Efficiency-Effectiveness Reranking FLOPs for LLM-based Rerankers
作者: Zhiyuan Peng, Ting-ruen Wei, Tingyu Song, Yilun Zhao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-08 (更新: 2025-10-09)
备注: Accepted by EMNLP Industry Track 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于FLOPs的LLM重排序器效率评估指标RPP和QPP,解决现有评估方法硬件依赖问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM重排序 效率评估 FLOPs 信息检索 RPP QPP 计算复杂度 效率-效果权衡
📋 核心要点
- 现有LLM重排序器的效率评估依赖硬件和运行时,忽略模型大小,难以有效评估效率-效果权衡。
- 提出RPP和QPP指标,分别衡量每PetaFLOP的排名质量和查询数,并开发FLOPs估计器。
- 实验评估了多种LLM重排序器,分析了效率-效果权衡,旨在引起研究界对该问题的重视。
📝 摘要(中文)
大型语言模型(LLM)最近被应用于信息检索中的重排序任务,并取得了强大的性能。然而,它们的高计算需求常常阻碍了实际部署。现有的研究使用诸如延迟、前向传播次数、输入token和输出token等代理指标来评估基于LLM的重排序器的效率。然而,这些指标依赖于硬件和运行时的选择(例如,并行与否,batch size等),并且常常不能考虑模型大小,使得难以解释并模糊了效率-效果的权衡。为了解决这个问题,我们为基于LLM的重排序器提出了RPP(每PetaFLOP的排名指标),衡量一种方法每PetaFLOP能实现的排名质量(例如,NDCG或MRR),以及QPP(每PetaFLOP的查询数),衡量每PetaFLOP可以处理多少查询。伴随着新的指标,开发了一个可解释的FLOPs估计器,即使不运行任何实验也能估计基于LLM的重排序器的FLOPs。基于提出的指标,我们进行了全面的实验,以评估具有不同架构的各种基于LLM的重排序器,研究效率-效果的权衡,并将这个问题引起研究界的关注。
🔬 方法详解
问题定义:现有LLM重排序器虽然效果好,但计算成本高昂,阻碍了实际应用。现有的效率评估方法(如延迟、token数量)依赖于硬件配置和运行参数,无法公平地比较不同模型,也难以反映模型本身的计算复杂度。因此,需要一种更通用的、与硬件无关的效率评估方法,以便更好地进行效率-效果权衡。
核心思路:论文的核心思路是使用FLOPs(浮点运算次数)作为效率的度量标准,因为它与硬件无关,能够更准确地反映模型的计算复杂度。基于FLOPs,论文提出了两个新的指标:RPP(Ranking metrics per PetaFLOP)和QPP(Queries per PetaFLOP),分别衡量每PetaFLOP的排名质量和查询处理量。这样可以将效率和效果直接关联起来,方便进行权衡。
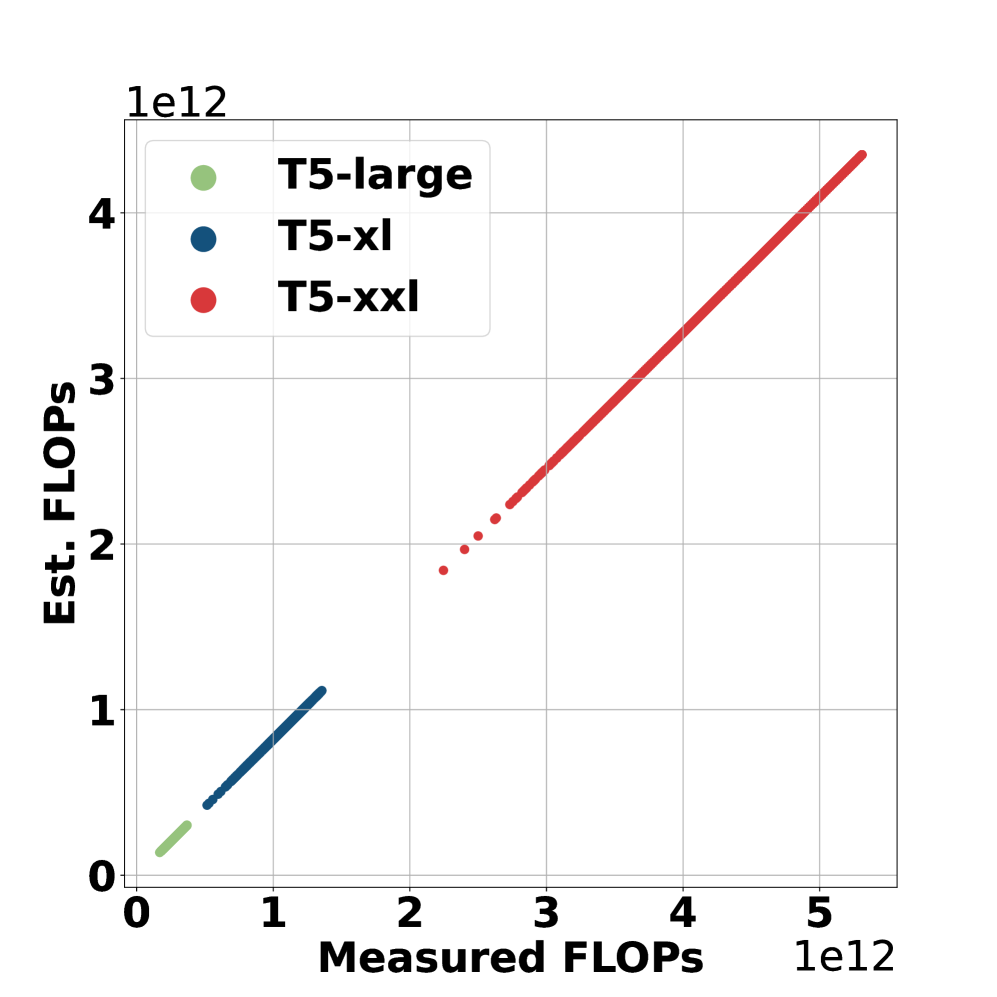
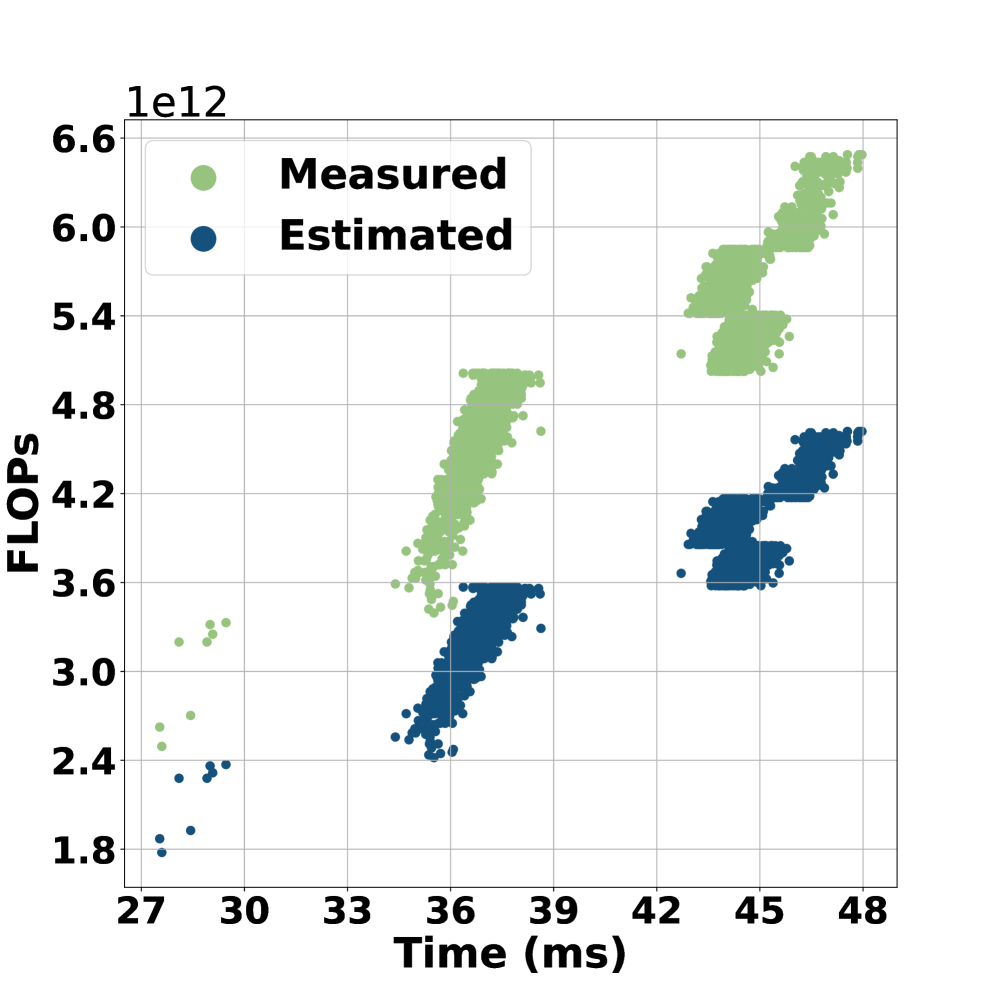
技术框架:论文的技术框架主要包括三个部分:1) 定义RPP和QPP指标;2) 开发FLOPs估计器,用于在不运行实验的情况下估计LLM重排序器的FLOPs;3) 进行实验评估,比较不同LLM重排序器的RPP和QPP值,分析效率-效果权衡。FLOPs估计器是关键,它允许在早期阶段评估模型的效率,而无需进行耗时的实验。
关键创新:最重要的技术创新点是提出了基于FLOPs的效率评估指标RPP和QPP。与现有的基于延迟或token数量的评估方法相比,RPP和QPP更加通用、与硬件无关,能够更准确地反映模型的计算复杂度。此外,FLOPs估计器的开发也使得在早期阶段评估模型的效率成为可能。
关键设计:FLOPs估计器的具体实现细节未知,但可以推测其可能基于模型的架构和参数量进行估计。RPP和QPP的计算公式如下:RPP = Ranking Metric / FLOPs,QPP = Number of Queries / FLOPs。实验中,论文使用了不同的LLM重排序器,并评估了它们的NDCG、MRR等排名指标,然后计算RPP和QPP值进行比较。
🖼️ 关键图片

📊 实验亮点
论文提出了RPP和QPP指标,并开发了FLOPs估计器。通过实验,论文评估了多种LLM重排序器,并分析了它们的效率-效果权衡。具体的性能数据未知,但论文强调了不同模型在RPP和QPP上的差异,以及效率优化对实际部署的重要性。该研究为LLM重排序器的效率评估提供了一种新的视角。
🎯 应用场景
该研究成果可应用于信息检索、推荐系统等领域,帮助研究人员和工程师选择和优化LLM重排序器,在保证排名质量的同时降低计算成本。通过RPP和QPP指标,可以更有效地进行模型选择和参数调优,加速LLM在实际应用中的部署。
📄 摘要(原文)
Large Language Models (LLMs) have recently been applied to reranking tasks in information retrieval, achieving strong performance. However, their high computational demands often hinder practical deployment. Existing studies evaluate the efficiency of LLM-based rerankers using proxy metrics such as latency, the number of forward passes, input tokens, and output tokens. However, these metrics depend on hardware and running-time choices (\eg parallel or not, batch size, etc), and often fail to account for model size, making it difficult to interpret and obscuring the evaluation of the efficiency-effectiveness tradeoff. To address this issue, we propose \ours\footnote{https://github.com/zhiyuanpeng/EER-FLOPs.} for LLM-based rerankers: RPP (ranking metrics per PetaFLOP), measuring how much ranking quality (e.g., NDCG or MRR) a method achieves per PetaFLOP, and QPP (queries per PetaFLOP), measuring how many queries can be processed per PetaFLOP. Accompanied by the new metrics, an interpretable FLOPs estimator is developed to estimate the FLOPs of an LLM-based reranker even without running any experiments. Based on the proposed metrics, we conduct comprehensive experiments to evaluate a wide range of LLM-based rerankers with different architectures, studying the efficiency-effectiveness trade-off and bringing this issue to the attention of the research community.