DP-Fusion: Token-Level Differentially Private Inference for Large Language Models
作者: Rushil Thareja, Preslav Nakov, Praneeth Vepakomma, Nils Lukas
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-06 (更新: 2025-11-09)
备注: Our code and data are publicly available here: https://github.com/MBZUAI-Trustworthy-ML/DP-Fusion-DPI
💡 一句话要点
DP-Fusion:为大语言模型提出Token级别差分隐私推理方法,解决敏感信息泄露问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 大语言模型 隐私保护 推理安全 文档隐私化
📋 核心要点
- 现有大语言模型推理时存在隐私泄露风险,尤其是在使用包含敏感信息的外部工具或数据库时。
- DP-Fusion通过限制上下文中敏感token对LLM输出的影响,实现可证明的差分隐私推理。
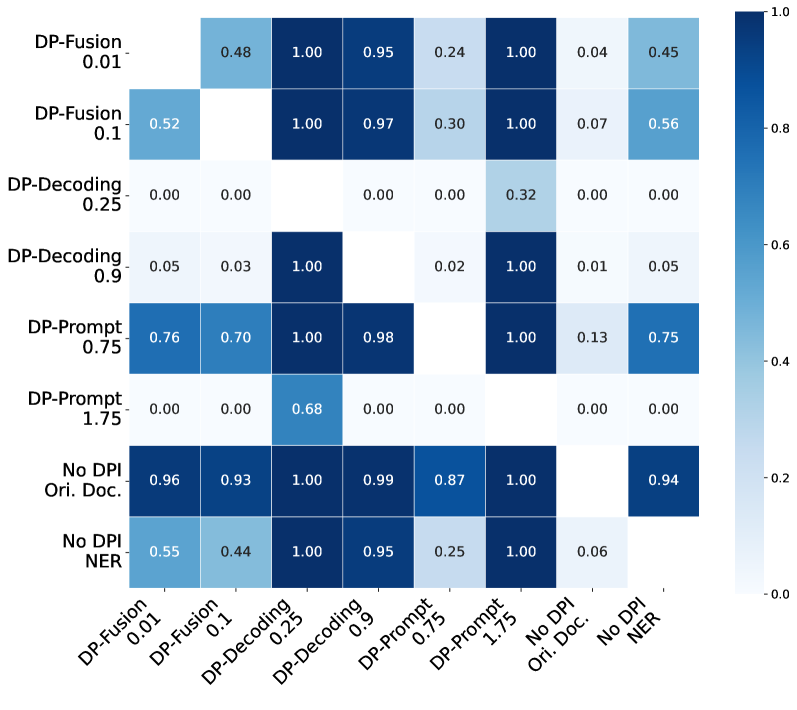
- 实验表明,DP-Fusion在文档隐私化任务中,相比现有DPI方法,能显著降低困惑度,提升隐私保护效果。
📝 摘要(中文)
大型语言模型(LLM)在推理时无法保证隐私。LLM的输出可能会无意中泄露模型上下文的信息,当LLM通过包含敏感信息的工具或数据库进行增强时,这会带来隐私挑战。现有的推理时隐私保护方法存在显著局限性,要么缺乏可证明的保证,要么效用/隐私权衡不佳。我们提出了DP-Fusion,一种用于LLM的差分隐私推理(DPI)机制,可以证明地限制上下文中一组token对LLM输出的影响。DP-Fusion的工作原理如下:(1)标记敏感token的子集,(2)在没有任何敏感token的情况下推断LLM以获得基线,(3)使用敏感token推断LLM,以及(4)混合分布,使最终输出保持在基线分布的有界距离内。虽然这种每个token的影响边界也减轻了越狱式提示注入,但我们专注于文档隐私化,其目标是释义包含敏感token(例如,个人身份信息)的文档,以便攻击者无法从释义后的文档中可靠地推断它们,同时保持较高的文本质量。隐私/效用权衡由ε控制,其中ε=0完全隐藏敏感token,而较高的值则以隐私换取改进的文本质量。我们表明,我们的方法创建了token级别的可证明的私有化文档,具有显著改进的理论和经验隐私性,实现了比相关的DPI方法低6倍的困惑度。
🔬 方法详解
问题定义:论文旨在解决大语言模型在推理过程中,由于模型输出可能泄露训练数据或上下文中的敏感信息,从而导致的隐私泄露问题。现有方法要么缺乏严格的隐私保证,要么在隐私保护的同时,对模型的效用(如文本质量)造成了过大的损失。
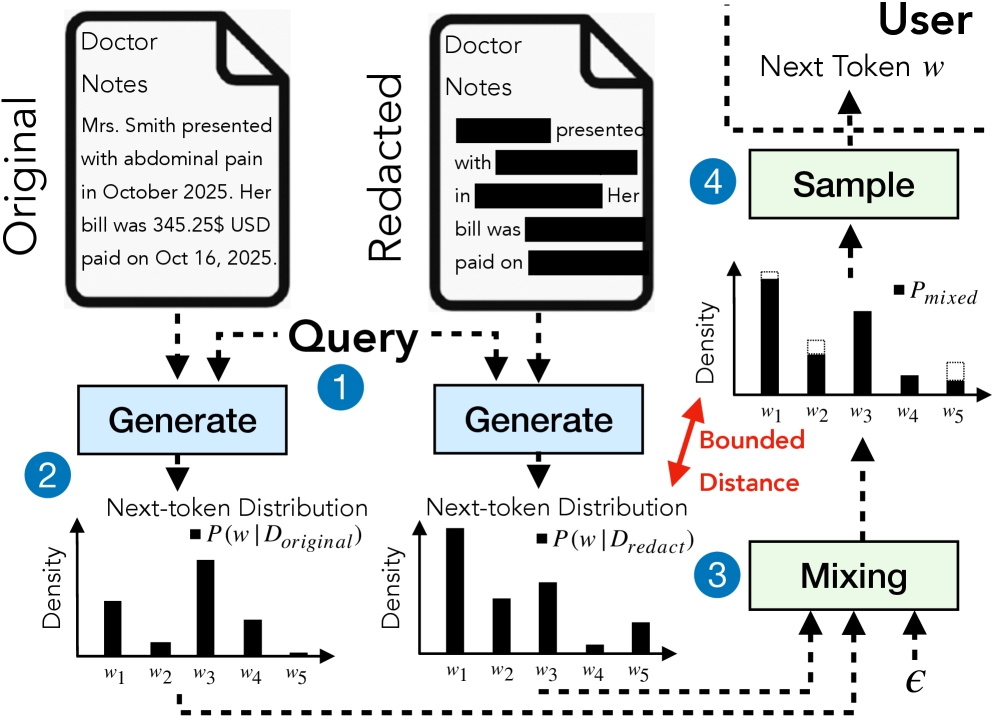
核心思路:DP-Fusion的核心思路是通过差分隐私机制,限制输入token对模型输出的影响。具体来说,它通过比较包含敏感token和不包含敏感token两种情况下的模型输出分布,并对这两种分布进行混合,从而保证最终输出的分布与原始分布的差异在一个可控的范围内,以此来保护敏感信息。
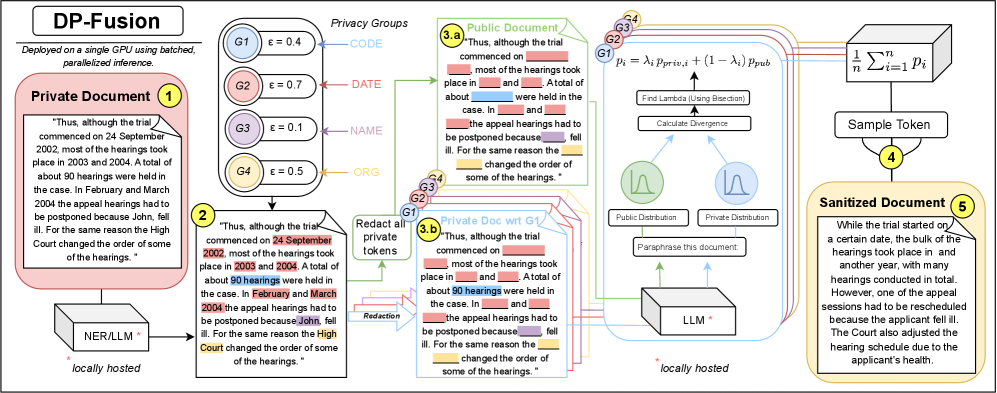
技术框架:DP-Fusion主要包含以下几个步骤:1. 敏感token标记:识别并标记输入文本中的敏感token。2. 基线推断:在不包含任何敏感token的情况下,使用LLM进行推理,得到一个基线输出分布。3. 敏感token推断:使用包含敏感token的完整输入,使用LLM进行推理,得到另一个输出分布。4. 分布融合:将基线输出分布和敏感token推断的输出分布进行融合,融合的比例由差分隐私参数ε控制。最终的输出分布即为隐私保护后的输出。
关键创新:DP-Fusion的关键创新在于它提供了一种token级别的差分隐私保证,能够精确地控制每个token对模型输出的影响。与以往方法相比,DP-Fusion在隐私保护和模型效用之间取得了更好的平衡。此外,该方法还具有一定的防御越狱式提示注入的能力。
关键设计:DP-Fusion的关键参数是差分隐私参数ε,它控制着隐私保护的强度和模型效用的损失。当ε=0时,敏感token被完全隐藏,隐私保护最强,但模型效用损失也最大。当ε增大时,隐私保护强度降低,但模型效用得到提升。分布融合的具体方法未知,论文可能使用了某种平滑技术或者噪声添加机制,以保证差分隐私的实现。
🖼️ 关键图片
📊 实验亮点
DP-Fusion在文档隐私化任务中取得了显著的性能提升。实验结果表明,相比于现有的DPI方法,DP-Fusion能够实现低6倍的困惑度,这意味着在相同的隐私保护水平下,DP-Fusion生成的文本质量更高,更接近原始文本。这表明DP-Fusion在隐私保护和模型效用之间取得了更好的平衡。
🎯 应用场景
DP-Fusion可应用于各种需要保护用户隐私的大语言模型应用场景,例如:医疗文本处理、金融数据分析、法律文件生成等。通过该方法,可以在保证模型可用性的前提下,有效防止敏感信息的泄露,提升用户对大语言模型的信任度,促进大语言模型在敏感领域的应用。
📄 摘要(原文)
Large language models (LLMs) do not preserve privacy at inference-time. The LLM's outputs can inadvertently reveal information about the model's context, which presents a privacy challenge when the LLM is augmented via tools or databases containing sensitive information. Existing privacy-preserving methods at inference-time have significant limitations since they (i) lack provable guarantees or (ii) have a poor utility/privacy trade-off. We propose DP-Fusion, a Differentially Private Inference (DPI) mechanism for LLMs that provably bounds the influence a set of tokens in the context can have on the LLM's output. DP-Fusion works as follows: (1) label a subset of sensitive tokens, (2) infer the LLM without any sensitive tokens to obtain a baseline, (3) infer the LLM with the sensitive tokens, and (4) blend distributions so that the final output remains within a bounded distance of the baseline distribution. While this per-token influence bound also mitigates jailbreak-style prompt injection, we focus on \emph{document privatization}, where the goal is to paraphrase a document containing sensitive tokens, e.g., personally identifiable information, so that no attacker can reliably infer them from the paraphrased document while preserving high text quality. The privacy/utility trade-off is controlled by $ε$, where $ε=0$ hides sensitive tokens entirely, while higher values trade off privacy for improved text quality. We show that our method creates token-level provably privatized documents with substantially improved theoretical and empirical privacy, achieving $6\times$ lower perplexity than related DPI methods.