Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
作者: Liliang Ren, Congcong Chen, Haoran Xu, Young Jin Kim, Adam Atkinson, Zheng Zhan, Jiankai Sun, Baolin Peng, Liyuan Liu, Shuohang Wang, Hao Cheng, Jianfeng Gao, Weizhu Chen, Yelong Shen
分类: cs.CL, cs.LG
发布日期: 2025-07-09 (更新: 2025-10-25)
备注: Accepted by NeurIPS 2025. Camera-ready Version
🔗 代码/项目: GITHUB
💡 一句话要点
提出SambaY:一种高效的Decoder-Hybrid-Decoder架构,用于长文本生成推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 长文本生成 状态空间模型 解码效率 记忆共享 门控记忆单元 Decoder-Hybrid-Decoder 推理加速 大规模语言模型
📋 核心要点
- 现有混合架构在语言建模中表现出潜力,但缺乏对SSM层间表示共享效率的深入研究。
- 引入门控记忆单元(GMU)实现跨层记忆共享,构建SambaY架构,提升解码效率和长文本性能。
- 实验表明,SambaY在推理任务上优于现有模型,并显著提升了解码吞吐量,无需强化学习。
📝 摘要(中文)
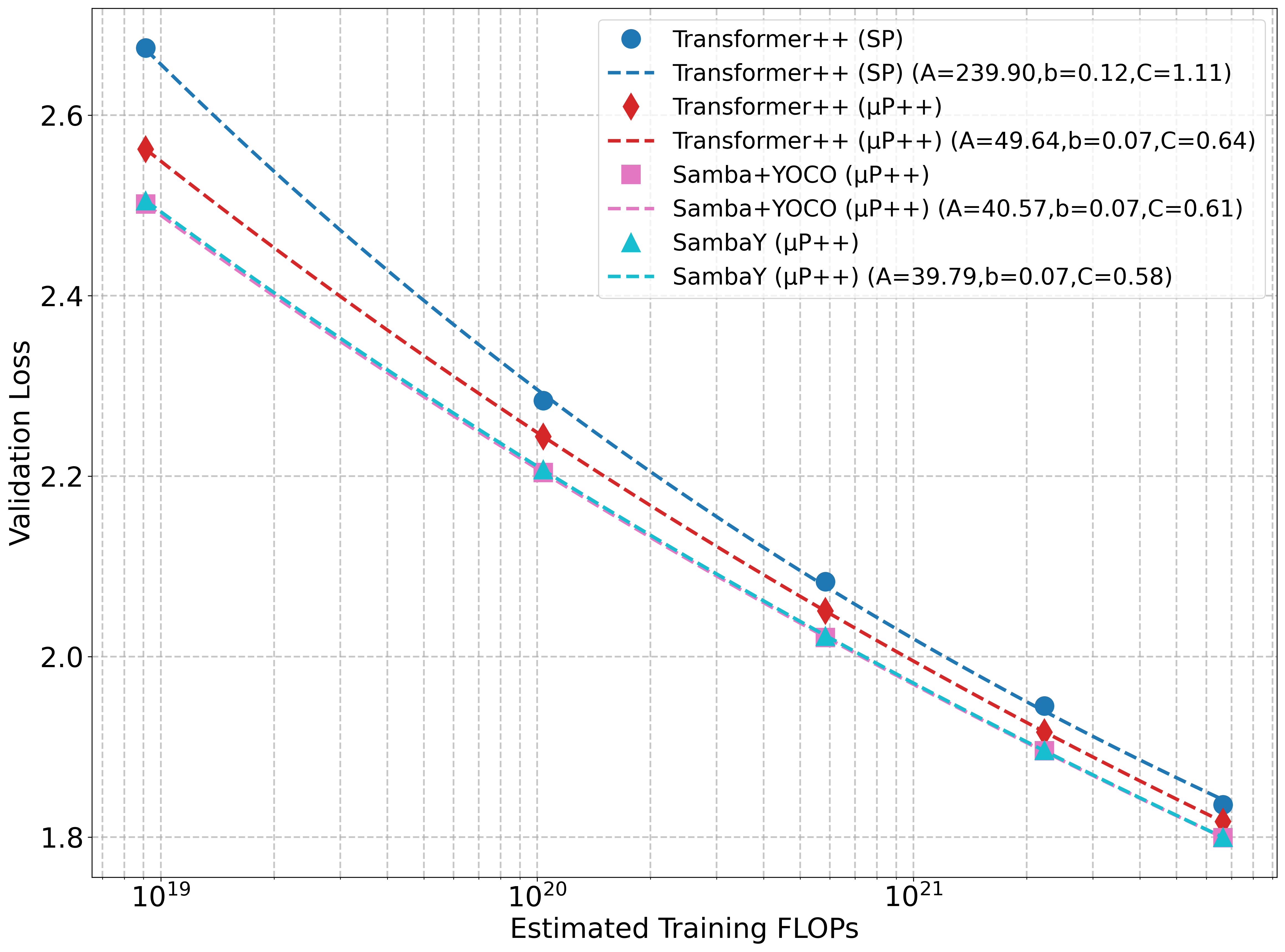
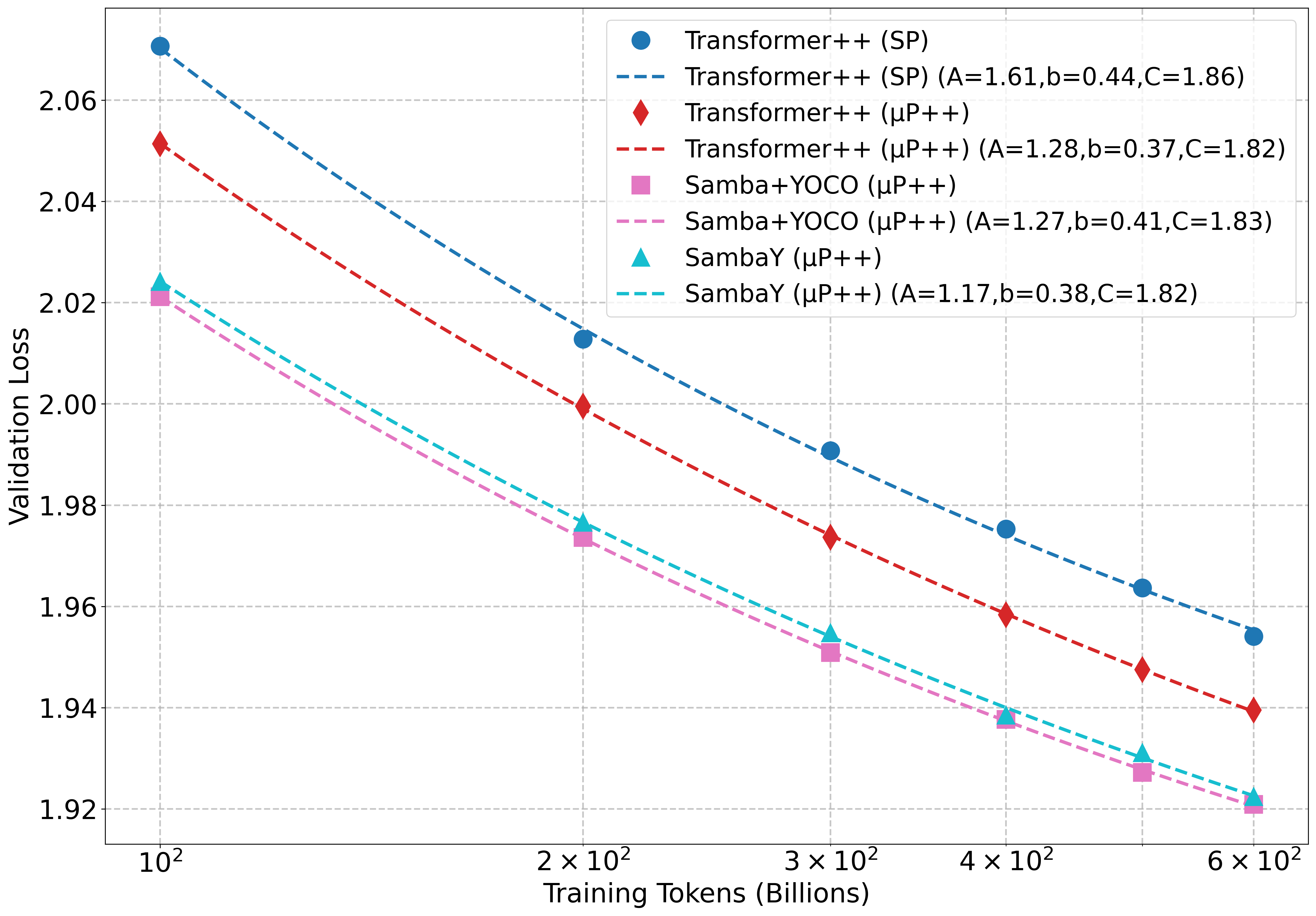
本文提出了一种名为SambaY的Decoder-Hybrid-Decoder架构,旨在提升长序列建模的效率。SambaY利用门控记忆单元(GMU)实现跨层记忆共享,在基于Samba的自解码器中,通过交叉解码器中的GMU共享记忆读取状态。该架构显著提高了解码效率,保持了线性预填充时间复杂度,增强了长上下文性能,并且无需显式的位置编码。大规模实验表明,SambaY相比强大的YOCO基线,展现出更低的不可约损失,表明其在大规模计算条件下具有更优的性能可扩展性。增强了差分注意力的最大模型Phi4-mini-Flash-Reasoning在Math500、AIME24/25和GPQA Diamond等推理任务上,无需任何强化学习,就实现了显著优于Phi4-mini-Reasoning的性能,同时在vLLM推理框架下,在2K长度提示和32K生成长度下,提供了高达10倍的解码吞吐量。我们已在https://github.com/microsoft/ArchScale上开源了我们的训练代码库。
🔬 方法详解
问题定义:现有Decoder-Decoder架构(如YOCO)和混合架构(如Samba)在长序列建模中展现出潜力,但它们在SSM层之间进行表示共享的效率潜力尚未被充分挖掘。现有方法可能存在冗余计算和信息传递,限制了在大规模长文本生成任务中的效率和可扩展性。
核心思路:论文的核心思路是通过引入门控记忆单元(GMU)来实现跨层记忆共享,从而减少冗余计算,提升解码效率。GMU允许自解码器中的Samba层将其记忆读取状态共享给交叉解码器,避免重复计算,并促进信息在不同层之间的有效传递。
技术框架:SambaY采用Decoder-Hybrid-Decoder架构。该架构包含一个基于Samba的自解码器和一个交叉解码器。自解码器负责处理输入序列并生成记忆状态,交叉解码器利用GMU从自解码器共享的记忆状态中读取信息,并生成最终的输出序列。整个流程保持了线性预填充时间复杂度。
关键创新:最重要的技术创新点是门控记忆单元(GMU)的设计。GMU是一种简单而有效的机制,用于在SSM层之间共享记忆读取状态。与现有方法相比,GMU无需显式的位置编码,并且能够显著提高解码效率,同时保持或提升长文本生成性能。
关键设计:GMU的具体实现细节未知,但可以推断其包含门控机制,用于控制自解码器记忆状态的读取和利用。损失函数和网络结构的具体细节未在摘要中提及,但可以推断使用了标准的语言建模损失函数,并可能针对长文本生成进行了优化。差分注意力机制被用于增强最大模型,但具体实现细节也未知。
🖼️ 关键图片

📊 实验亮点
SambaY在推理任务(如Math500、AIME24/25和GPQA Diamond)上,无需强化学习,就实现了显著优于Phi4-mini-Reasoning的性能。更重要的是,在vLLM推理框架下,SambaY在2K长度提示和32K生成长度下,提供了高达10倍的解码吞吐量,表明其在实际应用中具有显著的效率优势。
🎯 应用场景
该研究成果可应用于各种需要高效长文本生成的场景,例如:大型语言模型的推理加速、对话系统、机器翻译、代码生成等。通过提升解码效率,SambaY能够降低计算成本,并支持更大规模的长文本生成任务,从而推动相关应用的发展。
📄 摘要(原文)
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.