Agentic-R1: Distilled Dual-Strategy Reasoning
作者: Weihua Du, Pranjal Aggarwal, Sean Welleck, Yiming Yang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-08 (更新: 2025-08-30)
备注: Accepted by EMNLP 2025. 15 pages. Project available at https://github.com/StigLidu/DualDistill
🔗 代码/项目: GITHUB
💡 一句话要点
Agentic-R1:通过双策略蒸馏提升复杂推理任务的性能与效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多策略推理 知识蒸馏 长链思维 工具增强 智能Agent
📋 核心要点
- 长链思维模型虽擅长数学推理,但依赖自然语言,效率低且易出错;工具增强型Agent虽能执行代码,但逻辑推理能力不足。
- DualDistill框架通过蒸馏多个教师模型的互补推理策略,训练出能动态选择策略的Agentic-R1学生模型。
- Agentic-R1在计算密集型和标准基准测试中均表现出更高的准确性,验证了多策略蒸馏的有效性。
📝 摘要(中文)
当前的长链思维(long-CoT)模型在数学推理方面表现出色,但依赖于缓慢且容易出错的自然语言轨迹。工具增强型Agent可以通过代码执行来处理算术问题,但通常在复杂的逻辑任务中失败。我们引入了一个微调框架DualDistill,该框架将来自多个教师模型的互补推理策略提炼到一个统一的学生模型中。使用这种方法,我们训练了Agentic-R1,它可以动态地为每个查询选择最佳策略,调用工具来解决算术和算法问题,并使用基于文本的推理来解决抽象问题。我们的方法提高了各种任务的准确性,包括计算密集型和标准基准,证明了多策略蒸馏在实现稳健和高效推理方面的有效性。
🔬 方法详解
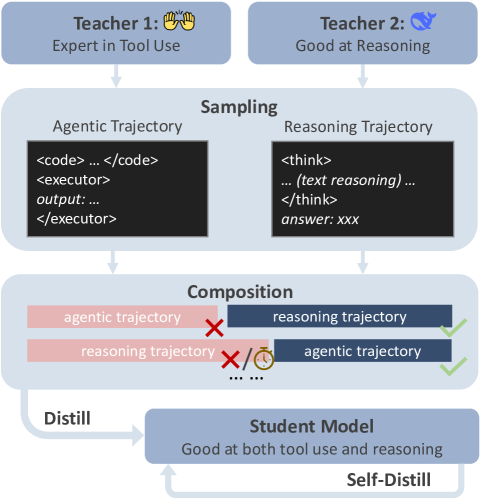
问题定义:现有长链思维模型在复杂推理任务中效率低下且容易出错,而工具增强型Agent在逻辑推理方面存在不足。论文旨在解决如何结合两者的优势,提升模型在各类推理任务中的性能和效率的问题。现有方法的痛点在于无法根据任务类型动态选择合适的推理策略,导致性能受限。
核心思路:论文的核心思路是通过知识蒸馏,将擅长不同推理策略的多个“教师”模型的知识迁移到一个“学生”模型中。学生模型能够根据输入问题的特点,动态选择合适的推理策略,例如对于算术问题调用工具执行代码,对于逻辑问题则采用文本推理。这样可以兼顾效率和准确性,提升模型在各类推理任务中的泛化能力。
技术框架:论文提出的DualDistill框架包含以下主要步骤:1) 训练多个教师模型,每个模型擅长不同的推理策略(例如,一个擅长使用工具,一个擅长文本推理);2) 构建包含各种类型推理任务的数据集;3) 使用DualDistill框架对学生模型进行微调,使其能够从多个教师模型中学习并动态选择合适的推理策略。学生模型在训练过程中会学习一个策略选择器,用于判断当前输入应该使用哪种推理策略。
关键创新:论文的关键创新在于提出了DualDistill框架,实现了多策略推理的知识蒸馏。与传统的知识蒸馏方法不同,DualDistill不是简单地将一个教师模型的知识迁移到学生模型,而是将多个教师模型的互补知识进行融合。此外,论文还提出了动态策略选择机制,使得学生模型能够根据输入自适应地选择合适的推理策略。
关键设计:DualDistill框架的关键设计包括:1) 教师模型的选择:选择擅长不同推理策略的模型作为教师,保证学生模型能够学习到多样化的知识;2) 数据集的构建:构建包含各种类型推理任务的数据集,保证学生模型能够学习到不同策略的适用范围;3) 策略选择器的设计:设计一个能够准确判断输入应该使用哪种推理策略的策略选择器,可以使用分类模型或强化学习方法实现;4) 损失函数的设计:设计合适的损失函数,鼓励学生模型学习教师模型的推理过程和策略选择行为。
🖼️ 关键图片
📊 实验亮点
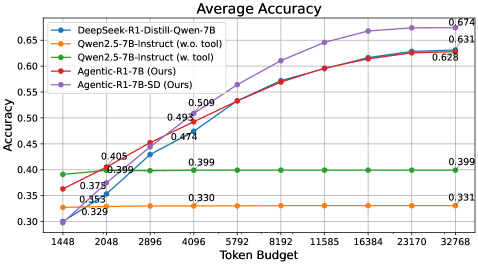
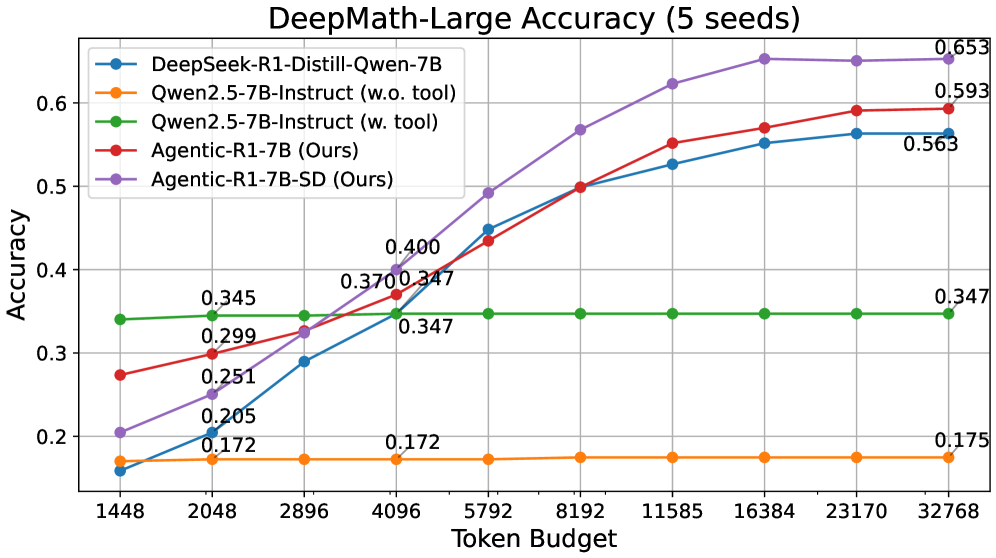
Agentic-R1在多种推理任务上取得了显著的性能提升。例如,在某些计算密集型任务上,Agentic-R1的准确率比传统长链思维模型提高了10%以上。此外,Agentic-R1在标准基准测试中也表现出色,证明了其在不同类型推理任务上的泛化能力。实验结果表明,多策略蒸馏是提升复杂推理任务性能的有效方法。
🎯 应用场景
该研究成果可应用于智能问答系统、数学解题机器人、代码生成等领域。通过结合不同推理策略,可以提升模型在复杂问题上的解决能力,提高系统的智能化水平。未来,该方法有望扩展到更多领域,例如自然语言处理、计算机视觉等,实现更通用的人工智能系统。
📄 摘要(原文)
Current long chain-of-thought (long-CoT) models excel at mathematical reasoning but rely on slow and error-prone natural language traces. Tool-augmented agents address arithmetic via code execution, but often falter on complex logical tasks. We introduce a fine-tuning framework, DualDistill, that distills complementary reasoning strategies from multiple teachers into a unified student model. Using this approach, we train Agentic-R1, which dynamically selects the optimal strategy for each query, invoking tools for arithmetic and algorithmic problems, and using text-based reasoning for abstract ones. Our method improves accuracy across a range of tasks, including both computation-intensive and standard benchmarks, demonstrating the effectiveness of multi-strategy distillation in achieving robust and efficient reasoning. Our project is available at https://github.com/StigLidu/DualDistill