Co-DETECT: Collaborative Discovery of Edge Cases in Text Classification
作者: Chenfei Xiong, Jingwei Ni, Yu Fan, Vilém Zouhar, Donya Rooein, Lorena Calvo-Bartolomé, Alexander Hoyle, Zhijing Jin, Mrinmaya Sachan, Markus Leippold, Dirk Hovy, Mennatallah El-Assady, Elliott Ash
分类: cs.CL
发布日期: 2025-07-07
💡 一句话要点
Co-DETECT:结合人类专家知识与大语言模型,协同发现文本分类中的边界案例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 边界案例 大型语言模型 混合主动学习 协同标注 领域专家 代码本
📋 核心要点
- 现有文本分类方法在处理边界案例时存在不足,难以捕捉数据中的细微差别和复杂模式。
- Co-DETECT框架结合人类专家知识与LLM自动标注,迭代式地发现并处理文本分类中的边界案例。
- 实验结果表明,Co-DETECT能够有效地识别和处理边界案例,提升文本分类的性能和鲁棒性。
📝 摘要(中文)
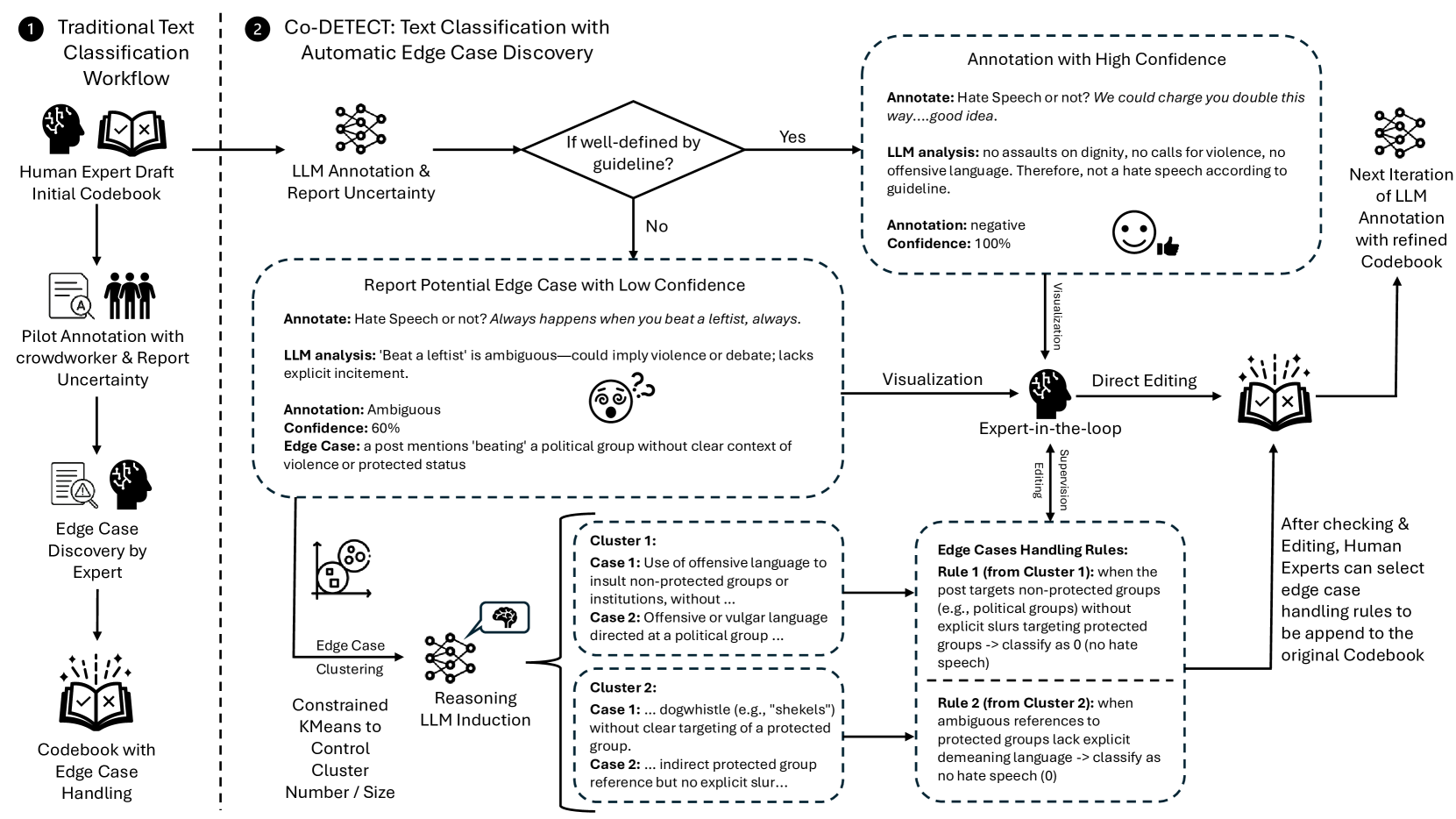
本文提出了一种新颖的混合主动式标注框架Co-DETECT(文本分类中边界案例的协同发现),该框架集成了人类专业知识与由大型语言模型(LLM)指导的自动标注。Co-DETECT从领域专家提供的初始草图级代码本和数据集开始,然后利用LLM标注数据并识别初始代码本未充分描述的边界案例。具体来说,Co-DETECT标记具有挑战性的示例,归纳出边界案例的高级、可泛化的描述,并协助用户合并边界案例处理规则以改进代码本。这种迭代过程能够通过紧凑、可泛化的标注规则更有效地处理细微的现象。广泛的用户研究、定性和定量分析证明了Co-DETECT的有效性。
🔬 方法详解
问题定义:论文旨在解决文本分类任务中,现有方法难以有效识别和处理边界案例的问题。这些边界案例往往具有细微的差别和复杂的模式,导致模型泛化能力不足,在实际应用中表现不佳。现有方法依赖人工标注,成本高昂且难以覆盖所有可能的边界情况。
核心思路:Co-DETECT的核心思路是结合人类专家的领域知识和大型语言模型(LLM)的自动标注能力,通过迭代的方式发现并处理边界案例。人类专家提供初始的代码本和数据集,LLM负责标注数据并识别潜在的边界案例,然后人类专家根据LLM的反馈改进代码本,从而提高模型对边界案例的识别能力。
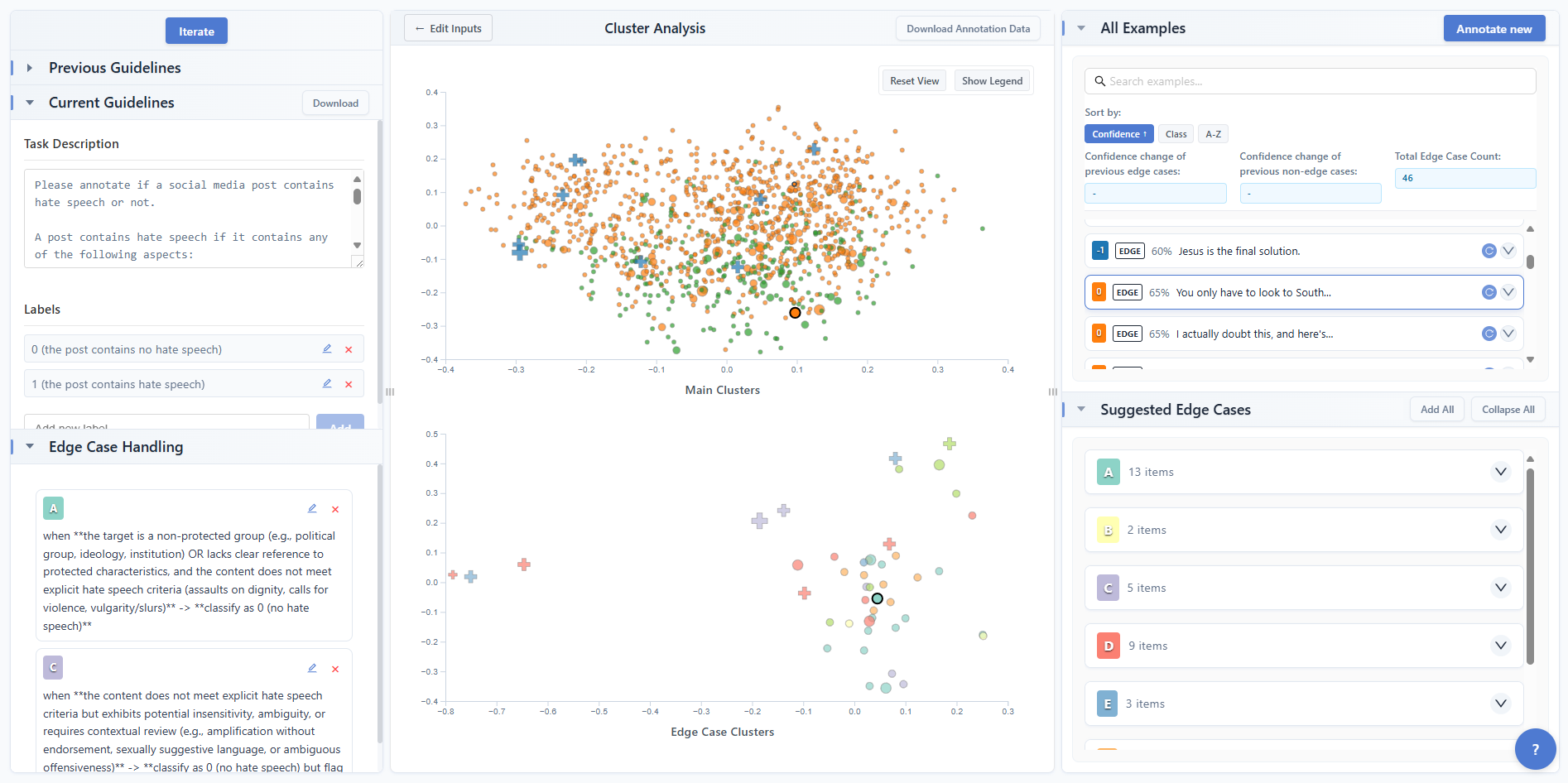
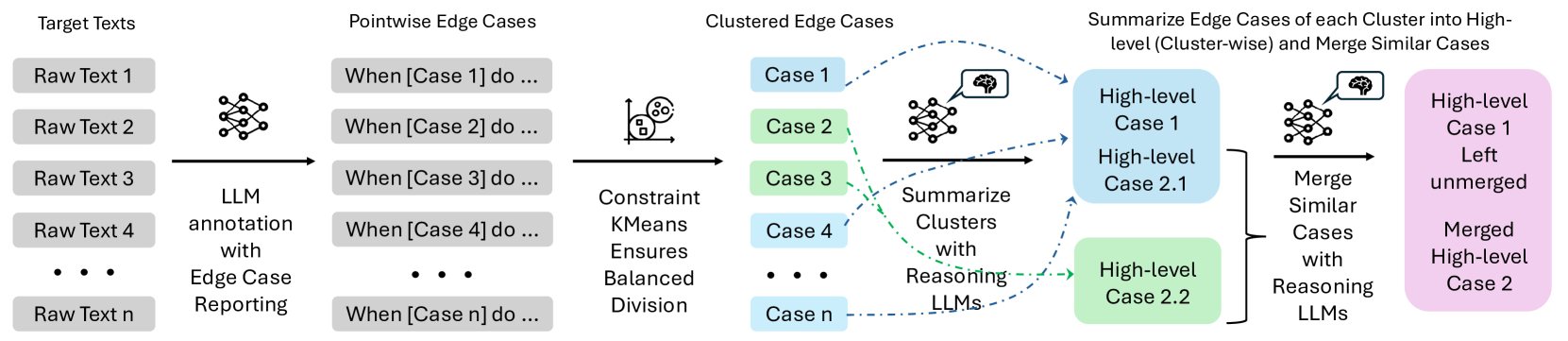
技术框架:Co-DETECT框架包含以下主要模块:1) 初始化:领域专家提供初始代码本和数据集。2) LLM标注:利用LLM对数据进行自动标注,并识别出与现有代码本不一致或难以分类的样本,作为潜在的边界案例。3) 边界案例分析:人类专家分析LLM标记的边界案例,归纳出高层次、可泛化的描述。4) 代码本更新:人类专家根据边界案例的分析结果,更新和完善代码本,添加新的类别或修改现有类别的定义。5) 迭代优化:重复LLM标注、边界案例分析和代码本更新的过程,直到模型性能达到预期。
关键创新:Co-DETECT的关键创新在于混合主动式的标注框架,将人类专家的领域知识与LLM的自动标注能力相结合,实现了边界案例的协同发现。与传统的纯人工标注或纯自动标注方法相比,Co-DETECT能够更有效地识别和处理边界案例,降低标注成本,提高模型泛化能力。
关键设计:Co-DETECT的关键设计包括:1) 利用LLM进行自动标注,降低人工标注成本。2) 设计有效的边界案例分析方法,帮助人类专家理解和归纳边界案例的特征。3) 提供用户友好的界面,方便人类专家更新和完善代码本。4) 采用迭代优化的方式,逐步提高模型对边界案例的识别能力。具体的LLM选择、prompt设计、以及代码本更新策略等细节,可能需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过用户研究、定性和定量分析验证了Co-DETECT的有效性。实验结果表明,Co-DETECT能够显著提高文本分类模型对边界案例的识别能力,并降低标注成本。具体的性能提升幅度取决于具体的应用场景和数据集,但总体而言,Co-DETECT能够带来显著的性能提升。
🎯 应用场景
Co-DETECT框架可广泛应用于各种文本分类任务中,例如情感分析、主题分类、垃圾邮件检测等。该框架能够帮助领域专家更有效地识别和处理边界案例,提高文本分类模型的准确性和鲁棒性。此外,Co-DETECT还可以用于构建高质量的标注数据集,为其他机器学习任务提供支持。未来,该框架有望应用于更复杂的自然语言处理任务中,例如对话系统、机器翻译等。
📄 摘要(原文)
We introduce Co-DETECT (Collaborative Discovery of Edge cases in TExt ClassificaTion), a novel mixed-initiative annotation framework that integrates human expertise with automatic annotation guided by large language models (LLMs). Co-DETECT starts with an initial, sketch-level codebook and dataset provided by a domain expert, then leverages the LLM to annotate the data and identify edge cases that are not well described by the initial codebook. Specifically, Co-DETECT flags challenging examples, induces high-level, generalizable descriptions of edge cases, and assists user in incorporating edge case handling rules to improve the codebook. This iterative process enables more effective handling of nuanced phenomena through compact, generalizable annotation rules. Extensive user study, qualitative and quantitative analyses prove the effectiveness of Co-DETECT.