PhoniTale: Phonologically Grounded Mnemonic Generation for Typologically Distant Language Pairs
作者: Sana Kang, Myeongseok Gwon, Su Young Kwon, Jaewook Lee, Andrew Lan, Bhiksha Raj, Rita Singh
分类: cs.CL
发布日期: 2025-07-07 (更新: 2025-10-13)
备注: Accepted to EMNLP 2025 Main Conference
💡 一句话要点
PhoniTale:面向音系学的助记符生成,解决跨语系语言学习的词汇习得难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言学习 助记符生成 音系学 大型语言模型 词汇习得
📋 核心要点
- 现有方法在跨语系词汇学习中,依赖直接语音匹配或缺乏语音指导的LLM,导致助记符效果不佳。
- PhoniTale通过IPA语音适配和音节对齐检索L1关键词,并用LLM生成提示,实现音系学指导的助记符生成。
- 实验表明,PhoniTale在自动化指标和人类测试中,均优于现有自动化方法,接近人工助记符水平。
📝 摘要(中文)
词汇习得是第二语言(L2)学习者的一个重大挑战,尤其是在学习类型学上差异很大的语言时,例如英语和韩语,其语音和结构的不匹配使词汇学习变得复杂。最近,大型语言模型(LLM)已被用于生成关键词助记符,通过利用学习者第一语言(L1)中相似的关键词来帮助习得L2词汇。然而,大多数方法仍然依赖于直接的基于IPA的语音匹配,或者在没有语音指导的情况下使用LLM。在本文中,我们提出了一种新颖的跨语言助记符生成系统PhoniTale,该系统执行基于IPA的语音适应和音节感知对齐以检索L1关键词序列,并使用LLM生成口头提示。我们通过自动化指标和人类参与者的短期回忆测试来评估PhoniTale,将其输出与人工编写的和先前的自动化助记符进行比较。我们的研究结果表明,PhoniTale始终优于以前的自动化方法,并达到了与人工编写的助记符相当的质量。
🔬 方法详解
问题定义:论文旨在解决跨语系语言学习中,L2词汇习得困难的问题。现有方法主要痛点在于,要么依赖于简单的IPA语音匹配,忽略了更深层次的音系学关系;要么直接使用LLM,缺乏对语音信息的有效利用,导致生成的助记符质量不高,难以帮助学习者记忆。
核心思路:论文的核心思路是结合音系学知识和LLM的生成能力,提出一种音系学指导的助记符生成方法。通过音系学适配和音节对齐,找到L1中与L2词汇发音相似的关键词,然后利用LLM生成基于这些关键词的助记符,从而建立L1和L2词汇之间的联系,帮助学习者记忆。这种方法充分利用了两种语言之间的语音相似性,并结合了LLM的强大生成能力,有望生成更有效的助记符。
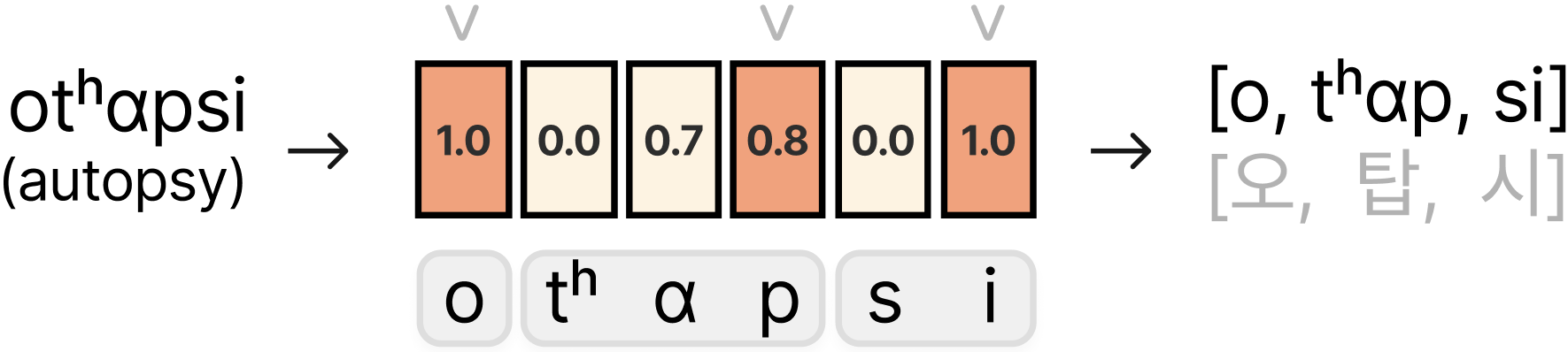
技术框架:PhoniTale系统的整体框架包含以下几个主要模块:1) IPA语音适配模块:将L2词汇和L1词汇转换为IPA表示,并进行语音相似度计算。2) 音节感知对齐模块:对L2和L1词汇的音节进行对齐,确保关键词在音节结构上具有相似性。3) 关键词检索模块:基于语音相似度和音节对齐结果,从L1词汇中检索与L2词汇发音相似的关键词序列。4) LLM提示生成模块:利用LLM,基于检索到的L1关键词序列,生成口头提示,作为助记符。
关键创新:论文最重要的技术创新点在于将音系学知识融入到助记符生成过程中。与以往方法相比,PhoniTale不仅考虑了语音的相似性,还考虑了音节结构等更深层次的音系学关系,从而能够找到更合适的L1关键词,并生成更有效的助记符。此外,论文还提出了一种音节感知的对齐方法,进一步提高了关键词检索的准确性。
关键设计:在IPA语音适配模块中,使用了基于编辑距离的语音相似度计算方法。在音节感知对齐模块中,使用了动态规划算法进行音节对齐。在LLM提示生成模块中,使用了预训练的语言模型,并针对助记符生成任务进行了微调。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
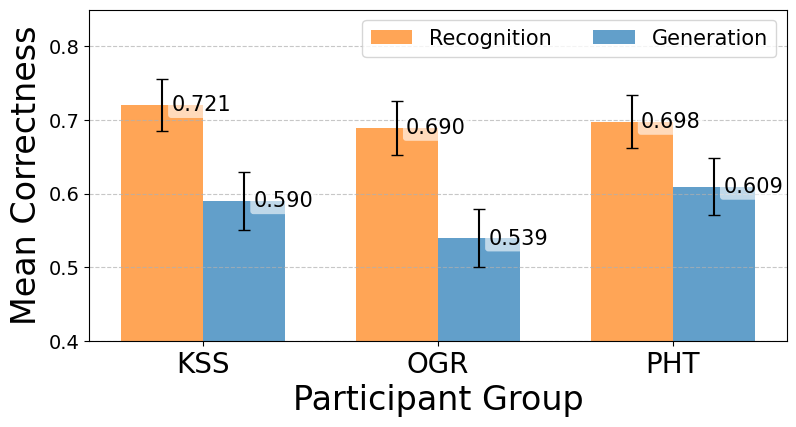
实验结果表明,PhoniTale在自动化指标(如BLEU和ROUGE)上显著优于之前的自动化助记符生成方法。在人类参与的短期回忆测试中,PhoniTale生成的助记符效果与人工编写的助记符相当,且明显优于其他自动化方法。具体性能提升数据未在摘要中给出,属于未知信息。
🎯 应用场景
PhoniTale可应用于在线语言学习平台、移动学习应用等场景,帮助学习者更有效地记忆外语词汇。该研究的实际价值在于降低了跨语系语言学习的难度,提升了学习效率。未来,该技术可扩展到更多语种,并与其他语言学习技术相结合,构建更智能化的语言学习系统。
📄 摘要(原文)
Vocabulary acquisition poses a significant challenge for second-language (L2) learners, especially when learning typologically distant languages such as English and Korean, where phonological and structural mismatches complicate vocabulary learning. Recently, large language models (LLMs) have been used to generate keyword mnemonics by leveraging similar keywords from a learner's first language (L1) to aid in acquiring L2 vocabulary. However, most methods still rely on direct IPA-based phonetic matching or employ LLMs without phonological guidance. In this paper, we present PhoniTale, a novel cross-lingual mnemonic generation system that performs IPA-based phonological adaptation and syllable-aware alignment to retrieve L1 keyword sequence and uses LLMs to generate verbal cues. We evaluate PhoniTale through automated metrics and a short-term recall test with human participants, comparing its output to human-written and prior automated mnemonics. Our findings show that PhoniTale consistently outperforms previous automated approaches and achieves quality comparable to human-written mnemonics.