SMART: Simulated Students Aligned with Item Response Theory for Question Difficulty Prediction
作者: Alexander Scarlatos, Nigel Fernandez, Christopher Ormerod, Susan Lottridge, Andrew Lan
分类: cs.CL, cs.CY, cs.LG
发布日期: 2025-07-07 (更新: 2025-09-18)
备注: Published in EMNLP 2025: The 2025 Conference on Empirical Methods in Natural Language Processing
💡 一句话要点
SMART:通过模拟学生与IRT对齐,预测题目难度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 题目难度预测 项目反应理论 模拟学生 直接偏好优化 大型语言模型
📋 核心要点
- 传统题目难度评估依赖真实学生作答,成本高且无法应用于冷启动题目。
- SMART通过DPO将模拟学生与IRT模型对齐,从而预测开放式题目的难度。
- 实验表明,SMART通过改进的能力对齐,在题目难度预测上优于其他方法。
📝 摘要(中文)
题目难度在教育评估中至关重要,它能够准确高效地评估学生能力,并实现个性化教学以最大化学习成果。传统上,评估题目难度成本高昂,需要真实学生作答,然后拟合项目反应理论(IRT)模型以获得难度估计。这种方法无法应用于先前未见过的题目的冷启动设置。本文提出SMART(Simulated Students Aligned with IRT),一种将模拟学生与设定的能力对齐的新方法,可用于模拟以预测开放式题目的难度。我们使用直接偏好优化(DPO)实现这种对齐,其中我们基于在真实IRT模型下响应的可能性来形成偏好对。我们通过生成数千个响应进行模拟,使用基于大型语言模型(LLM)的评分模型评估它们,并将结果数据拟合到IRT模型以获得题目难度估计。通过在两个真实学生响应数据集上进行的大量实验,我们表明SMART通过利用其改进的能力对齐,优于其他题目难度预测方法。
🔬 方法详解
问题定义:论文旨在解决教育评估中题目难度预测的问题,尤其是在冷启动场景下,即对于之前未见过的题目,传统方法需要大量真实学生作答数据才能进行难度评估,成本高昂且效率低下。现有方法难以在没有真实数据的情况下准确预测题目难度。
核心思路:论文的核心思路是利用大型语言模型(LLM)模拟学生作答,并通过直接偏好优化(DPO)使模拟学生的作答行为与项目反应理论(IRT)模型对齐。通过这种方式,可以生成大量模拟数据,从而在没有真实学生数据的情况下预测题目难度。
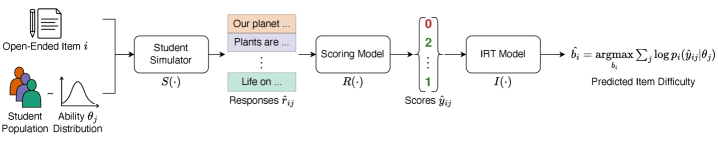
技术框架:SMART方法包含以下几个主要阶段:1) 模拟学生生成:使用LLM生成模拟学生的作答;2) 能力对齐:使用DPO方法,基于真实IRT模型下的作答概率,优化LLM,使其生成的作答更符合IRT理论;3) 题目难度预测:使用LLM对模拟作答进行评分,并将评分数据拟合到IRT模型,从而得到题目难度估计。
关键创新:SMART的关键创新在于使用DPO方法将模拟学生与IRT模型对齐。传统方法通常直接使用LLM生成作答,但LLM的作答行为可能与IRT理论不一致,导致难度预测不准确。SMART通过DPO优化LLM,使其生成的作答更符合IRT理论,从而提高了难度预测的准确性。
关键设计:SMART的关键设计包括:1) 使用DPO损失函数优化LLM,DPO损失函数基于真实IRT模型下的作答概率,鼓励LLM生成更符合IRT理论的作答;2) 使用LLM作为评分模型,对模拟作答进行评分,评分结果作为IRT模型的输入;3) 使用标准的IRT模型(如2PL或3PL模型)进行题目难度估计。
🖼️ 关键图片

📊 实验亮点
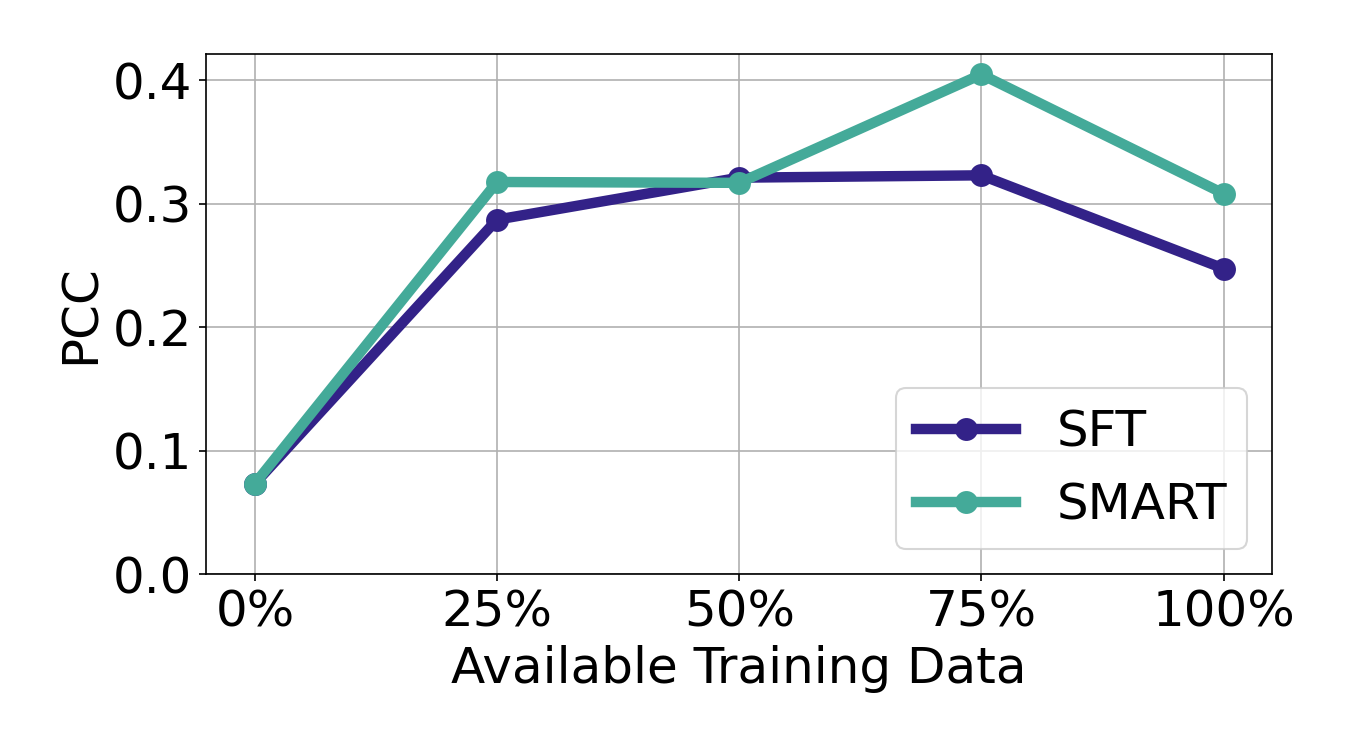
SMART在两个真实学生响应数据集上进行了实验,结果表明,SMART在题目难度预测方面优于其他方法。具体来说,SMART通过改进的能力对齐,能够更准确地预测题目的难度,从而提高了教育评估的准确性和效率。论文中提供了具体的性能数据,与其他基线方法进行了详细的对比。
🎯 应用场景
SMART可应用于在线教育平台、自适应学习系统和教育游戏等领域。它可以帮助教师和教育机构更有效地评估题目难度,从而更好地了解学生的学习情况,并为学生提供个性化的学习资源和练习。此外,SMART还可以用于新题目的难度预测,从而降低教育评估的成本。
📄 摘要(原文)
Item (question) difficulties play a crucial role in educational assessments, enabling accurate and efficient assessment of student abilities and personalization to maximize learning outcomes. Traditionally, estimating item difficulties can be costly, requiring real students to respond to items, followed by fitting an item response theory (IRT) model to get difficulty estimates. This approach cannot be applied to the cold-start setting for previously unseen items either. In this work, we present SMART (Simulated Students Aligned with IRT), a novel method for aligning simulated students with instructed ability, which can then be used in simulations to predict the difficulty of open-ended items. We achieve this alignment using direct preference optimization (DPO), where we form preference pairs based on how likely responses are under a ground-truth IRT model. We perform a simulation by generating thousands of responses, evaluating them with a large language model (LLM)-based scoring model, and fit the resulting data to an IRT model to obtain item difficulty estimates. Through extensive experiments on two real-world student response datasets, we show that SMART outperforms other item difficulty prediction methods by leveraging its improved ability alignment.