SpindleKV: A Novel KV Cache Reduction Method Balancing Both Shallow and Deep Layers
作者: Zicong Tang, Shi Luohe, Zuchao Li, Baoyuan Qi, Guoming Liu, Lefei Zhang, Ping Wang
分类: cs.CL
发布日期: 2025-07-09
备注: Accepted by ACL 2025 main
💡 一句话要点
SpindleKV:一种平衡浅层和深层的新型KV缓存缩减方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存缩减 大型语言模型 推理优化 注意力机制 码本替换
📋 核心要点
- 现有KV缓存驱逐方法在深层有效,但在浅层效果不佳,未能充分利用KV缓存的冗余性。
- SpindleKV针对深层和浅层分别采用基于注意力权重的驱逐和基于码本的替换策略,平衡了各层的缩减效果。
- 实验表明,SpindleKV在保持或提升模型性能的同时,实现了比现有方法更好的KV缓存缩减效果。
📝 摘要(中文)
近年来,大型语言模型(LLMs)取得了令人瞩目的成就。然而,KV缓存不断增长的内存消耗对推理系统提出了重大挑战。驱逐方法揭示了KV缓存中固有的冗余,表明其具有缩减的潜力,尤其是在更深的层中。然而,发现对较浅层的KV缓存缩减是不够的。基于我们对KV缓存表现出高度相似性的观察,我们提出了一种新的KV缓存缩减方法SpindleKV,该方法平衡了浅层和深层。对于深层,我们采用基于注意力权重的驱逐方法,而对于浅层,我们应用基于码本的替换方法,该方法通过相似性和合并策略学习。此外,SpindleKV解决了其他基于注意力的驱逐方法面临的Grouped-Query Attention(GQA)困境。在具有三种不同LLM的两个常见基准上的实验表明,与基线方法相比,SpindleKV获得了更好的KV缓存缩减效果,同时保持了相似甚至更好的模型性能。
🔬 方法详解
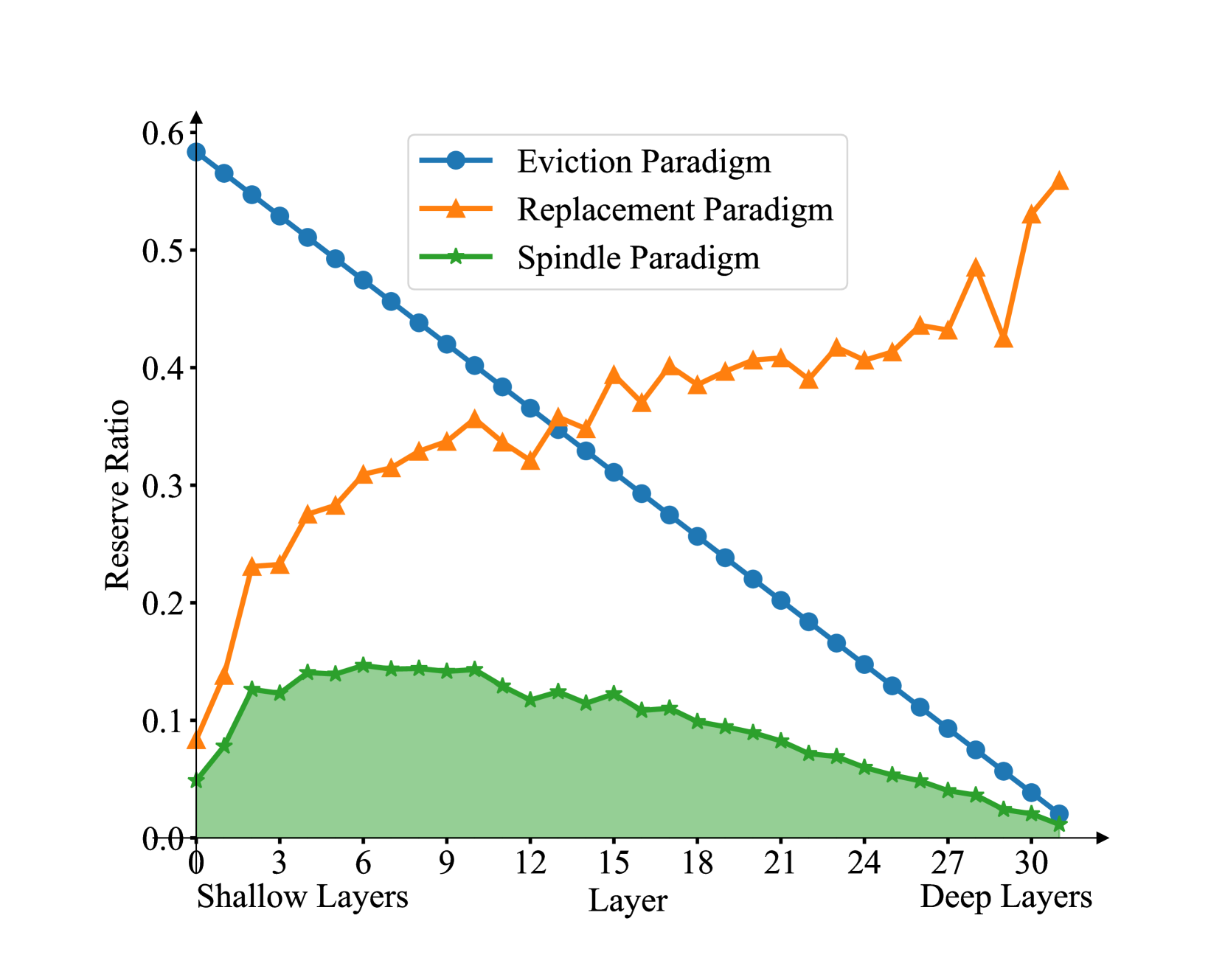
问题定义:大型语言模型推理时,KV缓存的内存占用日益增长,成为部署的瓶颈。现有的KV缓存缩减方法,如基于注意力权重的驱逐策略,主要针对深层网络有效,对浅层网络的缩减效果有限,未能充分挖掘浅层KV缓存的冗余性。此外,某些方法在处理Grouped-Query Attention (GQA) 机制时存在困难。
核心思路:SpindleKV的核心思路是根据网络深度,采用不同的KV缓存缩减策略。对于深层网络,沿用基于注意力权重的驱逐策略,因为深层KV缓存的冗余性主要体现在注意力权重上。对于浅层网络,则采用基于码本的替换策略,利用浅层KV缓存的高度相似性,通过聚类和合并相似的KV向量来减少存储空间。
技术框架:SpindleKV的整体框架包含两个主要部分:深层KV缓存的注意力权重驱逐模块和浅层KV缓存的码本替换模块。首先,确定一个分层阈值,将网络分为深层和浅层。对于深层,使用标准的注意力权重驱逐策略。对于浅层,构建一个码本,将相似的KV向量映射到码本中的一个条目,从而减少存储空间。在推理过程中,浅层KV缓存中的向量会被替换为码本中的索引。
关键创新:SpindleKV的关键创新在于针对不同深度的网络层,采用了不同的KV缓存缩减策略,从而实现了更均衡的缩减效果。与现有方法相比,SpindleKV不仅考虑了深层KV缓存的冗余性,还充分利用了浅层KV缓存的高度相似性。此外,SpindleKV能够有效处理GQA机制,避免了其他基于注意力权重的驱逐方法可能遇到的问题。
关键设计:浅层码本的构建是关键。首先,对浅层KV缓存中的向量进行聚类,例如使用K-means算法。然后,将每个簇的中心向量作为码本中的一个条目。在推理过程中,对于每个新的KV向量,找到码本中与其最相似的条目,并用该条目的索引替换原始向量。码本的大小是一个重要的参数,需要根据实际情况进行调整,以平衡缩减效果和模型性能。此外,论文还提出了一种基于相似性的合并策略,用于动态更新码本,以适应不同的输入。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SpindleKV在两个常见基准测试和三种不同的LLM上,相比于基线方法,实现了更好的KV缓存缩减效果,同时保持了相似甚至更好的模型性能。具体数据未知,但摘要强调了在性能持平或提升的前提下,实现了更优的KV缓存缩减。
🎯 应用场景
SpindleKV可应用于各种需要部署大型语言模型的场景,例如云端推理服务、移动设备上的离线推理等。通过降低KV缓存的内存占用,SpindleKV可以降低部署成本,提高推理速度,并使得在资源受限的设备上部署大型语言模型成为可能。该方法还有助于推动大型语言模型在边缘计算等领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have achieved impressive accomplishments in recent years. However, the increasing memory consumption of KV cache has possessed a significant challenge to the inference system. Eviction methods have revealed the inherent redundancy within the KV cache, demonstrating its potential for reduction, particularly in deeper layers. However, KV cache reduction for shallower layers has been found to be insufficient. Based on our observation that, the KV cache exhibits a high degree of similarity. Based on this observation, we proposed a novel KV cache reduction method, SpindleKV, which balances both shallow and deep layers. For deep layers, we employ an attention weight based eviction method, while for shallow layers, we apply a codebook based replacement approach which is learnt by similarity and merging policy. Moreover, SpindleKV addressed the Grouped-Query Attention (GQA) dilemma faced by other attention based eviction methods. Experiments on two common benchmarks with three different LLMs shown that SpindleKV obtained better KV cache reduction effect compared to baseline methods, while preserving similar or even better model performance.