Mechanistic Indicators of Understanding in Large Language Models
作者: Pierre Beckmann, Matthieu Queloz
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2026-01-08)
备注: 38 pages
💡 一句话要点
通过机制可解释性,探究大语言模型中理解能力的涌现与层次
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 机制可解释性 理解能力 分层框架 认知科学
📋 核心要点
- 现有观点认为大语言模型仅是模仿语言模式,缺乏真正的理解能力,这构成了核心问题。
- 论文提出一个分层框架,区分概念、世界状态和原则性三种理解,并结合机制可解释性进行分析。
- 研究揭示了LLM内部存在支持类理解统一性的组织,但与人类认知在机制利用上存在差异。
📝 摘要(中文)
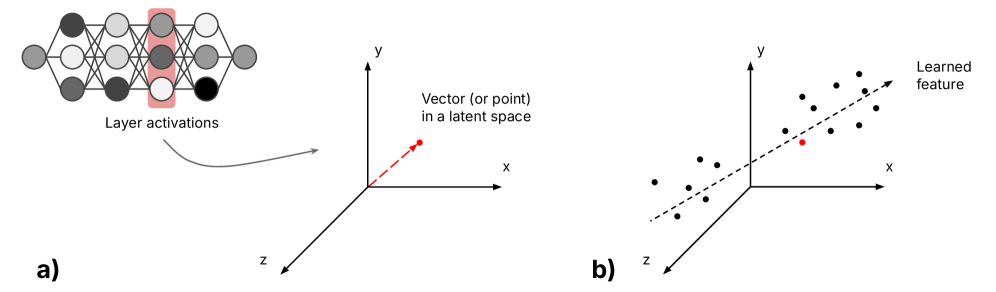
大型语言模型(LLMs)常被认为仅仅模仿语言模式,缺乏真正的理解能力。本文认为,机制可解释性(MI)领域的新发现正在改变这一观点,但前提是将这些发现整合到理解的理论框架中。我们提出了一个分层框架来思考LLMs中的理解,并用它来综合目前最相关的发现。该框架区分了三种层级的理解:概念理解,当模型在潜在空间中形成“特征”,学习单个实体或属性的不同表现形式之间的联系时产生;世界状态理解,当模型学习特征之间的偶然事实联系并动态跟踪世界变化时产生;原则性理解,当模型不再依赖记忆的事实,而是发现连接这些事实的紧凑“电路”时产生。MI揭示了支持类理解统一性的内部组织,但也揭示了它们与人类认知在异构机制并行利用上的差异。将哲学理论与机制证据融合,使我们能够超越关于AI是否理解的二元辩论,为一种比较的、机制基础的认识论铺平道路,探索AI理解与我们自身理解的异同。
🔬 方法详解
问题定义:当前对大型语言模型(LLMs)的理解存在争议,一种观点认为它们只是在模仿语言模式,缺乏真正的理解能力。现有的方法难以深入探究LLMs内部的运作机制,无法有效评估其是否具备真正的理解能力。
核心思路:本文的核心思路是将哲学理论与机制可解释性(MI)相结合,提出了一个分层框架来分析LLMs中的理解能力。通过MI揭示LLMs内部的组织结构和运作机制,并将其与人类的理解能力进行比较,从而更全面地评估LLMs的理解水平。
技术框架:该框架将理解分为三个层级:概念理解、世界状态理解和原则性理解。概念理解涉及模型学习实体或属性的不同表现形式之间的联系;世界状态理解涉及模型学习事实之间的联系并跟踪世界变化;原则性理解涉及模型发现连接事实的紧凑“电路”。MI被用于分析LLMs在每个层级上的运作机制。
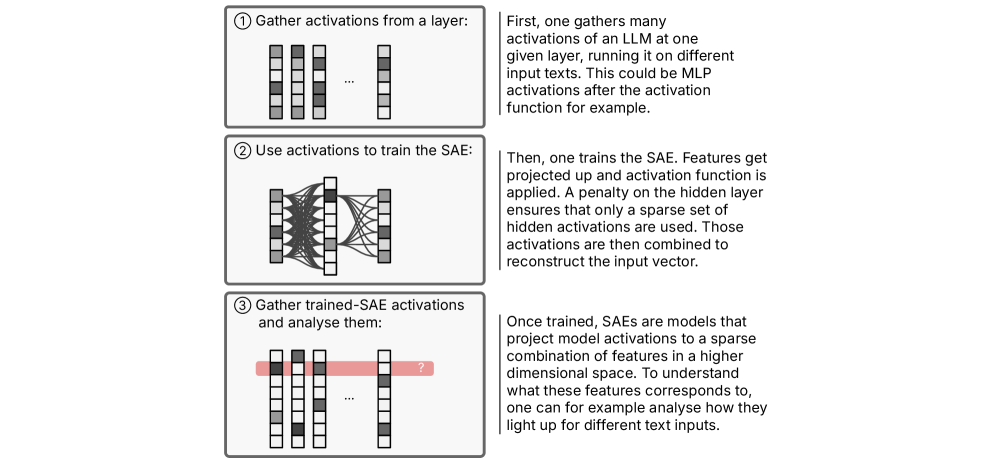
关键创新:该研究的关键创新在于将机制可解释性与哲学理论相结合,提出了一个分层的理解框架。这种方法超越了简单的是/否二元判断,提供了一种更细致、更深入地理解LLMs的方式。通过MI,研究人员可以观察LLMs内部的运作机制,并将其与人类的认知过程进行比较。
关键设计:论文没有详细描述具体的参数设置或网络结构,而是侧重于概念框架的构建和MI的应用。关键在于如何利用MI工具来识别和分析LLMs内部的“特征”、“事实联系”和“电路”,从而评估其在不同层级上的理解能力。未来的研究可以进一步探索具体的MI技术和指标,以更精确地评估LLMs的理解水平。
🖼️ 关键图片

📊 实验亮点
论文通过机制可解释性揭示了LLM内部存在支持类理解统一性的组织,例如模型能够学习到概念的不同表现形式之间的联系。同时,研究也发现LLM与人类认知在异构机制并行利用上存在差异,表明LLM的理解方式与人类存在本质区别。这些发现为深入理解LLM的内部运作机制提供了重要依据。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的理解能力,提升其在知识推理、智能对话等任务中的表现。此外,该研究提出的分层理解框架和机制可解释性方法,为开发更具通用性和鲁棒性的人工智能系统提供了新的思路。
📄 摘要(原文)
Large language models (LLMs) are often portrayed as merely imitating linguistic patterns without genuine understanding. We argue that recent findings in mechanistic interpretability (MI), the emerging field probing the inner workings of LLMs, render this picture increasingly untenable--but only once those findings are integrated within a theoretical account of understanding. We propose a tiered framework for thinking about understanding in LLMs and use it to synthesize the most relevant findings to date. The framework distinguishes three hierarchical varieties of understanding, each tied to a corresponding level of computational organization: conceptual understanding emerges when a model forms "features" as directions in latent space, learning connections between diverse manifestations of a single entity or property; state-of-the-world understanding emerges when a model learns contingent factual connections between features and dynamically tracks changes in the world; principled understanding emerges when a model ceases to rely on memorized facts and discovers a compact "circuit" connecting these facts. Across these tiers, MI uncovers internal organizations that can underwrite understanding-like unification. However, these also diverge from human cognition in their parallel exploitation of heterogeneous mechanisms. Fusing philosophical theory with mechanistic evidence thus allows us to transcend binary debates over whether AI understands, paving the way for a comparative, mechanistically grounded epistemology that explores how AI understanding aligns with--and diverges from--our own.