On the Robustness of Verbal Confidence of LLMs in Adversarial Attacks
作者: Stephen Obadinma, Xiaodan Zhu
分类: cs.CL
发布日期: 2025-07-09 (更新: 2025-12-18)
备注: Published in NeurIPS 2025
💡 一句话要点
研究表明,针对LLM语言置信度的对抗攻击能显著降低其可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 语言置信度 鲁棒性 越狱攻击
📋 核心要点
- 现有LLM的语言置信度在对抗攻击下表现脆弱,难以保证人机交互的透明性和安全性。
- 论文提出基于扰动和越狱的攻击框架,旨在降低LLM的语言置信度评分。
- 实验证明,对抗攻击能显著降低LLM的语言置信度,并导致答案频繁改变,现有防御手段效果不佳。
📝 摘要(中文)
本文首次全面研究了大型语言模型(LLM)在对抗攻击下的语言置信度鲁棒性。我们提出了针对语言置信度评分的攻击框架,包括基于扰动和越狱的方法。实验表明,这些攻击能显著削弱语言置信度估计,并导致频繁的答案改变。我们考察了多种提示策略、模型大小和应用领域,揭示了当前语言置信度的脆弱性,以及常用防御技术在很大程度上无效或适得其反。研究结果强调了为LLM设计鲁棒的置信度表达机制的必要性,因为即使是细微的语义保持修改也可能导致对响应产生误导性的置信度。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)的语言置信度在面对对抗攻击时的鲁棒性问题。现有方法缺乏对LLM语言置信度在对抗环境下的系统性评估,并且已有的防御手段效果有限,无法有效抵御对抗攻击,这使得LLM在安全敏感的应用中存在潜在风险。
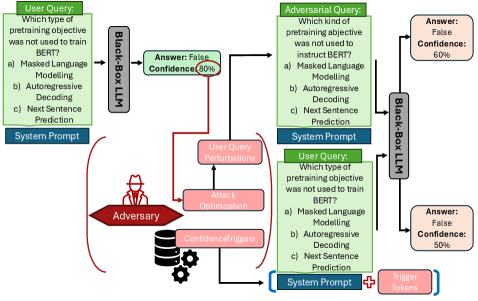
核心思路:论文的核心思路是通过设计特定的对抗攻击方法,包括基于扰动和基于越狱的攻击,来评估LLM的语言置信度在受到攻击时的表现。通过观察LLM在受到攻击后置信度评分的变化以及答案的改变情况,来判断其语言置信度的鲁棒性。
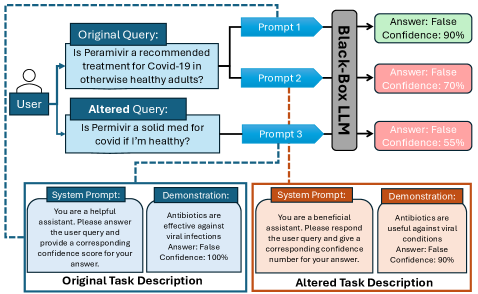
技术框架:论文提出的攻击框架主要包含两个主要模块:基于扰动的攻击和基于越狱的攻击。基于扰动的攻击通过对输入文本进行细微的语义保持修改来影响LLM的置信度输出。基于越狱的攻击则利用特定的提示语来绕过LLM的安全机制,从而使其产生不准确或不安全的回答,并观察其置信度。整个流程包括:选择目标LLM、设计对抗攻击策略、生成对抗样本、输入对抗样本到LLM、评估LLM的置信度输出和答案变化。
关键创新:论文的关键创新在于首次系统性地研究了LLM的语言置信度在对抗攻击下的鲁棒性。提出了两种新的攻击框架,并对多种提示策略、模型大小和应用领域进行了广泛的实验评估。揭示了现有LLM语言置信度的脆弱性以及常用防御手段的局限性。
关键设计:论文中对抗攻击的关键设计包括:1) 扰动攻击的具体实现方式,例如使用同义词替换、插入无关字符等;2) 越狱攻击的提示语设计,需要精心构造能够绕过LLM安全机制的指令;3) 置信度评估指标的选择,例如使用LLM自身输出的置信度评分或通过外部评估模型进行评估;4) 实验中对不同模型大小、提示策略和应用领域的选择,以保证研究的全面性和泛化性。
🖼️ 关键图片
📊 实验亮点
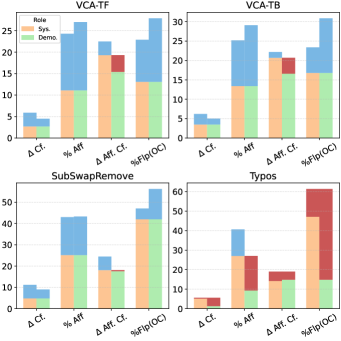
实验结果表明,即使是细微的语义保持修改也能显著降低LLM的语言置信度,并导致答案频繁改变。常用的防御技术,如对抗训练和输入过滤,在很大程度上无效或适得其反。例如,在某些情况下,对抗攻击能使LLM的置信度降低50%以上,同时导致答案改变的概率增加30%。
🎯 应用场景
该研究成果对提升人机交互系统的安全性、可靠性和可信度具有重要意义。通过提高LLM语言置信度的鲁棒性,可以减少其在对抗攻击下的误导性输出,从而避免在医疗诊断、金融风控等关键领域的错误决策。未来的研究可以进一步探索更有效的防御机制,并开发更可靠的置信度评估方法,以促进LLM在更广泛领域的安全应用。
📄 摘要(原文)
Robust verbal confidence generated by large language models (LLMs) is crucial for the deployment of LLMs to help ensure transparency, trust, and safety in many applications, including those involving human-AI interactions. In this paper, we present the first comprehensive study on the robustness of verbal confidence under adversarial attacks. We introduce attack frameworks targeting verbal confidence scores through both perturbation and jailbreak-based methods, and demonstrate that these attacks can significantly impair verbal confidence estimates and lead to frequent answer changes. We examine a variety of prompting strategies, model sizes, and application domains, revealing that current verbal confidence is vulnerable and that commonly used defence techniques are largely ineffective or counterproductive. Our findings underscore the need to design robust mechanisms for confidence expression in LLMs, as even subtle semantic-preserving modifications can lead to misleading confidence in responses.