Adapter-state Sharing CLIP for Parameter-efficient Multimodal Sarcasm Detection
作者: Soumyadeep Jana, Sahil Danayak, Sanasam Ranbir Singh
分类: cs.CL
发布日期: 2025-07-06 (更新: 2025-10-29)
💡 一句话要点
提出AdS-CLIP,通过Adapter状态共享实现参数高效的多模态讽刺检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 讽刺检测 参数高效微调 Adapter CLIP 跨模态融合 状态共享
📋 核心要点
- 现有讽刺检测方法依赖大型模型全量微调,计算成本高,难以在资源受限场景部署。
- AdS-CLIP仅在上层插入Adapter,并提出Adapter状态共享机制,利用文本信息引导视觉学习。
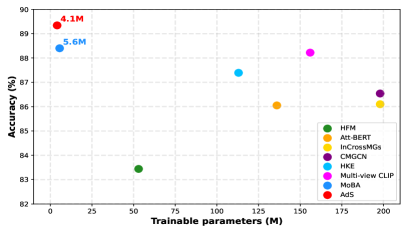
- 实验表明,AdS-CLIP在参数量更少的情况下,性能优于传统PEFT方法和多模态基线。
📝 摘要(中文)
社交媒体上多模态图文讽刺现象日益普遍,给观点挖掘系统带来了挑战。现有方法依赖于大型模型的完全微调,不适合在资源受限的环境下进行适配。虽然最近的参数高效微调(PEFT)方法展现了潜力,但直接应用在讽刺检测等复杂任务上表现不佳。我们提出了AdS-CLIP(CLIP中的Adapter状态共享),这是一个构建在CLIP之上的轻量级框架,仅在上层插入adapter以保留下层中的低级单模态表示,并引入了一种新颖的adapter状态共享机制,其中文本adapter引导视觉adapter,以促进上层中高效的跨模态学习。在两个公共基准上的实验表明,AdS-CLIP不仅优于标准PEFT方法,而且优于现有的多模态基线,且可训练参数明显更少。
🔬 方法详解
问题定义:论文旨在解决多模态讽刺检测任务中,现有方法参数量大、计算成本高,难以在资源受限环境下部署的问题。现有方法通常采用全量微调大型预训练模型,导致计算资源消耗巨大,且容易过拟合。
核心思路:论文的核心思路是利用参数高效微调(PEFT)方法,并在此基础上进行改进,提出Adapter状态共享机制。通过仅微调少量参数,降低计算成本,同时利用文本信息引导视觉信息的学习,提升跨模态融合效果。
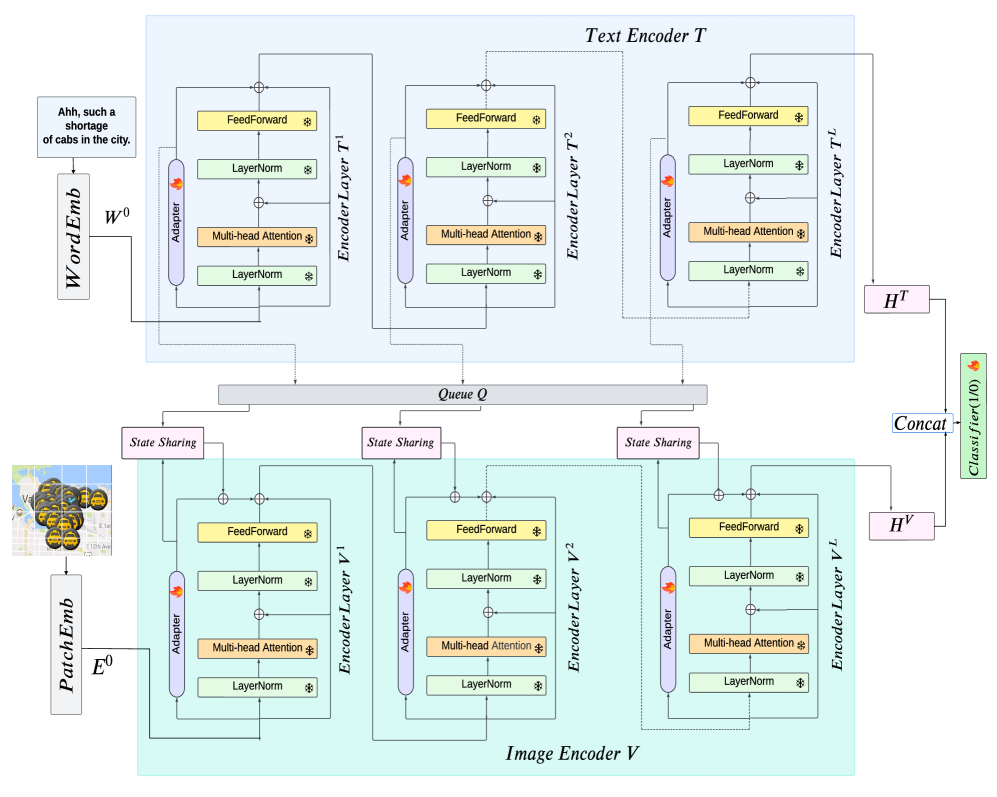
技术框架:AdS-CLIP框架基于CLIP模型构建,主要包含以下模块:1) CLIP的图像编码器和文本编码器;2) 插入到CLIP上层Transformer块中的Adapter模块;3) Adapter状态共享模块,用于文本Adapter引导视觉Adapter。整体流程是:图像和文本分别通过CLIP编码器提取特征,然后通过Adapter模块进行特征调整和融合,最后进行讽刺分类。
关键创新:论文最重要的技术创新点是Adapter状态共享机制。该机制允许文本Adapter的状态信息传递给视觉Adapter,从而利用文本信息指导视觉特征的学习,促进更有效的跨模态融合。这种机制能够提升模型对讽刺语气的理解能力,尤其是在视觉信息较为模糊的情况下。
关键设计:AdS-CLIP的关键设计包括:1) Adapter的插入位置:仅在上层Transformer块中插入Adapter,保留下层单模态特征;2) Adapter状态共享方式:通过某种函数(具体形式未知)将文本Adapter的状态信息传递给视觉Adapter;3) 损失函数:使用交叉熵损失函数进行讽刺分类训练。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
AdS-CLIP在两个公开数据集上进行了实验,结果表明,该方法在显著减少可训练参数的情况下,性能优于标准PEFT方法和现有的多模态基线。具体的性能提升幅度和对比基线在摘要中未明确给出,需要在论文中查找。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过准确识别多模态讽刺信息,可以提升社交平台的内容质量,帮助企业更好地理解用户情感,并为智能客服提供更精准的回复。
📄 摘要(原文)
The growing prevalence of multimodal image-text sarcasm on social media poses challenges for opinion mining systems. Existing approaches rely on full fine-tuning of large models, making them unsuitable to adapt under resource-constrained settings. While recent parameter-efficient fine-tuning (PEFT) methods offer promise, their off-the-shelf use underperforms on complex tasks like sarcasm detection. We propose AdS-CLIP (Adapter-state Sharing in CLIP), a lightweight framework built on CLIP that inserts adapters only in the upper layers to preserve low-level unimodal representations in the lower layers and introduces a novel adapter-state sharing mechanism, where textual adapters guide visual ones to promote efficient cross-modal learning in the upper layers. Experiments on two public benchmarks demonstrate that AdS-CLIP not only outperforms standard PEFT methods but also existing multimodal baselines with significantly fewer trainable parameters.