On the Bias of Next-Token Predictors Toward Systematically Inefficient Reasoning: A Shortest-Path Case Study
作者: Riccardo Alberghi, Elizaveta Demyanenko, Luca Biggio, Luca Saglietti
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-07 (更新: 2025-11-01)
💡 一句话要点
研究表明,在最短路径推理任务中,基于低效推理轨迹训练的LLM泛化性更强。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理 最短路径 泛化能力 思维链
📋 核心要点
- 大型语言模型在推理过程中,计算资源的分配和推理轨迹的组织方式至关重要。
- 该研究通过最短路径任务,对比了基于最优和低效推理轨迹训练的LLM的泛化能力。
- 实验结果表明,在低效轨迹上训练的模型泛化能力更强,这与模型对token预测的置信度相关。
📝 摘要(中文)
自然语言处理的最新进展强调了提高大型语言模型(LLM)推理能力的两个关键因素:(i)分配更多的测试时计算资源通常有助于解决更困难的问题,但往往会在推理过程中引入冗余;(ii)当推理是系统化和增量式的,形成类似于人类解决问题的结构化思维链(CoT)时,计算是最有效的。为了孤立地研究这些因素,我们引入了一个基于分层图中最短路径任务的可控环境。我们使用自定义分词器在问题-轨迹-答案三元组上训练仅解码器Transformer,比较了在最优自底向上动态规划轨迹上训练的模型与在涉及回溯的更长、有效轨迹上训练的模型。令人惊讶的是,在相同的训练token预算下,在低效轨迹上训练的模型对未见图的泛化能力更好。这种优势并非仅仅源于长度——将任意冗余注入推理轨迹并不能提供帮助,甚至可能损害性能。相反,我们发现泛化能力与模型对下一个token预测的置信度相关,这表明长、连贯且局部增量的轨迹使训练信号更容易优化。
🔬 方法详解
问题定义:现有的大型语言模型在推理时,过度依赖计算资源,导致推理过程冗余,缺乏系统性和增量性。尤其是在解决复杂问题时,模型往往难以形成结构化的思维链。因此,如何提高LLM的推理效率和泛化能力是一个重要的研究问题。
核心思路:该论文的核心思路是,通过在包含冗余信息的推理轨迹上训练LLM,可以提高其泛化能力。作者假设,这种冗余信息可以帮助模型更好地理解问题的结构,从而提高其在未见数据上的表现。这种冗余并非任意的,而是需要保持推理过程的连贯性和局部增量性。
技术框架:该研究构建了一个基于分层图的最短路径任务。模型接收问题(起点和终点),生成推理轨迹(路径),并最终输出答案(最短路径长度)。使用decoder-only Transformer模型,并采用自定义的分词器。训练数据包括问题-轨迹-答案三元组,其中轨迹可以是基于动态规划的最优轨迹,也可以是包含回溯的低效轨迹。
关键创新:该研究的关键创新在于,它挑战了传统的“最优轨迹训练”的观点,发现基于低效但连贯的推理轨迹训练的模型,在泛化能力上优于基于最优轨迹训练的模型。这表明,LLM的训练目标不仅仅是学习最优解,更重要的是学习如何进行有效的推理。
关键设计:实验中,作者控制了训练token的数量,以确保不同训练策略之间的公平性。他们比较了在最优轨迹、低效轨迹和随机冗余轨迹上训练的模型。此外,作者还分析了模型对下一个token预测的置信度,发现泛化能力与置信度之间存在相关性。损失函数采用标准的交叉熵损失函数,网络结构为标准的decoder-only Transformer。
🖼️ 关键图片


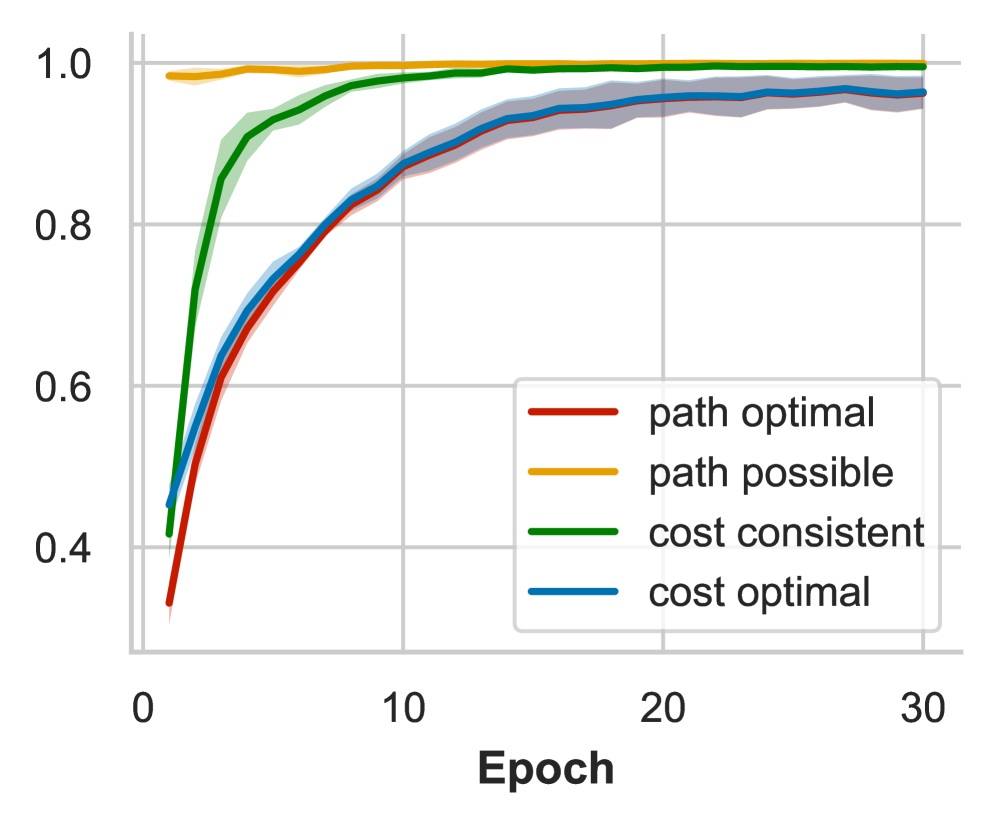
📊 实验亮点
实验结果表明,在相同的训练token预算下,基于低效推理轨迹训练的模型,在未见图上的泛化能力显著优于基于最优轨迹训练的模型。同时,研究发现,泛化能力与模型对下一个token预测的置信度呈正相关,表明连贯且局部增量的推理轨迹有助于优化训练信号。
🎯 应用场景
该研究成果可应用于提高大型语言模型在复杂推理任务中的性能,例如知识图谱推理、规划和决策等领域。通过设计更有效的训练策略,可以使LLM在计算资源有限的情况下,更好地解决实际问题。此外,该研究也为理解LLM的推理机制提供了新的视角。
📄 摘要(原文)
Recent advances in natural language processing highlight two key factors for improving reasoning in large language models (LLMs): (i) allocating more test-time compute tends to help on harder problems but often introduces redundancy in the reasoning trace, and (ii) compute is most effective when reasoning is systematic and incremental, forming structured chains of thought (CoTs) akin to human problem-solving. To study these factors in isolation, we introduce a controlled setting based on shortest-path tasks in layered graphs. We train decoder-only transformers on question-trace-answer triples using a custom tokenizer, comparing models trained on optimal bottom-up dynamic programming traces with those trained on longer, valid traces involving backtracking. Surprisingly, with the same training-token budget, models trained on inefficient traces generalize better to unseen graphs. This benefit is not due to length alone-injecting arbitrary redundancy into reasoning traces fails to help and can even hurt performance. Instead, we find that generalization correlates with the model's confidence in next-token prediction, suggesting that long, coherent, and locally incremental traces make the training signal easier to optimize.