Interpretable Mnemonic Generation for Kanji Learning via Expectation-Maximization
作者: Jaewook Lee, Alexander Scarlatos, Andrew Lan
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2025-08-29)
备注: The Conference on Empirical Methods in Natural Language Processing (EMNLP 2025)
💡 一句话要点
提出基于期望最大化的可解释助记符生成方法,辅助汉字学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 汉字学习 助记符生成 期望最大化 可解释性 自然语言处理
📋 核心要点
- 现有基于大型语言模型的助记符生成方法缺乏可解释性,难以理解其生成机制。
- 论文提出一种生成框架,显式建模助记符构建过程,并使用期望最大化算法学习潜在规则。
- 实验表明,该方法在冷启动设置下表现良好,并能深入了解有效助记符的创建机制。
📝 摘要(中文)
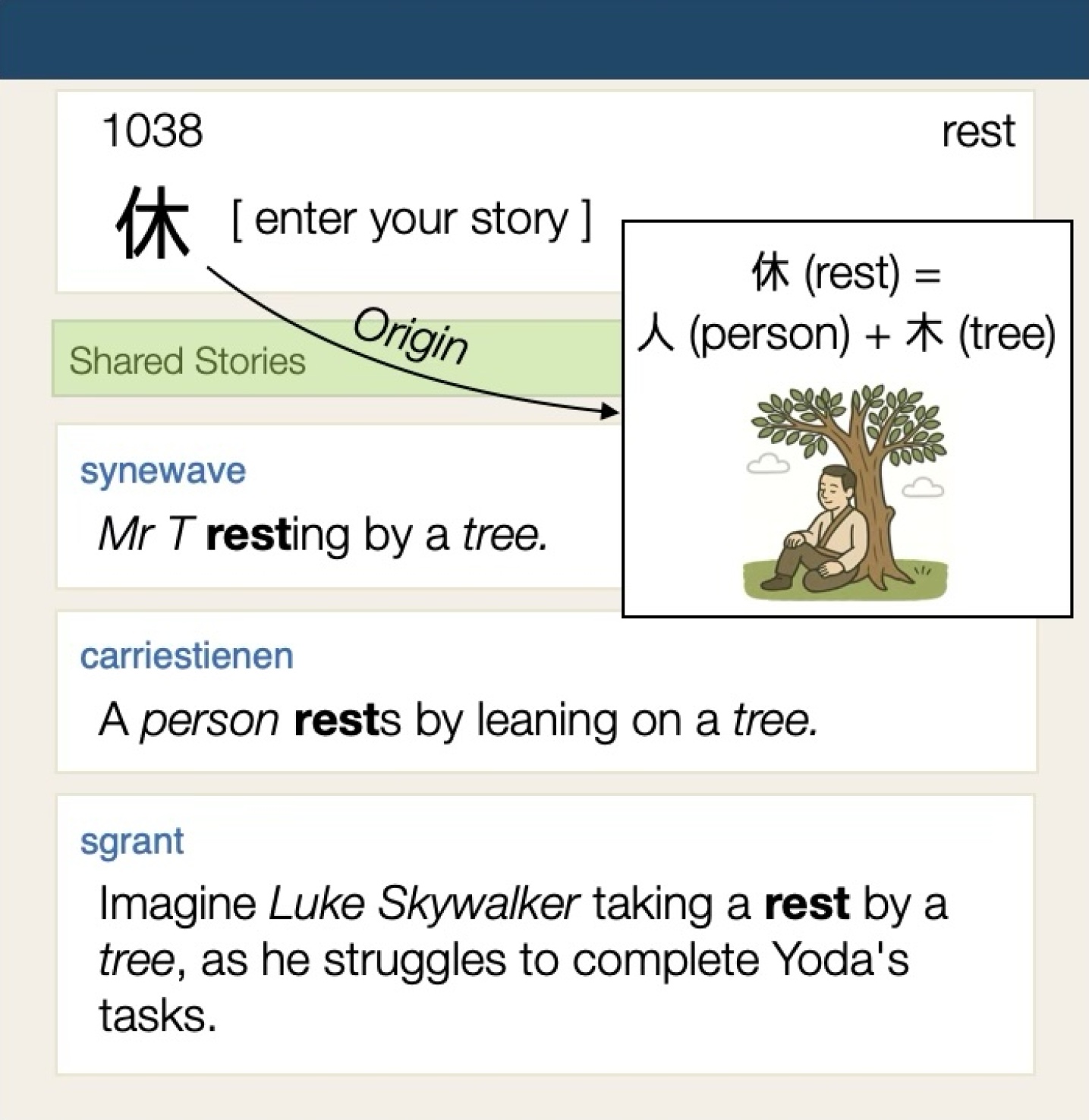
由于文字系统的差异,对于母语为罗马字母的学习者来说,学习日语词汇是一个挑战。日语结合了平假名等音节文字和汉字,汉字是源于中国的表意文字。汉字因其复杂性和数量而变得复杂。关键词助记符是辅助记忆的常用策略,通常利用汉字的构成结构来形成生动的联想。尽管最近努力使用大型语言模型(LLM)来帮助学习者,但现有的基于LLM的关键词助记符生成方法就像一个黑盒子,提供的可解释性有限。我们提出了一个生成框架,该框架将助记符构建过程明确地建模为由一组通用规则驱动,并使用一种新颖的期望最大化类型算法来学习它们。通过在线平台上的学习者编写的助记符进行训练,我们的方法学习潜在结构和构成规则,从而实现可解释和系统的助记符生成。实验表明,我们的方法在新学习者的冷启动设置中表现良好,同时提供了对有效助记符创建背后机制的深入了解。
🔬 方法详解
问题定义:论文旨在解决日语学习者在记忆汉字时遇到的困难,特别是现有基于大型语言模型的助记符生成方法缺乏透明度和可解释性的问题。这些方法通常作为黑盒运行,学习者无法理解助记符的生成逻辑,从而限制了其学习效果和信任度。
核心思路:论文的核心思路是将助记符的生成过程建模为一个由一组通用规则驱动的过程。通过学习这些规则,可以使生成的助记符更具可解释性,并帮助学习者理解汉字的构成和含义。这种方法借鉴了人类构建助记符的常见策略,例如利用汉字的部首、发音或形状进行联想。
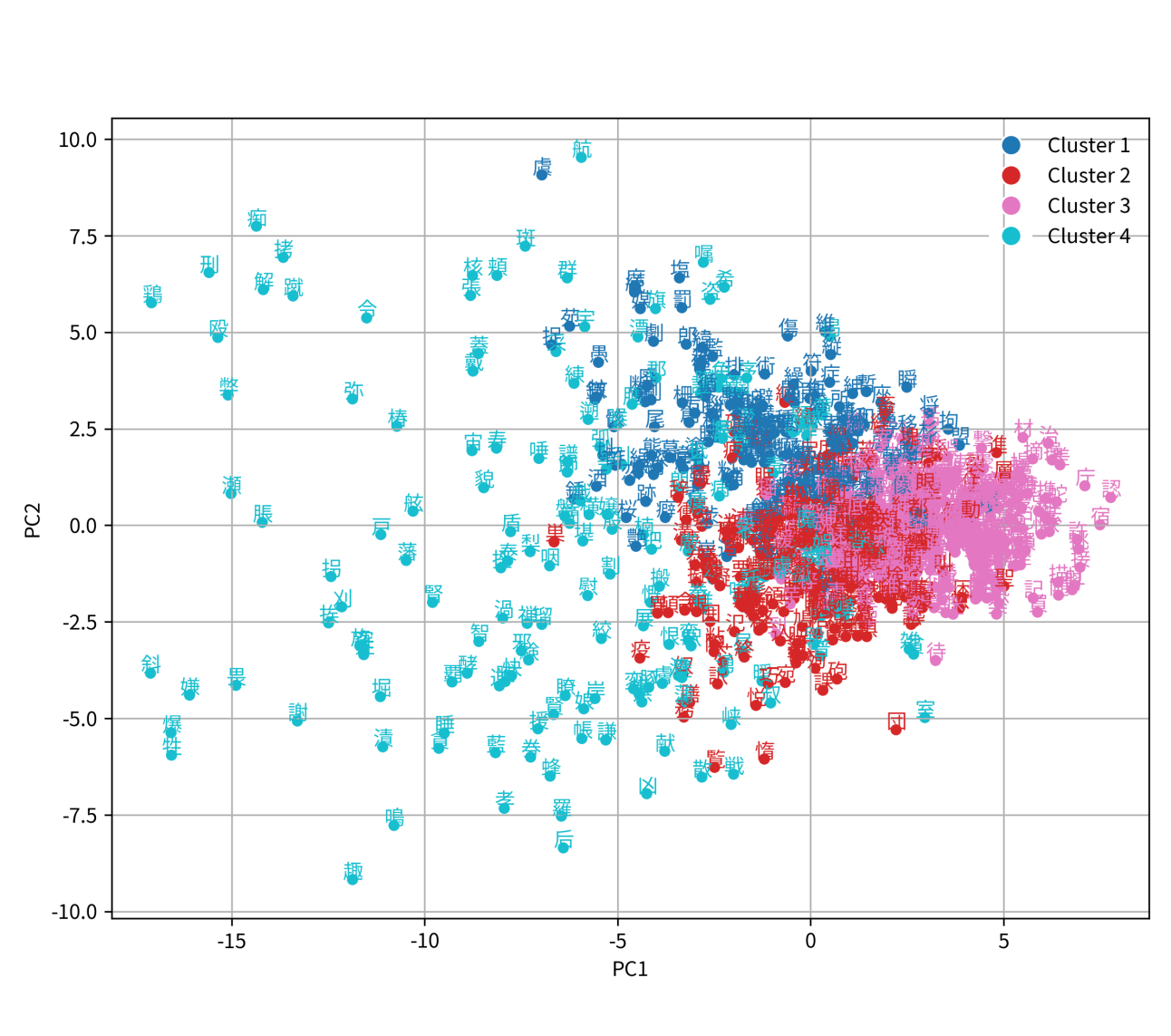
技术框架:该方法采用一个生成框架,包含以下主要模块:1) 数据收集:从在线平台收集学习者编写的汉字助记符。2) 规则定义:定义一组通用的助记符构建规则,例如“利用部首”、“利用发音”等。3) 期望最大化(EM)算法:使用EM算法学习潜在结构和构成规则。E步估计潜在变量(例如,每个助记符使用的规则),M步更新模型参数(例如,规则的权重)。4) 助记符生成:根据学习到的规则,为新的汉字生成助记符。
关键创新:该方法最重要的技术创新点在于其可解释性。与传统的黑盒方法不同,该方法显式地建模了助记符的构建过程,并学习了潜在的规则。这使得学习者可以理解助记符的生成逻辑,并更好地记忆汉字。此外,该方法还提出了一种新颖的期望最大化类型算法,用于学习潜在结构和构成规则。
关键设计:论文的关键设计包括:1) 规则的定义:选择合适的助记符构建规则至关重要。论文可能需要进行实验或分析,以确定哪些规则最有效。2) EM算法的实现:EM算法的收敛性和效率是关键。论文可能需要使用一些技巧来加速收敛,例如使用合适的初始化方法或调整学习率。3) 损失函数的设计:损失函数需要能够反映助记符的质量和可解释性。论文可能需要设计一个定制的损失函数,以鼓励生成高质量的助记符。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了该方法在冷启动设置下的有效性,即对于没有历史学习数据的用户,该方法也能生成高质量的助记符。具体性能数据未知,但论文强调该方法能够提供对有效助记符创建背后机制的深入了解,这对于提升学习效果至关重要。与基线方法相比,该方法在可解释性方面具有显著优势。
🎯 应用场景
该研究成果可应用于在线日语学习平台、汉字学习App等,为学习者提供个性化、可解释的助记符,辅助记忆汉字。此外,该方法还可以推广到其他语言的学习中,例如中文、韩文等,具有广泛的应用前景。未来,该研究可以进一步探索更复杂的助记符构建规则,并结合多模态信息(例如图像、声音)来生成更生动、有效的助记符。
📄 摘要(原文)
Learning Japanese vocabulary is a challenge for learners from Roman alphabet backgrounds due to script differences. Japanese combines syllabaries like hiragana with kanji, which are logographic characters of Chinese origin. Kanji are also complicated due to their complexity and volume. Keyword mnemonics are a common strategy to aid memorization, often using the compositional structure of kanji to form vivid associations. Despite recent efforts to use large language models (LLMs) to assist learners, existing methods for LLM-based keyword mnemonic generation function as a black box, offering limited interpretability. We propose a generative framework that explicitly models the mnemonic construction process as driven by a set of common rules, and learn them using a novel Expectation-Maximization-type algorithm. Trained on learner-authored mnemonics from an online platform, our method learns latent structures and compositional rules, enabling interpretable and systematic mnemonics generation. Experiments show that our method performs well in the cold-start setting for new learners while providing insight into the mechanisms behind effective mnemonic creation.