Entropy-Memorization Law: Evaluating Memorization Difficulty of Data in LLMs
作者: Yizhan Huang, Zhe Yang, Meifang Chen, Huang Nianchen, Jianping Zhang, Michael R. Lyu
分类: cs.CL, cs.AI
发布日期: 2025-07-08 (更新: 2025-09-27)
💡 一句话要点
提出熵-记忆定律,评估LLM中数据记忆难度并实现数据集推断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 记忆能力 数据熵 数据集推断 隐私风险
📋 核心要点
- 现有方法缺乏对LLM记忆训练数据难度的有效表征,难以理解模型记忆机制。
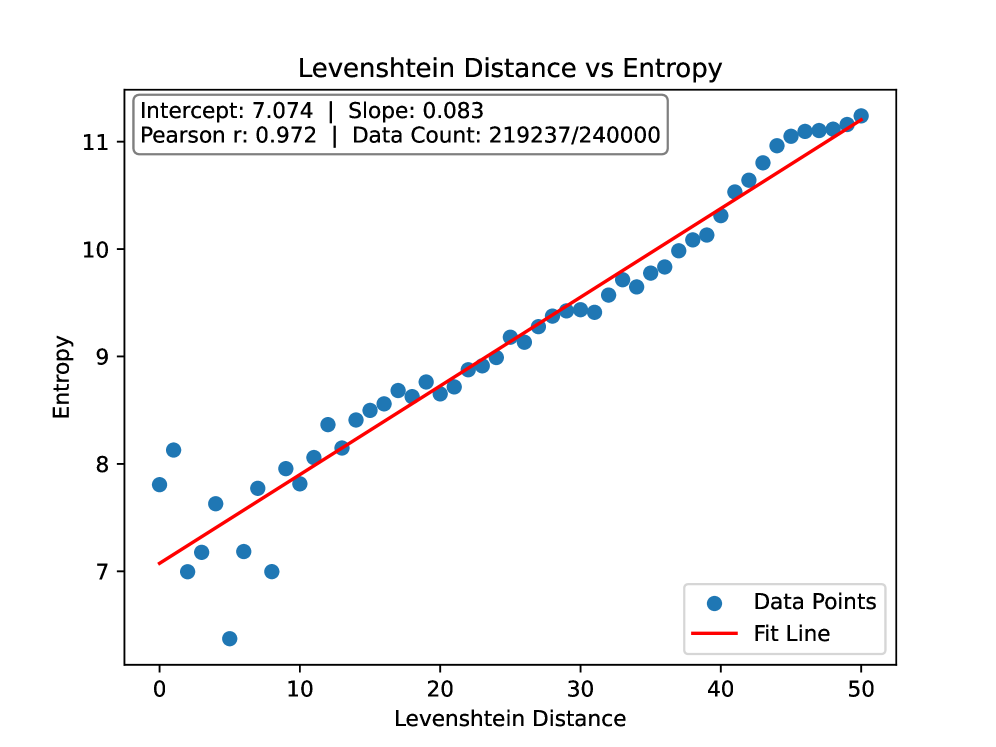
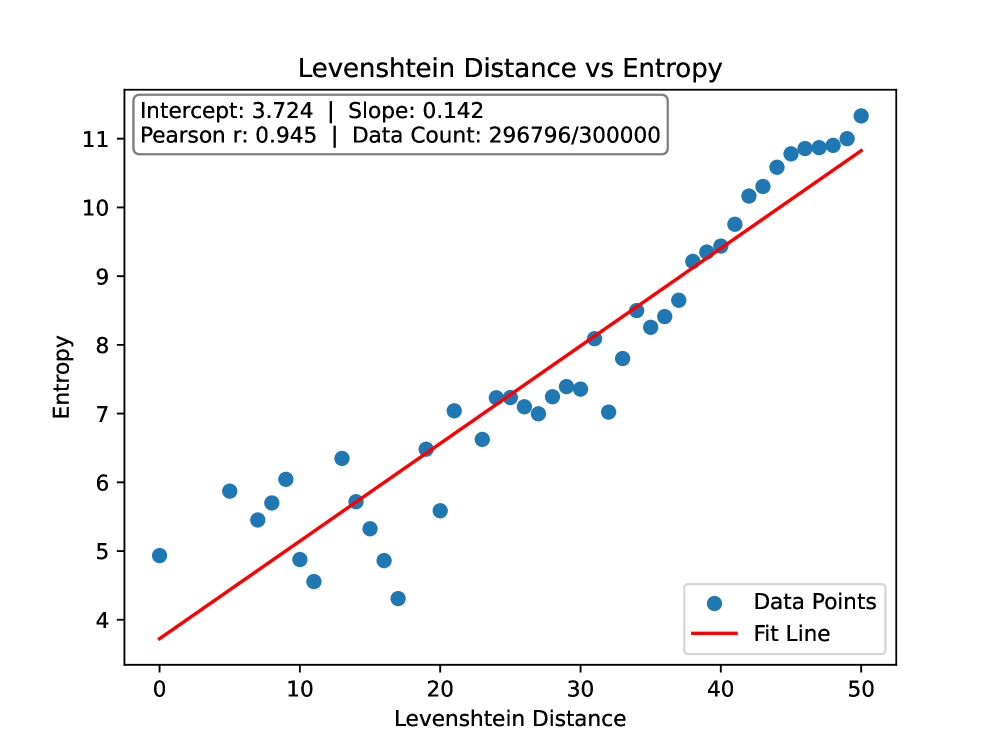
- 论文提出熵-记忆定律,揭示数据熵与模型记忆程度的线性关系,为理解记忆机制提供新视角。
- 实验表明,基于熵-记忆定律的方法能够有效区分训练数据和测试数据,实现数据集推断。
📝 摘要(中文)
大型语言模型(LLMs)会记忆其训练数据的一部分,有时会在适当的提示下逐字再现内容。本文研究了记忆领域中一个基本但未被充分探索的问题:如何表征LLM中训练数据的记忆难度?通过对OLMo(一个开放模型系列)的实证实验,我们提出了熵-记忆定律。该定律表明数据熵与记忆得分呈线性相关。此外,在一个记忆高度随机化字符串(或“乱码”)的案例研究中,我们观察到这些序列尽管表面上是随机的,但与更广泛的训练语料库相比,表现出出乎意料的低经验熵。采用相同的策略来发现熵-记忆定律,我们推导出一种简单而有效的方法来区分训练和测试数据,从而实现数据集推断(DI)。
🔬 方法详解
问题定义:论文旨在解决如何量化评估LLM记忆训练数据的难易程度的问题。现有方法缺乏对数据记忆难度的有效表征,无法深入理解LLM的记忆机制,也难以区分训练数据和测试数据。
核心思路:论文的核心思路是发现数据本身的统计特性(熵)与LLM对该数据的记忆程度之间的关系。通过分析数据熵与记忆得分之间的关联,建立熵-记忆定律,从而利用数据熵来评估记忆难度,并区分训练数据和测试数据。
技术框架:论文的技术框架主要包括以下几个步骤:1) 在OLMo模型上进行实验,分析不同数据的记忆得分;2) 计算训练数据的熵值;3) 建立数据熵与记忆得分之间的线性关系模型,即熵-记忆定律;4) 基于熵-记忆定律,设计数据集推断方法,区分训练数据和测试数据。
关键创新:论文最重要的技术创新点在于发现了熵-记忆定律,揭示了数据熵与LLM记忆程度之间的线性关系。这一发现为理解LLM的记忆机制提供了新的视角,并为数据集推断提供了一种简单而有效的方法。与现有方法相比,该方法无需复杂的模型训练或特征工程,仅依赖于数据本身的统计特性。
关键设计:论文的关键设计包括:1) 使用OLMo模型作为实验平台,因为它是一个开源模型,方便研究人员进行分析和修改;2) 采用记忆得分作为衡量LLM记忆程度的指标,该指标反映了模型在多大程度上能够准确地再现训练数据;3) 使用经验熵作为衡量数据随机性的指标;4) 通过线性回归分析,建立数据熵与记忆得分之间的线性关系模型。
🖼️ 关键图片

📊 实验亮点
论文通过在OLMo模型上的实验验证了熵-记忆定律的有效性。实验结果表明,数据熵与记忆得分之间存在显著的线性相关关系。此外,基于熵-记忆定律的数据集推断方法能够有效区分训练数据和测试数据,为LLM的安全性评估提供了新的思路。
🎯 应用场景
该研究成果可应用于评估LLM的隐私风险,识别模型可能泄露的敏感信息。此外,该方法还可用于改进LLM的训练策略,例如,通过调整训练数据的熵分布,提高模型的泛化能力和鲁棒性。该研究对于提升LLM的安全性和可靠性具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) are known to memorize portions of their training data, sometimes reproducing content verbatim when prompted appropriately. In this work, we investigate a fundamental yet under-explored question in the domain of memorization: How to characterize memorization difficulty of training data in LLMs? Through empirical experiments on OLMo, a family of open models, we present the Entropy-Memorization Law. It suggests that data entropy is linearly correlated with memorization score. Moreover, in a case study of memorizing highly randomized strings, or "gibberish", we observe that such sequences, despite their apparent randomness, exhibit unexpectedly low empirical entropy compared to the broader training corpus. Adopting the same strategy to discover Entropy-Memorization Law, we derive a simple yet effective approach to distinguish training and testing data, enabling Dataset Inference (DI).