Checklist Engineering Empowers Multilingual LLM Judges
作者: Mohammad Ghiasvand Mohammadkhani, Hamid Beigy
分类: cs.CL
发布日期: 2025-07-09 (更新: 2025-07-27)
💡 一句话要点
提出基于清单工程的CE-Judge框架,赋能多语言LLM评估任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 多语言处理 清单工程 零样本学习 文本评估
📋 核心要点
- 现有LLM评估方法在多语言场景下依赖专有模型或大量微调数据,存在成本和效率问题。
- 论文提出CE-Judge框架,利用清单工程和开源模型,无需训练即可实现多语言文本评估。
- 实验结果表明,CE-Judge在多个语言和数据集上超越基线,性能媲美GPT-4o。
📝 摘要(中文)
自动文本评估一直是自然语言处理(NLP)的核心问题。最近,该领域已转向使用大型语言模型(LLM)作为评估器,这种趋势被称为“LLM-as-a-Judge”范式。虽然这种方法很有前景且易于跨任务调整,但在多语言环境中的探索有限。现有的多语言研究通常依赖于专有模型或需要大量的训练数据进行微调,这引发了对成本、时间和效率的担忧。在本文中,我们提出了一种基于清单工程的LLM-as-a-Judge(CE-Judge)框架,该框架使用清单直觉进行多语言评估,且无需训练,并使用开源模型。在多种语言和三个基准数据集上的实验表明,在逐点和成对设置下,我们的方法通常优于基线,并且与GPT-4o模型表现相当。
🔬 方法详解
问题定义:论文旨在解决多语言环境下,利用LLM进行文本自动评估时,对专有模型和大量训练数据的依赖问题。现有方法的痛点在于成本高昂、效率低下,并且难以适应不同语言和评估标准。
核心思路:论文的核心思路是借鉴软件测试中的“清单测试”思想,将复杂的评估任务分解为一系列可量化的检查点(checklist)。通过预定义的清单,引导LLM对文本进行更细粒度、更客观的评估,从而提高评估的准确性和一致性。这种方法避免了对LLM进行微调,降低了成本和时间开销。
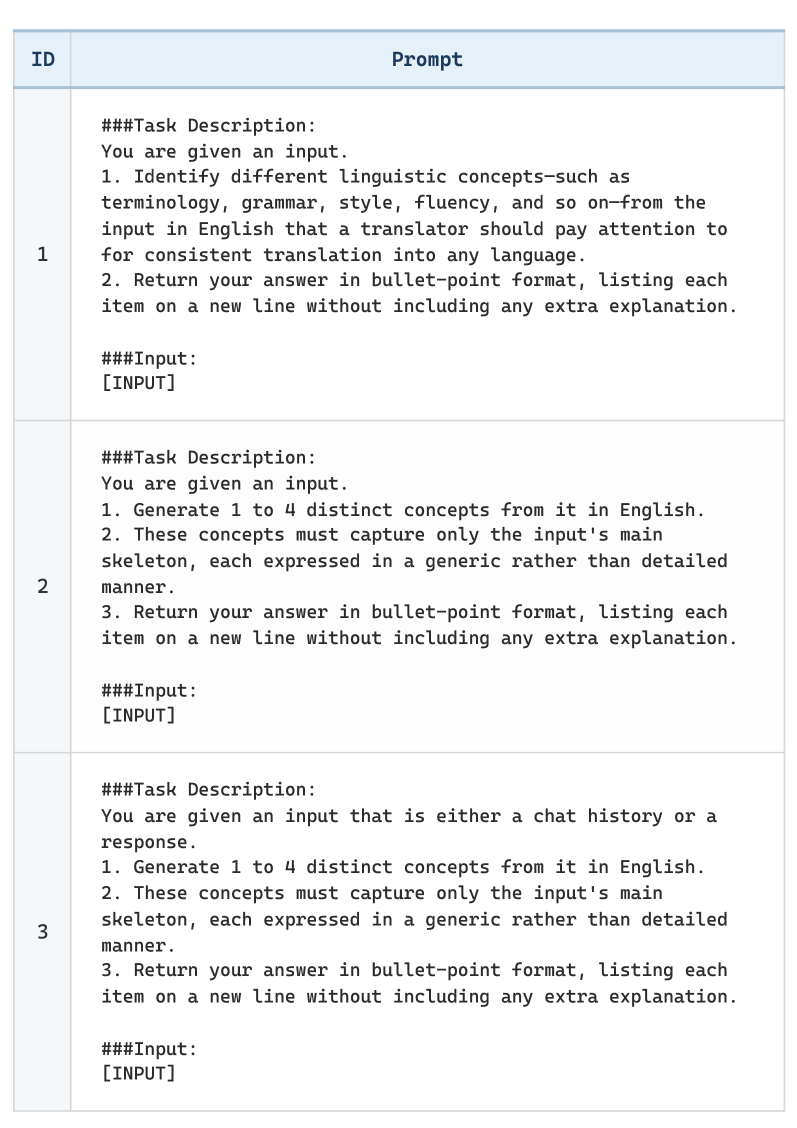
技术框架:CE-Judge框架主要包含以下几个阶段:1) 清单设计:根据具体的评估任务,人工设计一份包含多个检查点的清单。每个检查点对应一个特定的评估维度或标准。2) 提示工程:将待评估文本和清单作为输入,通过精心设计的提示语,引导LLM逐一检查清单上的每个项目。3) LLM评估:利用开源LLM(例如LLaMA、Mistral等)对文本进行评估,并根据清单上的检查结果给出相应的评分或判断。4) 结果汇总:将LLM对每个检查点的评估结果进行汇总,得到最终的评估结果。
关键创新:CE-Judge的关键创新在于将清单工程的思想引入到LLM评估中,从而实现了无需训练的多语言文本评估。与传统的微调方法相比,CE-Judge具有更高的效率和更低的成本。此外,CE-Judge通过清单的方式,提高了评估的可解释性和可控性。
关键设计:清单的设计是CE-Judge的关键。清单需要根据具体的评估任务进行定制,并尽可能覆盖所有重要的评估维度。提示工程也至关重要,需要设计清晰、明确的提示语,引导LLM正确理解清单上的每个项目。论文中可能还涉及一些超参数的调整,例如LLM的温度系数等,以控制LLM的生成风格和评估结果的稳定性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CE-Judge在多个语言(包括英语、中文、西班牙语等)和三个基准数据集上,均取得了优于基线的性能。在某些情况下,CE-Judge的性能甚至可以与GPT-4o模型相媲美,这表明CE-Judge具有很强的竞争力。此外,实验还验证了CE-Judge在逐点和成对设置下的有效性。
🎯 应用场景
CE-Judge框架可广泛应用于多语言文本评估领域,例如机器翻译质量评估、文本摘要质量评估、问答系统评估等。该方法降低了多语言评估的成本和门槛,有助于推动多语言自然语言处理技术的发展。未来,可以将CE-Judge应用于更复杂的评估任务,例如代码生成质量评估、图像描述质量评估等。
📄 摘要(原文)
Automated text evaluation has long been a central issue in Natural Language Processing (NLP). Recently, the field has shifted toward using Large Language Models (LLMs) as evaluators-a trend known as the LLM-as-a-Judge paradigm. While promising and easily adaptable across tasks, this approach has seen limited exploration in multilingual contexts. Existing multilingual studies often rely on proprietary models or require extensive training data for fine-tuning, raising concerns about cost, time, and efficiency. In this paper, we propose Checklist Engineering based LLM-as-a-Judge (CE-Judge), a training-free framework that uses checklist intuition for multilingual evaluation with an open-source model. Experiments across multiple languages and three benchmark datasets, under both pointwise and pairwise settings, show that our method generally surpasses the baselines and performs on par with the GPT-4o model.