Emergent Semantics Beyond Token Embeddings: Transformer LMs with Frozen Visual Unicode Representations
作者: A. Bochkov
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2025-10-15)
备注: Published in Transactions on Machine Learning Research (10/2025). OpenReview: https://openreview.net/forum?id=Odh8IynO1o
期刊: Transactions on Machine Learning Research (TMLR), 2025
💡 一句话要点
提出基于冻结视觉Unicode表征的Transformer LM,突破传统token嵌入语义限制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Transformer 嵌入层 Unicode 视觉表征
📋 核心要点
- 现有LLM依赖可训练的输入嵌入来表示语义,但可能导致表征干扰,限制模型性能。
- 论文提出一种新方法,使用冻结的、基于Unicode字形视觉结构的嵌入,无需语义初始化。
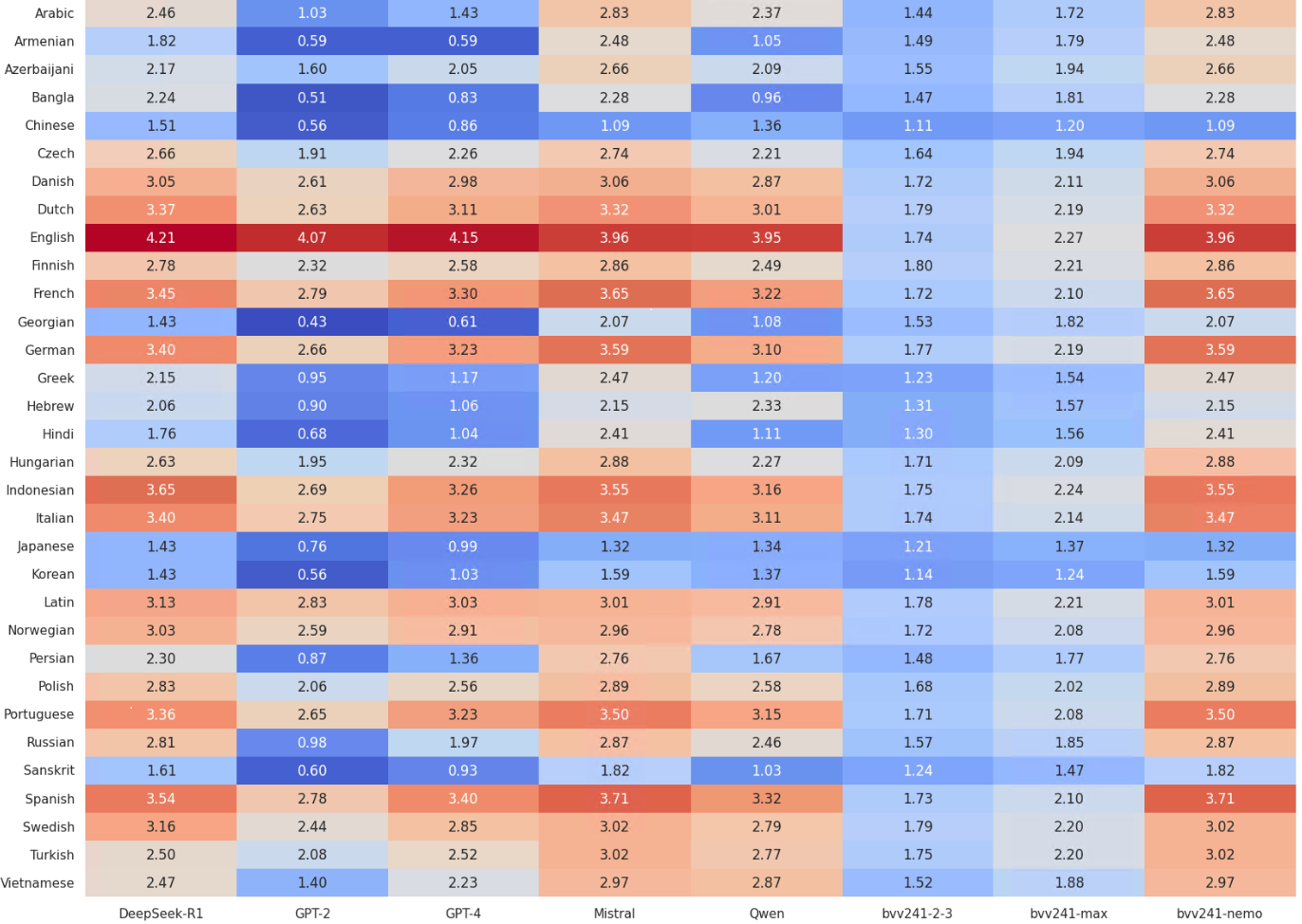
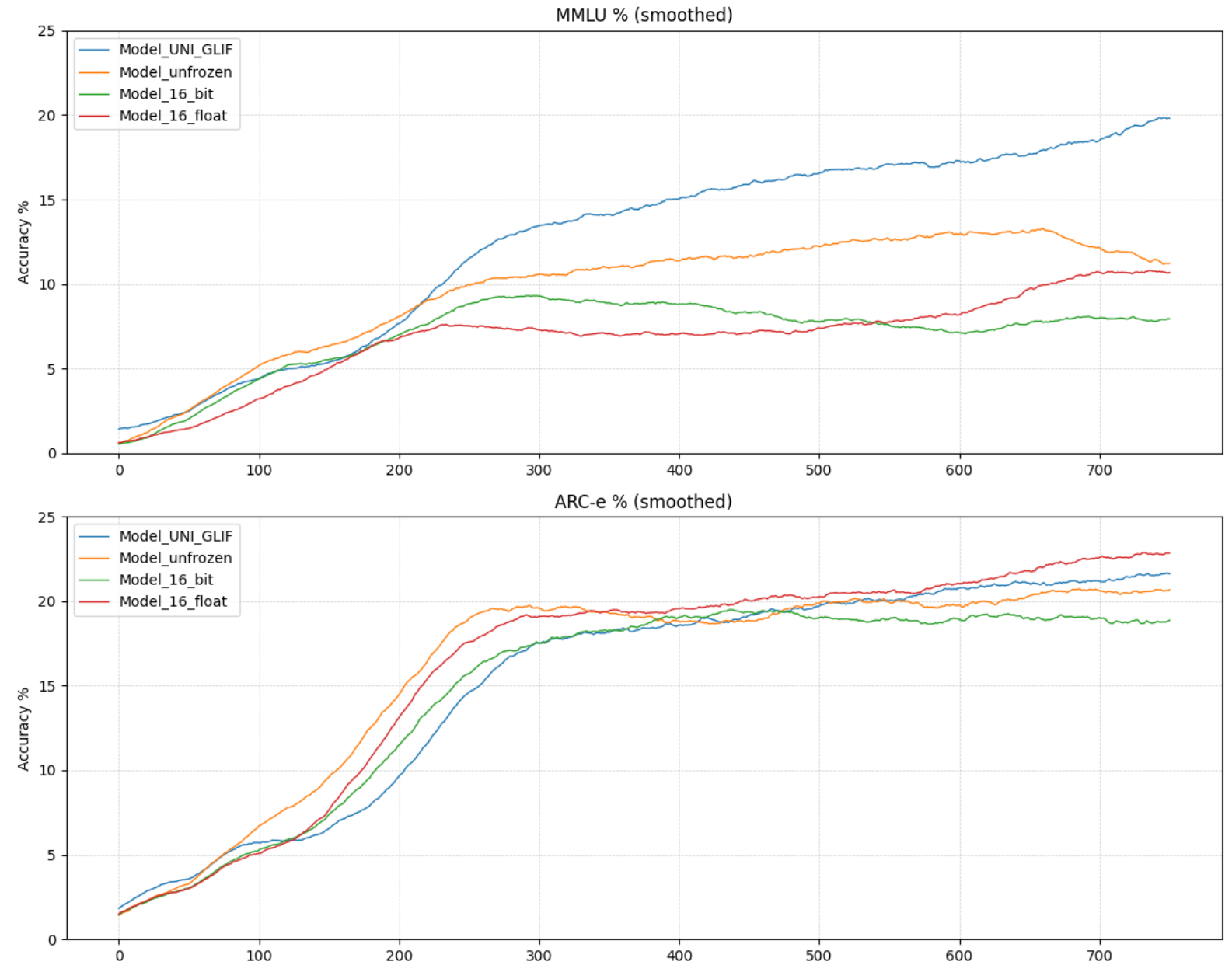
- 实验表明,该方法在MMLU基准测试中优于传统可训练嵌入模型,表明语义是涌现的。
📝 摘要(中文)
本文挑战了大型语言模型(LLM)中可训练输入嵌入作为基础“语义向量”的主流观点。作者构建了Transformer模型,其中嵌入层完全冻结,向量并非来自数据,而是来自Unicode字形的视觉结构。这些非语义的、预计算的视觉嵌入在整个训练过程中保持固定。该方法兼容任何分词器,包括作者引入的以Unicode为中心的新型分词器,以确保通用文本覆盖。尽管缺乏可训练的、语义初始化的嵌入,但模型仍然收敛,生成连贯的文本,并且在MMLU推理基准测试中优于具有可训练嵌入的架构相同的模型。这归因于传统模型中的“表征干扰”,其中嵌入层承担了学习结构和语义特征的双重负担。结果表明,高层语义并非输入嵌入固有的,而是Transformer的组合架构和数据规模涌现的属性。这重新定义了嵌入的角色,从语义容器转变为结构基元。作者发布了所有代码和模型,以促进进一步研究。
🔬 方法详解
问题定义:现有大型语言模型通常依赖于可训练的 token 嵌入层来学习语义信息。这种方法的痛点在于,嵌入层需要同时学习 token 的结构信息和语义信息,这可能导致表征干扰,降低模型的性能和可解释性。
核心思路:本文的核心思路是解耦结构信息和语义信息的学习。通过使用冻结的、基于 Unicode 字形视觉结构的嵌入,模型可以专注于学习 token 之间的关系和上下文信息,而无需在嵌入层中学习语义信息。这样可以减少表征干扰,提高模型的性能。
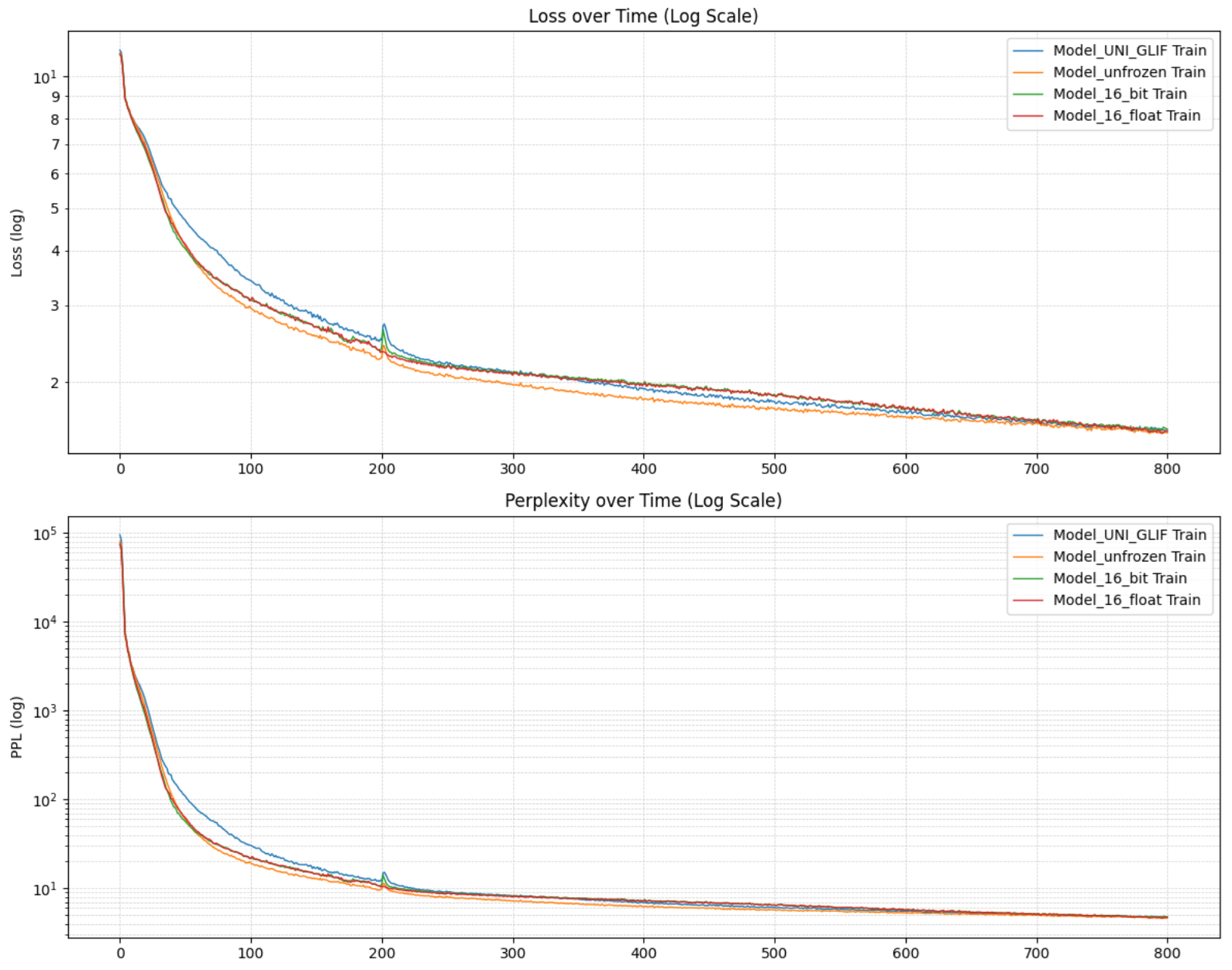
技术框架:整体框架包括一个 Transformer 模型,其嵌入层被替换为基于 Unicode 字形视觉结构的冻结嵌入。首先,使用 Unicode 字形的图像,通过某种图像编码方式(具体编码方式未知)得到每个 Unicode 字符的向量表示。然后,使用这些向量作为 Transformer 模型的输入嵌入,并在训练过程中保持这些嵌入不变。模型使用标准 Transformer 架构进行训练,目标是生成连贯的文本。
关键创新:最重要的创新点在于使用冻结的、非语义的视觉嵌入来代替传统的、可训练的语义嵌入。这挑战了 LLM 中嵌入层是语义信息主要载体的传统观点,并表明高层语义可以从 Transformer 的组合架构和数据规模中涌现出来。
关键设计:论文的关键设计包括:1) 使用 Unicode 字形的视觉结构作为嵌入的来源;2) 冻结嵌入层,使其在训练过程中保持不变;3) 引入一种以 Unicode 为中心的新型分词器,以确保通用文本覆盖。具体参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用冻结的视觉 Unicode 嵌入的 Transformer 模型在 MMLU 推理基准测试中优于具有可训练嵌入的架构相同的模型。这一结果表明,高层语义并非输入嵌入固有的,而是 Transformer 架构和数据规模涌现的属性。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于多种自然语言处理任务,尤其是在资源受限或需要快速原型设计的场景下。通过使用预计算的、非语义的嵌入,可以降低模型训练的计算成本和数据需求。此外,该方法还可以促进对 LLM 内部表征的理解,并为设计更高效、更可解释的模型提供新的思路。
📄 摘要(原文)
Understanding the locus of semantic representation in large language models (LLMs) is crucial for interpretability and architectural innovation. The dominant paradigm posits that trainable input embeddings serve as foundational "meaning vectors." This paper challenges that view. We construct Transformer models where the embedding layer is entirely frozen, with vectors derived not from data, but from the visual structure of Unicode glyphs. These non-semantic, precomputed visual embeddings are fixed throughout training. Our method is compatible with any tokenizer, including a novel Unicode-centric tokenizer we introduce to ensure universal text coverage. Despite the absence of trainable, semantically initialized embeddings, our models converge, generate coherent text, and, critically, outperform architecturally identical models with trainable embeddings on the MMLU reasoning benchmark. We attribute this to "representational interference" in conventional models, where the embedding layer is burdened with learning both structural and semantic features. Our results indicate that high-level semantics are not inherent to input embeddings but are an emergent property of the Transformer's compositional architecture and data scale. This reframes the role of embeddings from meaning containers to structural primitives. We release all code and models to foster further research.