅仅关注LLMs在原始问题上的表现,而是通过引入多种扰动来模拟真实世界中调查问卷可能存在的各种变化。这种方法可以更全面地评估LLMs的稳健性和可靠性,并揭示其潜在的偏差。
关键设计:论文的关键设计包括:1) 选择了具有代表性的世界价值观调查(WVS)问题;2) 设计了十种不同的扰动,涵盖了问题措辞、答案选项结构等多个方面;3) 对每个LLM进行了大量的模拟调查访谈,以保证数据的统计有效性;4) 使用统计方法分析了LLMs的反应数据,识别其存在的偏差,例如近因偏差。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所有测试的LLMs都表现出一致的近因偏差,即不成比例地偏爱最后呈现的答案选项。虽然较大的模型通常更稳健,但所有模型仍然对释义等语义变化和组合扰动敏感。例如,在某些情况下,LLMs对问题释义的反应变化高达20%。
🎯 应用场景
该研究成果可应用于社会科学、市场调研等领域,帮助研究人员更准确地评估LLMs作为调查代理的可靠性。通过了解LLMs的偏差,可以设计更有效的提示,减少偏差对调查结果的影响。未来,该研究可促进LLMs在社会科学研究中的更广泛应用,并推动开发更稳健、更可靠的LLMs。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly used as proxies for human subjects in social science surveys, but their reliability and susceptibility to known human-like response biases, such as central tendency, opinion floating and primacy bias are poorly understood. This work investigates the response robustness of LLMs in normative survey contexts, we test nine LLMs on questions from the World Values Survey (WVS), applying a comprehensive set of ten perturbations to both question phrasing and answer option structure, resulting in over 167,000 simulated survey interviews. In doing so, we not only reveal LLMs' vulnerabilities to perturbations but also show that all tested models exhibit a consistent recency bias, disproportionately favoring the last-presented answer option. While larger models are generally more robust, all models remain sensitive to semantic variations like paraphrasing and to combined perturbations. This underscores the critical importance of prompt design and robustness testing when using LLMs to generate synthetic survey data.