Rethinking Verification for LLM Code Generation: From Generation to Testing
作者: Zihan Ma, Taolin Zhang, Maosong Cao, Junnan Liu, Wenwei Zhang, Minnan Luo, Songyang Zhang, Kai Chen
分类: cs.CL
发布日期: 2025-07-09 (更新: 2025-07-10)
💡 一句话要点
提出SAGA框架,提升LLM代码生成测试用例的覆盖率和质量,改进代码评估。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代码生成 测试用例生成 人-LLM协作 代码评估 强化学习 自动化测试 软件质量保证
📋 核心要点
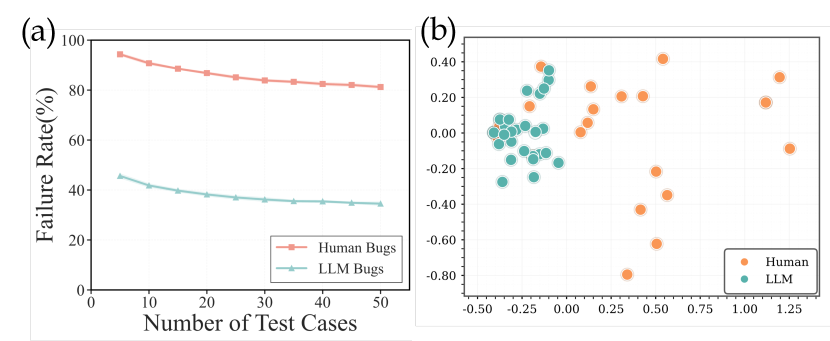
- 现有代码生成评估基准测试用例数量有限且同质化,导致LLM代码中存在的细微错误难以被有效检测。
- 提出人-LLM协作方法SAGA,结合人类编程知识和LLM推理能力,生成更全面、高质量的测试用例。
- 实验结果表明,SAGA显著提高了测试用例的检测率和验证器准确率,优于现有基准测试集。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成基准测试(如HumanEval和LiveCodeBench)中取得了显著成功。然而,这些评估套件通常只包含有限数量的同质测试用例,导致细微的错误无法被检测到。这不仅人为地夸大了性能,还损害了强化学习框架中可验证奖励(RLVR)的准确奖励估计。为了解决这些关键缺陷,本文系统地研究了测试用例生成(TCG)任务,提出了多维指标来严格量化测试套件的彻底性。此外,本文还引入了一种人-LLM协作方法(SAGA),利用人类编程专业知识和LLM推理能力,旨在显著提高生成测试用例的覆盖率和质量。此外,本文开发了一个TCGBench来促进TCG任务的研究。实验表明,SAGA在TCGBench上实现了90.62%的检测率和32.58%的验证器准确率。SAGA合成的代码生成评估基准的验证器准确率比LiveCodeBench-v6高10.78%。这些结果证明了本文提出方法的有效性。希望这项工作有助于为可靠的LLM代码评估构建可扩展的基础,进一步推进代码生成中的RLVR,并为自动对抗性测试合成和自适应基准集成铺平道路。
🔬 方法详解
问题定义:论文旨在解决LLM代码生成评估中测试用例不足的问题。现有评估基准(如HumanEval和LiveCodeBench)的测试用例数量有限且同质化,难以充分覆盖LLM生成的代码中存在的各种错误,导致评估结果不准确,并影响基于可验证奖励的强化学习效果。
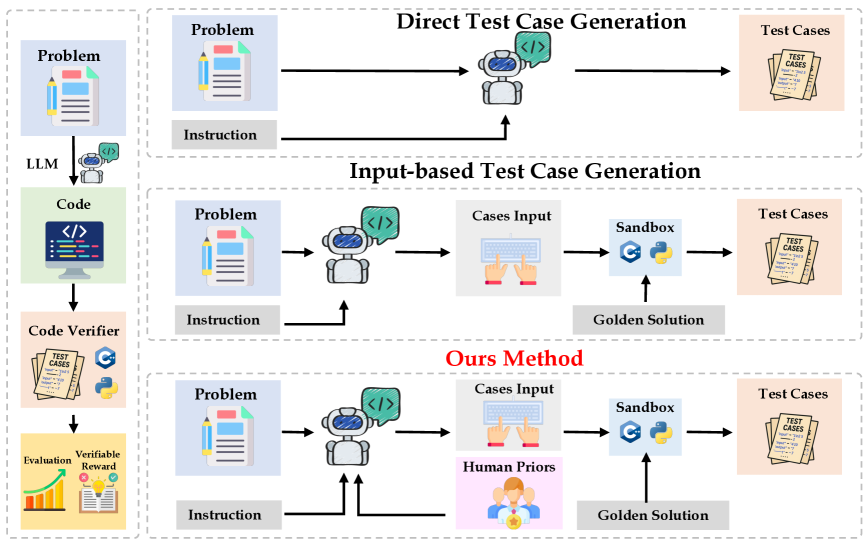
核心思路:论文的核心思路是利用人类的编程经验和LLM的推理能力,通过人-LLM协作的方式生成更全面、更高质量的测试用例。这种方法旨在弥补现有测试用例的不足,提高代码评估的准确性和可靠性。
技术框架:论文提出了名为SAGA的人-LLM协作框架,其主要流程包括:首先,由人类专家提供初始测试用例和测试目标;然后,LLM基于这些信息生成更多的测试用例;接着,人类专家对LLM生成的测试用例进行审查和修改,确保其质量和有效性;最后,将这些测试用例添加到测试集中,用于评估LLM生成的代码。此外,论文还提出了多维指标来量化测试套件的彻底性。
关键创新:SAGA的关键创新在于其人-LLM协作的模式。与完全依赖LLM自动生成测试用例的方法相比,SAGA结合了人类的专业知识和LLM的推理能力,能够生成更具针对性和多样性的测试用例,从而更有效地检测LLM代码中的错误。与完全依赖人工生成测试用例的方法相比,SAGA利用LLM的生成能力,可以显著提高测试用例的生成效率。
关键设计:SAGA的关键设计包括:(1) 人类专家提供的初始测试用例和测试目标,这些信息为LLM生成测试用例提供了指导。(2) LLM生成测试用例时使用的提示工程(Prompt Engineering)技术,通过精心设计的提示,引导LLM生成符合要求的测试用例。(3) 人类专家对LLM生成的测试用例进行审查和修改的机制,确保测试用例的质量和有效性。(4) 多维指标,用于量化测试套件的彻底性,例如覆盖率、多样性等。
🖼️ 关键图片
📊 实验亮点
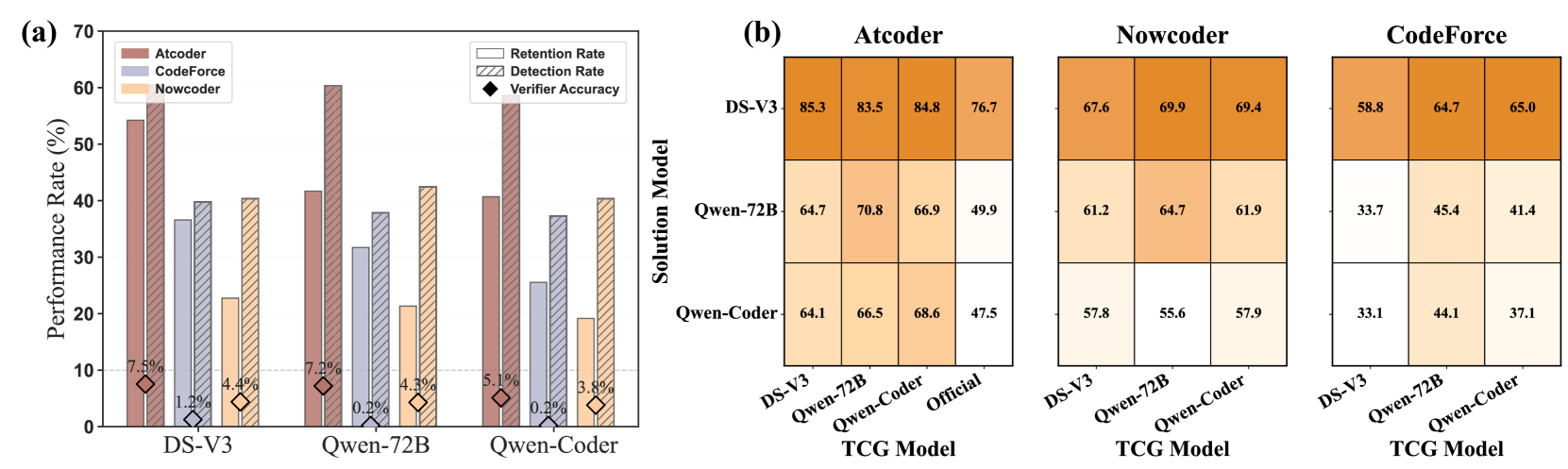
SAGA在TCGBench上实现了90.62%的错误检测率和32.58%的验证器准确率。使用SAGA生成的测试用例评估LLM代码生成模型时,验证器准确率比使用LiveCodeBench-v6高10.78%。这些结果表明SAGA能够有效提高测试用例的质量和代码评估的准确性。
🎯 应用场景
该研究成果可应用于LLM代码生成模型的评估和改进,提高代码质量和可靠性。此外,该方法还可用于构建更有效的强化学习奖励函数,从而提升LLM代码生成模型的训练效果。未来,该研究可扩展到其他类型的代码生成任务,并应用于自动化测试和软件质量保证等领域。
📄 摘要(原文)
Large language models (LLMs) have recently achieved notable success in code-generation benchmarks such as HumanEval and LiveCodeBench. However, a detailed examination reveals that these evaluation suites often comprise only a limited number of homogeneous test cases, resulting in subtle faults going undetected. This not only artificially inflates measured performance but also compromises accurate reward estimation in reinforcement learning frameworks utilizing verifiable rewards (RLVR). To address these critical shortcomings, we systematically investigate the test-case generation (TCG) task by proposing multi-dimensional metrics designed to rigorously quantify test-suite thoroughness. Furthermore, we introduce a human-LLM collaborative method (SAGA), leveraging human programming expertise with LLM reasoning capability, aimed at significantly enhancing both the coverage and the quality of generated test cases. In addition, we develop a TCGBench to facilitate the study of the TCG task. Experiments show that SAGA achieves a detection rate of 90.62% and a verifier accuracy of 32.58% on TCGBench. The Verifier Accuracy (Verifier Acc) of the code generation evaluation benchmark synthesized by SAGA is 10.78% higher than that of LiveCodeBench-v6. These results demonstrate the effectiveness of our proposed method. We hope this work contributes to building a scalable foundation for reliable LLM code evaluation, further advancing RLVR in code generation, and paving the way for automated adversarial test synthesis and adaptive benchmark integration.