Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
作者: Yuanzhe Hu, Yu Wang, Julian McAuley
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2025-09-26)
备注: Y. Hu and Y. Wang contribute equally
💡 一句话要点
提出MemoryAgentBench,用于评估LLM Agent在多轮交互中的记忆能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 记忆能力 多轮交互 评测基准 长文本理解
📋 核心要点
- 现有LLM Agent基准测试缺乏对记忆能力的全面评估,尤其是在多轮交互场景下,无法有效衡量Agent的长期信息处理能力。
- 论文提出MemoryAgentBench,通过将现有长文本数据集和新建数据集转化为多轮交互形式,模拟Agent的增量信息处理过程。
- 实验结果表明,现有方法在准确检索、测试时学习、长程理解和选择性遗忘四个核心记忆能力方面表现不足,需要进一步研究。
📝 摘要(中文)
现有的大语言模型(LLM)Agent评测基准主要关注推理、规划和执行能力,而记忆能力(包括Agent如何记忆、更新和检索长期信息)由于缺乏基准而被低估。我们将具有记忆机制的Agent称为记忆Agent。本文基于记忆科学和认知科学的经典理论,确定了记忆Agent的四个核心能力:准确检索、测试时学习、长程理解和选择性遗忘。现有的基准要么依赖于有限的上下文长度,要么是为静态、长上下文设置(如基于书籍的问答)定制的,这不能反映记忆Agent以增量方式累积信息的交互式、多轮性质。此外,没有现有的基准涵盖所有四个能力。我们引入了MemoryAgentBench,这是一个专门为记忆Agent设计的新基准。我们的基准将现有的长上下文数据集和新构建的数据集转换为多轮格式,有效地模拟了记忆Agent的增量信息处理特性。通过仔细选择和管理数据集,我们的基准全面覆盖了上述四个核心记忆能力,从而为评估记忆质量提供了一个系统且具有挑战性的测试平台。我们评估了各种记忆Agent,从简单的基于上下文和检索增强生成(RAG)系统到具有外部记忆模块和工具集成的高级Agent。实验结果表明,当前的方法未能掌握所有四个能力,突显了进一步研究LLM Agent的综合记忆机制的必要性。
🔬 方法详解
问题定义:现有LLM Agent的评测基准主要关注推理、规划和执行能力,而忽略了记忆能力,尤其是在多轮交互场景下的长期记忆、更新和检索能力。现有基准要么上下文长度有限,要么是静态长文本问答,无法模拟Agent在真实交互中逐步积累信息的过程。因此,需要一个专门的基准来全面评估LLM Agent的记忆能力。
核心思路:论文的核心思路是构建一个多轮交互式的评测基准,该基准能够模拟Agent在真实场景中逐步积累信息的过程,并全面评估其在准确检索、测试时学习、长程理解和选择性遗忘四个方面的能力。通过将现有长文本数据集和新构建的数据集转化为多轮交互形式,可以有效地模拟Agent的增量信息处理特性。
技术框架:MemoryAgentBench的技术框架主要包括以下几个部分:1) 数据集构建:将现有长文本数据集(例如书籍、文档)和新构建的数据集转化为多轮交互形式。2) 任务设计:设计一系列任务,用于评估Agent在准确检索、测试时学习、长程理解和选择性遗忘四个方面的能力。3) 评估指标:定义一系列评估指标,用于量化Agent在各个任务上的表现。4) Agent评估:使用MemoryAgentBench评估各种LLM Agent,包括基于上下文的Agent、RAG Agent以及具有外部记忆模块的Agent。
关键创新:MemoryAgentBench的关键创新在于其多轮交互式的评测方式,以及对Agent记忆能力的全面评估。与现有基准相比,MemoryAgentBench能够更真实地模拟Agent在真实场景中的应用,并更全面地评估其记忆能力。此外,MemoryAgentBench还首次提出了Agent记忆能力的四个核心要素:准确检索、测试时学习、长程理解和选择性遗忘。
关键设计:MemoryAgentBench的关键设计包括:1) 多轮交互形式:将数据集转化为多轮对话形式,模拟Agent逐步积累信息的过程。2) 任务多样性:设计多种任务,覆盖Agent记忆能力的四个核心要素。3) 评估指标的合理性:选择合适的评估指标,量化Agent在各个任务上的表现。例如,可以使用准确率、召回率、F1值等指标评估Agent的检索能力,使用困惑度、BLEU等指标评估Agent的生成能力。
🖼️ 关键图片

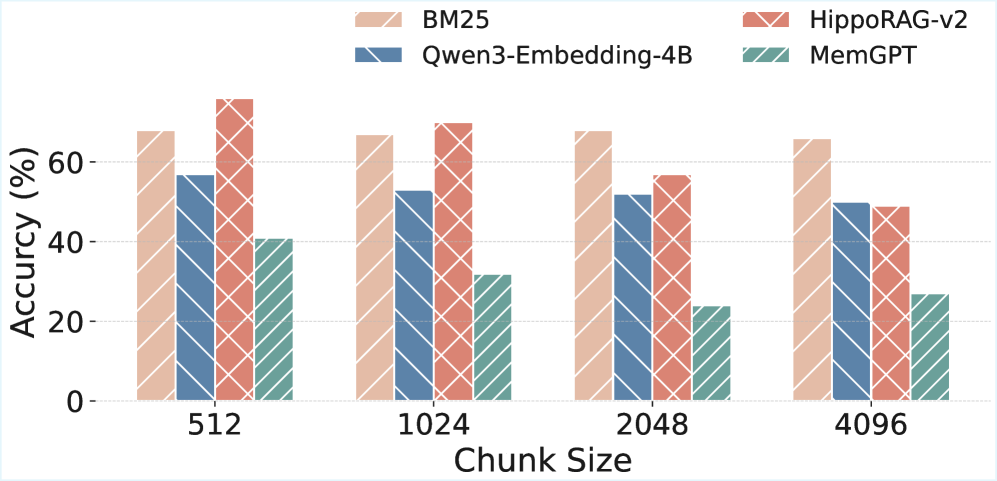
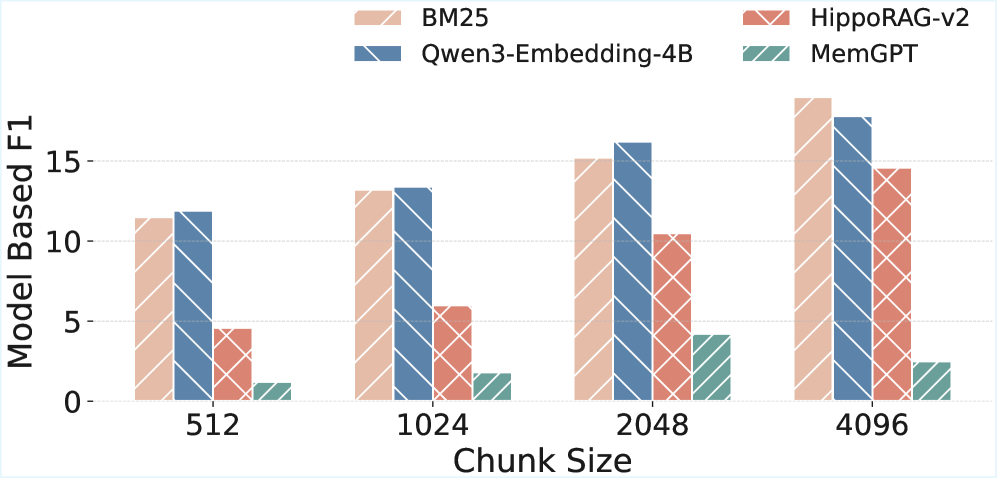
📊 实验亮点
实验结果表明,现有的LLM Agent在MemoryAgentBench上的表现与人类水平存在较大差距,尤其是在测试时学习和选择性遗忘方面。例如,简单的基于上下文的Agent在长程理解任务上的准确率较低,而RAG Agent在更新记忆时容易出现信息冲突。这些结果表明,需要进一步研究LLM Agent的综合记忆机制。
🎯 应用场景
该研究成果可应用于开发更智能、更可靠的LLM Agent,例如智能助手、聊天机器人、知识库问答系统等。通过提升Agent的记忆能力,可以使其更好地理解用户意图,提供更个性化、更准确的服务。此外,该基准也可用于指导LLM Agent的训练和优化,促进相关技术的发展。
📄 摘要(原文)
Recent benchmarks for Large Language Model (LLM) agents primarily focus on evaluating reasoning, planning, and execution capabilities, while another critical component-memory, encompassing how agents memorize, update, and retrieve long-term information-is under-evaluated due to the lack of benchmarks. We term agents with memory mechanisms as memory agents. In this paper, based on classic theories from memory science and cognitive science, we identify four core competencies essential for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting. Existing benchmarks either rely on limited context lengths or are tailored for static, long-context settings like book-based QA, which do not reflect the interactive, multi-turn nature of memory agents that incrementally accumulate information. Moreover, no existing benchmarks cover all four competencies. We introduce MemoryAgentBench, a new benchmark specifically designed for memory agents. Our benchmark transforms existing long-context datasets and incorporates newly constructed datasets into a multi-turn format, effectively simulating the incremental information processing characteristic of memory agents. By carefully selecting and curating datasets, our benchmark provides comprehensive coverage of the four core memory competencies outlined above, thereby offering a systematic and challenging testbed for assessing memory quality. We evaluate a diverse set of memory agents, ranging from simple context-based and retrieval-augmented generation (RAG) systems to advanced agents with external memory modules and tool integration. Empirical results reveal that current methods fall short of mastering all four competencies, underscoring the need for further research into comprehensive memory mechanisms for LLM agents.