PRIME: Large Language Model Personalization with Cognitive Dual-Memory and Personalized Thought Process
作者: Xinliang Frederick Zhang, Nick Beauchamp, Lu Wang
分类: cs.CL, cs.AI
发布日期: 2025-07-07 (更新: 2025-09-26)
备注: EMNLP'25 Main
💡 一句话要点
PRIME:利用认知双记忆和个性化思维过程实现大语言模型个性化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型个性化 认知双记忆模型 情景记忆 语义记忆 个性化思考 长上下文学习 用户偏好建模
📋 核心要点
- 现有大语言模型个性化方法缺乏统一理论框架,难以系统理解有效个性化的驱动因素。
- PRIME框架将认知双记忆模型引入LLM个性化,模拟情景记忆和语义记忆,实现用户偏好建模。
- 实验表明PRIME在长短文本场景均有效,能捕捉动态个性化,超越了简单的流行度偏见。
📝 摘要(中文)
大语言模型(LLM)个性化旨在使模型输出与个人独特的偏好和观点相一致。尽管最近的研究已经实现了各种个性化方法,但仍然缺乏一个统一的理论框架来系统地理解有效个性化的驱动因素。本文将成熟的认知双记忆模型整合到LLM个性化中,将情景记忆映射到历史用户交互,将语义记忆映射到长期演变的用户信念。具体而言,本文系统地研究了记忆实例化,并提出了一个使用情景记忆和语义记忆机制的统一框架PRIME。此外,本文还受到慢思考策略的启发,利用一种新颖的个性化思考能力来增强PRIME。此外,考虑到缺乏合适的基准,本文使用Reddit的Change My View(CMV)引入了一个数据集,专门用于评估长上下文个性化。大量的实验验证了PRIME在长上下文和短上下文场景中的有效性。进一步的分析证实,PRIME有效地捕捉了动态个性化,超越了单纯的流行度偏差。
🔬 方法详解
问题定义:论文旨在解决大语言模型个性化的问题,即如何使模型的输出与用户的个人偏好和观点对齐。现有方法缺乏一个统一的理论框架来系统地理解有效个性化的驱动因素,并且难以捕捉用户长期演变的信念和偏好。
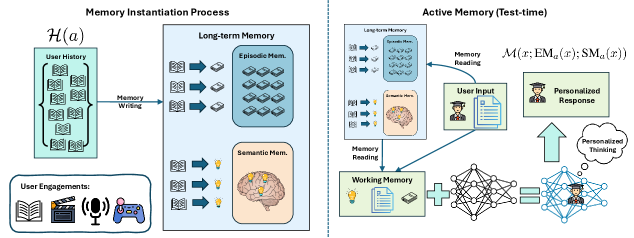
核心思路:论文的核心思路是将认知双记忆模型引入LLM个性化。通过模拟人类的认知过程,将情景记忆(episodic memory)映射到用户的历史交互记录,将语义记忆(semantic memory)映射到用户的长期信念和偏好。这种双记忆机制能够更好地捕捉用户的动态偏好,并生成更个性化的输出。
技术框架:PRIME框架包含以下主要模块:1) 情景记忆模块:存储用户的历史交互记录,例如用户的评论、点赞等。2) 语义记忆模块:存储用户的长期信念和偏好,例如用户对特定话题的观点、对特定产品的喜好等。3) 个性化思考模块:利用情景记忆和语义记忆,模拟人类的慢思考过程,生成更个性化的回复。该模块可能包含一个推理引擎,用于根据用户的历史和信念,推断用户的潜在需求和偏好。4) LLM生成模块:根据个性化思考模块的输出,利用大语言模型生成最终的回复。
关键创新:论文的关键创新在于将认知双记忆模型引入LLM个性化,并提出了一个统一的框架PRIME。与现有方法相比,PRIME能够更好地捕捉用户的动态偏好,并生成更个性化的输出。此外,论文还提出了一个个性化思考模块,模拟人类的慢思考过程,进一步提升了个性化效果。
关键设计:论文的关键设计包括:1) 如何有效地将用户的历史交互记录和长期信念映射到情景记忆和语义记忆中。这可能涉及到使用特定的嵌入方法或知识图谱技术。2) 如何设计个性化思考模块,使其能够有效地利用情景记忆和语义记忆,推断用户的潜在需求和偏好。这可能涉及到使用特定的推理算法或神经网络结构。3) 如何将个性化思考模块的输出融入到LLM的生成过程中,以生成更个性化的回复。这可能涉及到使用特定的prompt工程技术或微调方法。具体的参数设置、损失函数、网络结构等技术细节在论文中可能有所描述,但此处无法详细展开。
🖼️ 关键图片
📊 实验亮点
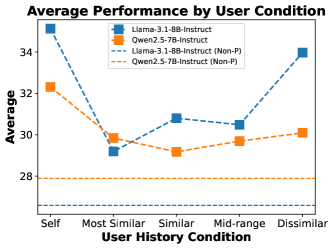
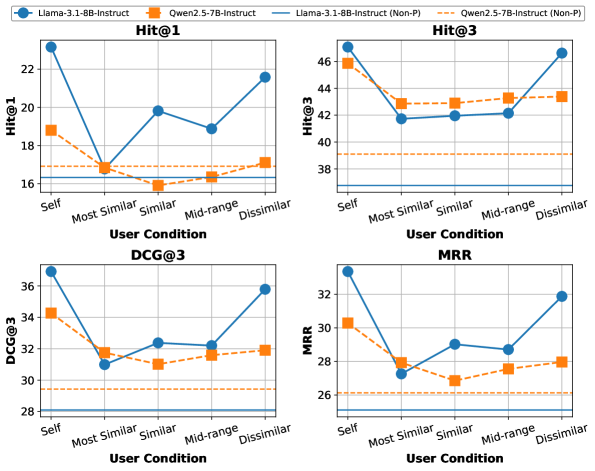
实验结果表明,PRIME框架在长上下文和短上下文场景中均表现出色,能够有效地捕捉用户的动态偏好,并生成更个性化的输出。通过与现有基线方法进行比较,PRIME在个性化指标上取得了显著的提升,证明了其有效性。此外,分析还表明,PRIME能够超越简单的流行度偏见,真正理解用户的个性化需求。
🎯 应用场景
该研究成果可应用于各种需要个性化服务的领域,例如个性化推荐系统、智能客服、社交媒体内容生成等。通过更好地理解用户的偏好和需求,可以提供更精准、更贴心的服务,提升用户体验和满意度。未来,该研究还可以扩展到其他模态的数据,例如语音、图像等,实现更全面的个性化。
📄 摘要(原文)
Large language model (LLM) personalization aims to align model outputs with individuals' unique preferences and opinions. While recent efforts have implemented various personalization methods, a unified theoretical framework that can systematically understand the drivers of effective personalization is still lacking. In this work, we integrate the well-established cognitive dual-memory model into LLM personalization, by mirroring episodic memory to historical user engagements and semantic memory to long-term, evolving user beliefs. Specifically, we systematically investigate memory instantiations and introduce a unified framework, PRIME, using episodic and semantic memory mechanisms. We further augment PRIME with a novel personalized thinking capability inspired by the slow thinking strategy. Moreover, recognizing the absence of suitable benchmarks, we introduce a dataset using Change My View (CMV) from Reddit, specifically designed to evaluate long-context personalization. Extensive experiments validate PRIME's effectiveness across both long- and short-context scenarios. Further analysis confirms that PRIME effectively captures dynamic personalization beyond mere popularity biases.