DocTalk: Scalable Graph-based Dialogue Synthesis for Enhancing LLM Conversational Capabilities
作者: Jing Yang Lee, Hamed Bonab, Nasser Zalmout, Ming Zeng, Sanket Lokegaonkar, Colin Lockard, Binxuan Huang, Ritesh Sarkhel, Haodong Wang
分类: cs.CL
发布日期: 2025-07-08
备注: Accepted at SIGDIAL 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
DocTalk:提出基于图的可扩展对话合成方法,增强LLM的对话能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多轮对话 对话合成 预训练 图神经网络
📋 核心要点
- 现有LLM预训练数据多为连续文本,与多轮对话任务的需求存在不匹配,限制了其对话能力。
- 论文提出一种新颖的对话合成pipeline,将多个相关文档转换为多轮、多主题的信息搜索对话。
- 实验表明,使用DocTalk进行预训练可显著提升LLM的上下文记忆和理解能力,最高可达40%。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于多轮对话任务中,但其预训练数据主要由连续文本组成,这在所需能力和训练范式之间造成了潜在的不匹配。本文提出了一种新颖的方法,通过从现有文本语料库中合成对话数据来解决这一差异。我们提出了一个pipeline,将多个相关文档的集群转换为扩展的多轮、多主题信息搜索对话。通过将我们的pipeline应用于维基百科文章,我们整理了DocTalk,这是一个包含超过73万个长对话的多轮预训练对话语料库。我们假设,在预训练期间接触到这种合成的对话结构可以增强LLMs的基本多轮能力,例如上下文记忆和理解。经验表明,在预训练期间加入DocTalk可以使上下文记忆和理解能力提高高达40%,而不会影响基础性能。DocTalk可在https://huggingface.co/datasets/AmazonScience/DocTalk 获取。
🔬 方法详解
问题定义:现有大型语言模型在多轮对话任务中表现不足,主要原因是其预训练数据以连续文本为主,缺乏多轮对话的结构化信息。这导致模型在上下文理解、信息检索和对话连贯性等方面存在挑战。现有方法难以有效地从非对话文本中提取和构建高质量的对话数据,从而限制了模型在对话场景下的泛化能力。
核心思路:本文的核心思路是通过构建一个可扩展的对话合成pipeline,将多个相关的文档(例如维基百科文章)转化为结构化的多轮对话。这种方法旨在为LLM提供更丰富的对话训练数据,从而增强其在多轮对话任务中的上下文理解和信息整合能力。通过模拟真实对话场景,使模型能够更好地学习对话的模式和策略。
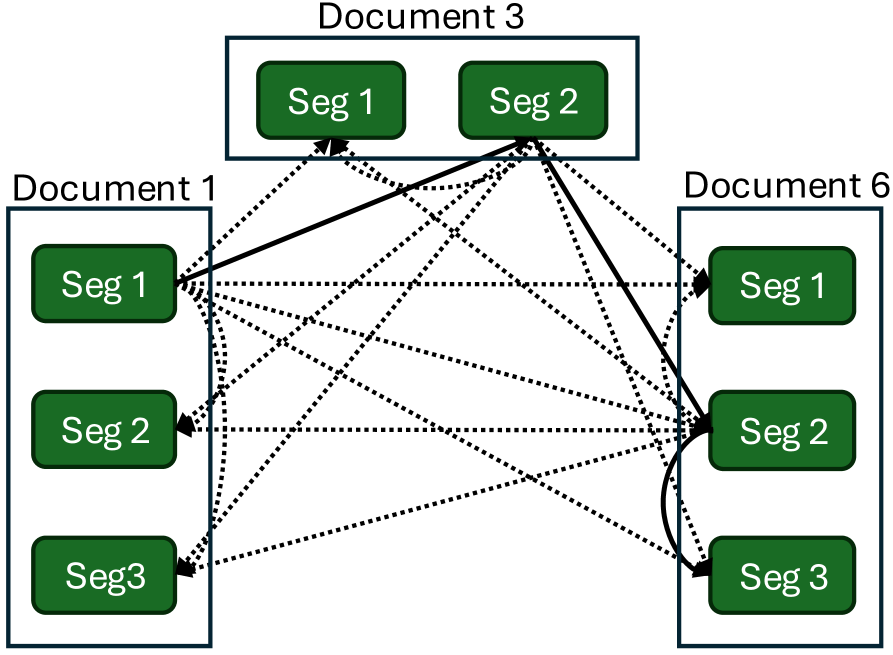
技术框架:DocTalk的整体框架包含以下几个主要阶段:1) 文档聚类:将相关的文档进行聚类,形成主题相关的文档集合。2) 对话生成:利用图结构表示文档之间的关系,并基于此生成多轮对话。3) 数据清洗与过滤:对生成的对话数据进行清洗和过滤,去除低质量或不相关的对话。4) 数据集构建:将清洗后的对话数据构建成可用于LLM预训练的对话语料库。
关键创新:该方法的主要创新在于利用图结构来表示文档之间的关系,并基于图结构生成多轮对话。这种方法能够有效地捕捉文档之间的语义关系,从而生成更自然、更连贯的对话。此外,该pipeline具有可扩展性,可以应用于不同的文档集合,从而生成大规模的对话语料库。
关键设计:在对话生成阶段,论文采用了一种基于图的对话生成模型,该模型利用图神经网络来学习文档之间的关系,并基于此生成对话。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。损失函数的设计目标是最大化生成对话的流畅性和相关性,具体的损失函数形式也属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用DocTalk进行预训练可以显著提升LLM的上下文记忆和理解能力,最高可达40%。该提升是在不影响模型基础性能的前提下实现的,表明DocTalk能够有效地增强LLM的对话能力,而不会引入负面影响。具体的实验设置和对比基线在论文中未详细说明,属于未知信息。
🎯 应用场景
该研究成果可广泛应用于智能客服、对话式问答系统、虚拟助手等领域。通过提升LLM的对话能力,可以构建更加智能、自然的对话系统,从而改善用户体验,提高工作效率。未来,该方法还可以扩展到其他类型的文本数据,例如新闻文章、社交媒体帖子等,从而构建更加多样化的对话语料库。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly employed in multi-turn conversational tasks, yet their pre-training data predominantly consists of continuous prose, creating a potential mismatch between required capabilities and training paradigms. We introduce a novel approach to address this discrepancy by synthesizing conversational data from existing text corpora. We present a pipeline that transforms a cluster of multiple related documents into an extended multi-turn, multi-topic information-seeking dialogue. Applying our pipeline to Wikipedia articles, we curate DocTalk, a multi-turn pre-training dialogue corpus consisting of over 730k long conversations. We hypothesize that exposure to such synthesized conversational structures during pre-training can enhance the fundamental multi-turn capabilities of LLMs, such as context memory and understanding. Empirically, we show that incorporating DocTalk during pre-training results in up to 40% gain in context memory and understanding, without compromising base performance. DocTalk is available at https://huggingface.co/datasets/AmazonScience/DocTalk.