ArtifactsBench: Bridging the Visual-Interactive Gap in LLM Code Generation Evaluation
作者: Chenchen Zhang, Yuhang Li, Can Xu, Jiaheng Liu, Ao Liu, Changzhi Zhou, Ken Deng, Dengpeng Wu, Guanhua Huang, Kejiao Li, Qi Yi, Ruibin Xiong, Shihui Hu, Yue Zhang, Yuhao Jiang, Zenan Xu, Yuanxing Zhang, Wiggin Zhou, Chayse Zhou, Fengzong Lian
分类: cs.CL, cs.SE
发布日期: 2025-07-07 (更新: 2025-09-29)
💡 一句话要点
ArtifactsBench:弥合LLM代码生成评估中视觉交互的鸿沟
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代码生成 视觉交互 多模态评估 自动化评估 用户体验
📋 核心要点
- 现有LLM代码生成评估侧重算法正确性,忽略视觉保真度和交互完整性,无法有效评估用户体验。
- ArtifactsBench通过程序化渲染和时间截图捕获动态行为,利用多模态LLM进行全面评估。
- 实验表明,ArtifactsBench与人类偏好高度一致,可大规模自动化评估,并揭示通用模型优于特定领域模型。
📝 摘要(中文)
大型语言模型(LLM)的生成能力正迅速从静态代码扩展到动态、交互式的视觉制品。然而,一个关键的评估缺口阻碍了这一进展:现有的基准侧重于算法的正确性,而忽略了定义现代用户体验的视觉保真度和交互完整性。为了弥合这一差距,我们引入了ArtifactsBench,这是一个用于自动、多模态评估视觉代码生成的新基准和范例。我们的框架以编程方式渲染每个生成的制品,并通过时间截图捕获其动态行为。然后,将这些视觉证据与源代码一起,由多模态LLM(MLLM)作为评判者进行评估,该评判者受到细粒度的、针对每个任务的检查表的严格指导,以确保全面和可重复的评分。我们构建了一个包含1825个多样化任务的新基准,并评估了30多个领先的LLM。我们的自动评估与WebDev Arena(Web开发中人类偏好的黄金标准)实现了惊人的94.4%的排名一致性,并且与人类专家达成了超过90%的成对协议。这使ArtifactsBench成为第一个可靠地自动评估大规模人类感知质量的框架。我们的分析提供了当前SOTA的高分辨率图,揭示了通用模型通常优于特定领域模型。我们开源了ArtifactsBench,包括基准、评估工具和基线结果,以向社区提供可扩展且准确的工具,从而加速以用户为中心的生成模型的发展。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)代码生成评估基准主要关注算法的正确性,而忽略了视觉制品(例如网页)的视觉质量和交互行为。这导致了评估结果与人类用户的实际体验存在偏差,无法准确反映LLM在生成用户界面方面的能力。现有方法难以评估动态和交互式的视觉元素,缺乏对用户感知质量的有效度量。
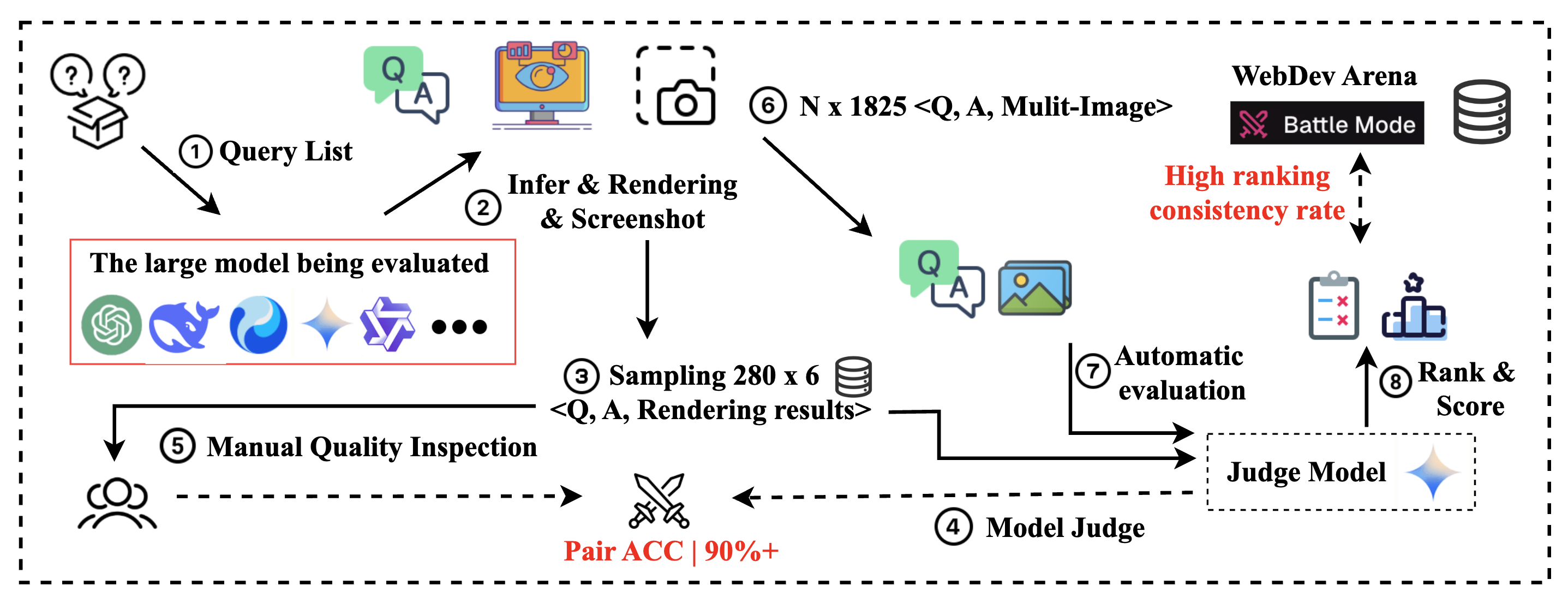
核心思路:ArtifactsBench的核心思路是通过引入多模态评估,将视觉信息纳入LLM代码生成的评估流程中。它通过程序化渲染生成的代码,并捕获其动态行为的截图序列,从而创建视觉证据。然后,利用多模态LLM(MLLM)作为评判者,结合细粒度的任务检查表,对代码和视觉证据进行综合评估,从而更全面地衡量LLM生成视觉制品的能力。
技术框架:ArtifactsBench的整体框架包含以下几个主要模块:1) 任务定义模块:定义了一系列多样化的视觉代码生成任务。2) 代码生成模块:利用不同的LLM生成代码。3) 渲染模块:程序化渲染生成的代码,生成视觉制品。4) 动态行为捕获模块:通过时间截图捕获视觉制品的动态行为。5) 多模态评估模块:使用MLLM作为评判者,结合任务检查表,对代码和视觉证据进行评估。
关键创新:ArtifactsBench的关键创新在于其多模态评估方法,它将视觉信息纳入LLM代码生成的评估流程中。与传统的只关注算法正确性的评估方法相比,ArtifactsBench能够更全面地衡量LLM生成视觉制品的能力,更准确地反映人类用户的实际体验。此外,使用MLLM作为评判者,并结合细粒度的任务检查表,实现了自动化的、可重复的评估流程。
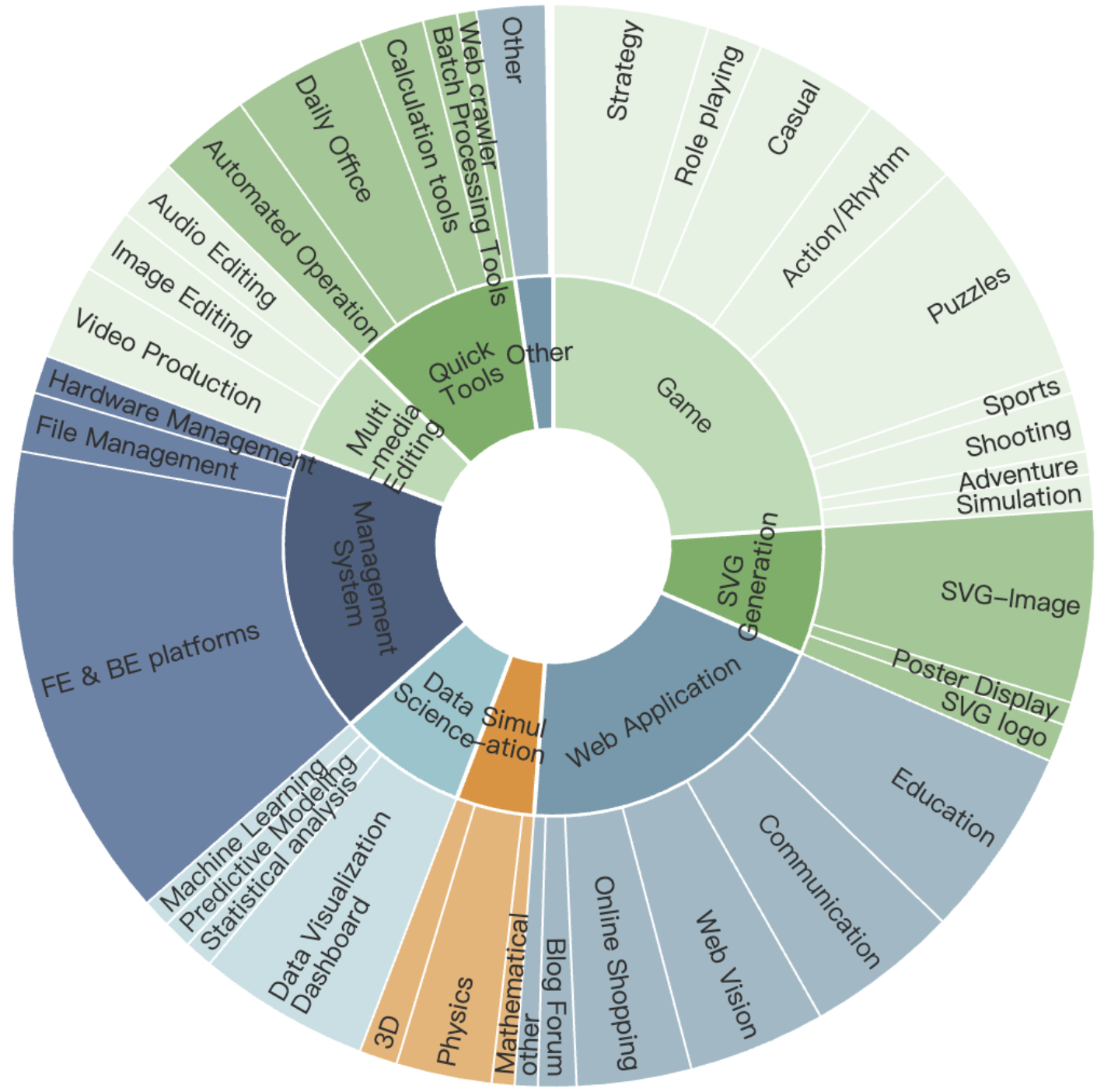
关键设计:ArtifactsBench的关键设计包括:1) 任务的多样性:基准包含各种类型的视觉代码生成任务,以覆盖不同的应用场景。2) 视觉证据的捕获:通过时间截图捕获视觉制品的动态行为,从而更全面地反映其交互性。3) MLLM评判者的选择:选择具有强大视觉理解能力的MLLM作为评判者。4) 任务检查表的细粒度:任务检查表包含详细的评估指标,以确保评估的全面性和准确性。
🖼️ 关键图片

📊 实验亮点
ArtifactsBench的自动评估与WebDev Arena(人类偏好黄金标准)实现了94.4%的排名一致性,与人类专家达成了超过90%的成对协议。这表明ArtifactsBench能够可靠地自动评估人类感知质量。此外,实验结果表明,通用模型在视觉代码生成任务中通常优于特定领域模型。
🎯 应用场景
ArtifactsBench可应用于评估和改进各种视觉代码生成模型,例如网页生成、UI设计、游戏开发等。它能够帮助开发者更好地了解模型的优缺点,并针对性地进行改进,从而提高生成视觉制品的质量和用户体验。此外,该基准还可以用于比较不同模型之间的性能,推动视觉代码生成领域的发展。
📄 摘要(原文)
The generative capabilities of Large Language Models (LLMs) are rapidly expanding from static code to dynamic, interactive visual artifacts. This progress is bottlenecked by a critical evaluation gap: established benchmarks focus on algorithmic correctness and are blind to the visual fidelity and interactive integrity that define modern user experiences. To bridge this gap, we introduce ArtifactsBench, a new benchmark and paradigm for the automated, multimodal evaluation of visual code generation. Our framework programmatically renders each generated artifact and captures its dynamic behavior through temporal screenshots. This visual evidence, alongside the source code, is then assessed by a Multimodal LLM (MLLM)-as-Judge, which is rigorously guided by a fine-grained, per-task checklist to ensure holistic and reproducible scoring. We construct a new benchmark of 1,825 diverse tasks and evaluate over 30 leading LLMs. Our automated evaluation achieves a striking 94.4% ranking consistency with WebDev Arena, the gold-standard for human preference in web development, and over 90% pairwise agreement with human experts. This establishes ArtifactsBench as the first framework to reliably automate the assessment of human-perceived quality at scale. Our analysis provides a high-resolution map of the current SOTA, revealing that generalist models often outperform domain-specific ones. We open-source ArtifactsBench, including the benchmark, evaluation harness, and baseline results at https://artifactsbenchmark.github.io/, to provide the community with a scalable and accurate tool to accelerate the development of user-centric generative models.