Controlling What You Share: Assessing Language Model Adherence to Privacy Preferences
作者: Guillem Ramírez, Alexandra Birch, Ivan Titov
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2025-10-17)
💡 一句话要点
提出基于隐私配置文件的LLM查询重写框架,提升用户数据隐私保护。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐私保护 大型语言模型 查询重写 隐私配置文件 本地模型
📋 核心要点
- 现有LLM服务通常需要用户向服务提供商暴露数据,存在隐私泄露风险。
- 提出一种基于本地模型和隐私配置文件的查询重写框架,在保证性能的同时保护用户隐私。
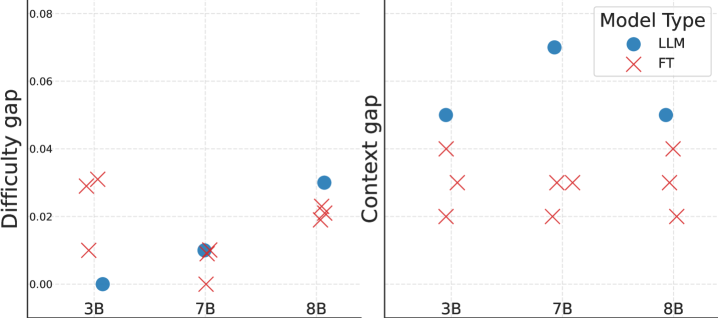
- 实验表明,微调后的轻量级本地LLM在隐私保护方面优于大型零样本模型,且性能相当。
📝 摘要(中文)
大型语言模型(LLMs)主要通过商业API访问,这通常需要用户将其数据暴露给服务提供商。本文探讨了用户如何通过使用隐私配置文件来控制其数据:这些配置文件是简单的自然语言指令,用于说明应该和不应该透露的内容。我们构建了一个框架,其中本地模型使用这些指令来重写查询,仅隐藏用户认为敏感的细节,然后再将其发送到外部模型,从而平衡隐私和性能。为了支持这项研究,我们引入了PEEP,这是一个多语言数据集,包含真实用户查询,这些查询被注释以标记私人内容,并与合成的隐私配置文件配对。使用轻量级本地LLM的实验表明,经过微调后,它们不仅实现了显着更好的隐私保护,而且匹配或超过了更大的零样本模型的性能。同时,该系统在完全遵守用户指令方面仍然面临挑战,这突显了需要更好地理解用户定义的隐私偏好的模型。
🔬 方法详解
问题定义:论文旨在解决用户在使用大型语言模型API时,如何保护自身隐私数据的问题。现有方法直接将用户查询发送给服务提供商,存在隐私泄露的风险。用户缺乏对自身数据使用的控制权,难以避免敏感信息被不当利用。
核心思路:论文的核心思路是引入一个本地模型,该模型根据用户定义的隐私配置文件,对原始查询进行重写,去除或泛化其中的敏感信息,然后再将处理后的查询发送给外部的LLM API。这样,用户可以在本地控制哪些信息被共享,从而保护隐私。
技术框架:整体框架包含以下几个主要模块:1) 用户定义隐私配置文件,指定需要保护的敏感信息类型。2) 本地LLM,负责根据隐私配置文件重写用户查询。3) 外部LLM API,接收重写后的查询并生成回复。4) PEEP数据集,用于训练和评估本地LLM的隐私保护能力。框架的目标是在隐私保护和性能之间取得平衡。
关键创新:论文的关键创新在于提出了一种基于隐私配置文件的查询重写方法,允许用户自定义隐私保护策略。此外,论文还构建了PEEP数据集,为隐私保护相关的研究提供了数据支持。与现有方法相比,该方法更加灵活和可控,能够更好地满足用户的个性化隐私需求。
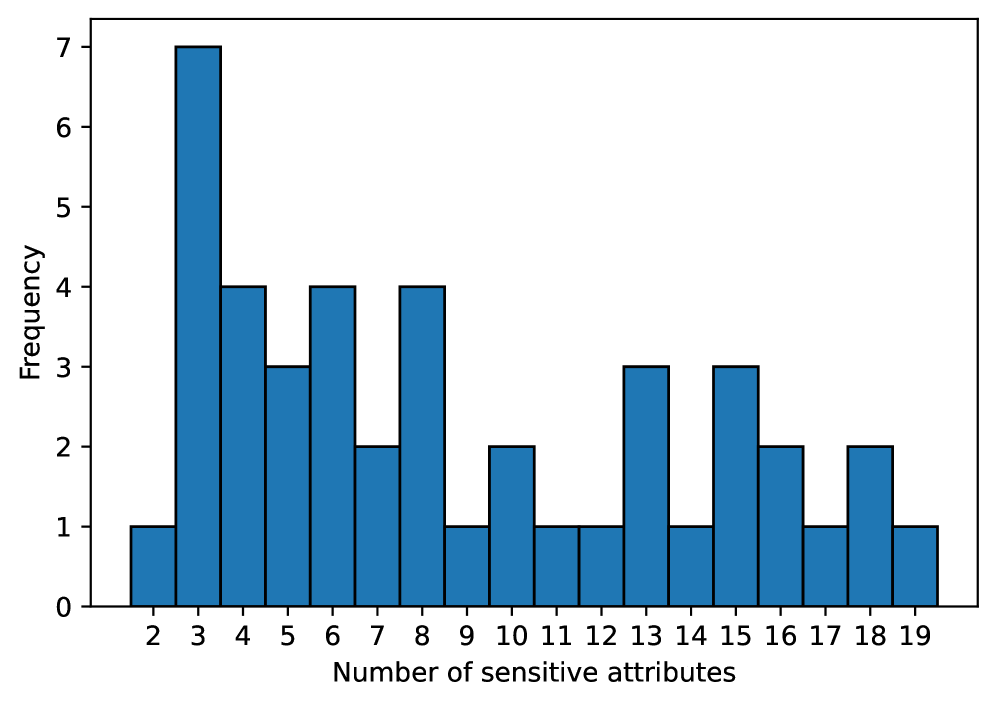
关键设计:PEEP数据集包含真实用户查询,并标注了其中的私人内容。隐私配置文件使用自然语言描述,易于用户理解和使用。本地LLM采用轻量级模型,以降低计算成本和延迟。论文通过微调本地LLM,使其能够更好地理解用户定义的隐私偏好,并生成高质量的重写查询。损失函数的设计目标是最大化隐私保护效果,同时最小化对查询性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过微调的轻量级本地LLM在隐私保护方面取得了显著提升,能够有效识别和去除查询中的敏感信息。与大型零样本模型相比,本地模型不仅实现了更好的隐私保护效果,而且在某些情况下,性能还略有提升。这表明,通过合理的模型设计和训练,可以在隐私保护和性能之间取得良好的平衡。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私的场景,例如智能客服、医疗咨询、金融服务等。通过部署本地隐私保护模块,用户可以在享受LLM强大功能的同时,有效控制个人数据的泄露风险。未来,该技术有望成为LLM应用的重要组成部分,促进人工智能技术的安全可靠发展。
📄 摘要(原文)
Large language models (LLMs) are primarily accessed via commercial APIs, but this often requires users to expose their data to service providers. In this paper, we explore how users can stay in control of their data by using privacy profiles: simple natural language instructions that say what should and should not be revealed. We build a framework where a local model uses these instructions to rewrite queries, only hiding details deemed sensitive by the user, before sending them to an external model, thus balancing privacy with performance. To support this research, we introduce PEEP, a multilingual dataset of real user queries annotated to mark private content and paired with synthetic privacy profiles. Experiments with lightweight local LLMs show that, after fine-tuning, they not only achieve markedly better privacy preservation but also match or exceed the performance of much larger zero-shot models. At the same time, the system still faces challenges in fully adhering to user instructions, underscoring the need for models with a better understanding of user-defined privacy preferences.