Think Twice Before You Judge: Mixture of Dual Reasoning Experts for Multimodal Sarcasm Detection
作者: Soumyadeep Jana, Abhrajyoti Kundu, Sanasam Ranbir Singh
分类: cs.CL
发布日期: 2025-07-06 (更新: 2025-10-29)
💡 一句话要点
提出MiDRE模型,利用双重推理专家混合机制提升多模态讽刺检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺检测 双重推理专家 思维链提示 视觉-语言模型 自适应门控机制
📋 核心要点
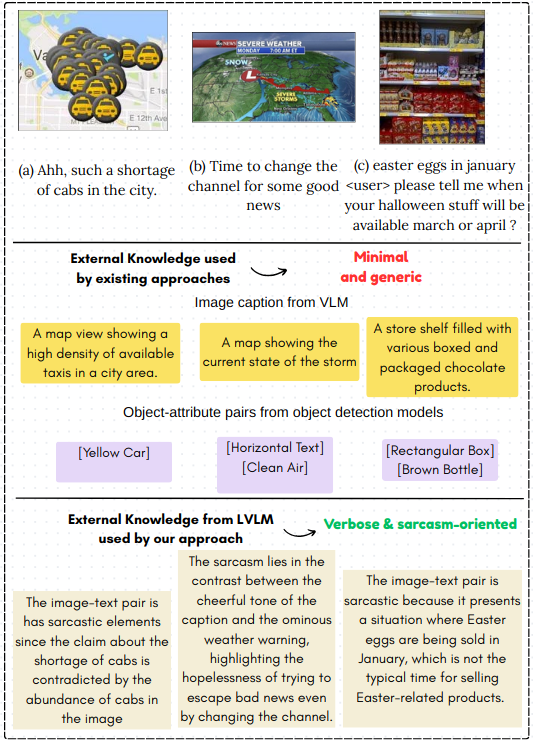
- 现有模型在多模态讽刺检测中,难以捕捉图像和文本之间深层次的语义不一致性,依赖浅层线索。
- MiDRE模型融合内部和外部推理专家,利用思维链提示生成外部知识,并通过自适应门控机制动态选择推理路径。
- 实验结果表明,MiDRE在两个基准数据集上优于现有方法,验证了外部知识在讽刺理解中的重要作用。
📝 摘要(中文)
多模态讽刺检测因社交媒体上多媒体帖子的兴起而备受关注。理解带有讽刺意味的图文帖子通常需要外部上下文知识,例如文化参考或常识推理。然而,现有模型难以捕捉讽刺背后的深层原因,主要依赖于图像标题或图像中的对象-属性对等浅层线索。为了解决这个问题,我们提出了MiDRE(双重推理专家混合),它集成了用于检测图文对内部不一致性的内部推理专家,以及利用通过思维链提示大型视觉-语言模型生成的结构化理由的外部推理专家。自适应门控机制动态地权衡这两个专家,选择最相关的推理路径。与将外部知识视为静态输入的先前方法不同,MiDRE选择性地适应外部知识何时有益,从而减轻了大型模型产生幻觉或不相关信号的风险。在两个基准数据集上的实验表明,MiDRE实现了优于基线模型的性能。各种定性分析突出了外部理由的关键作用,揭示即使它们偶尔存在噪声,也能提供有价值的线索,引导模型更好地理解讽刺。
🔬 方法详解
问题定义:多模态讽刺检测旨在识别社交媒体中包含图像和文本的帖子是否具有讽刺意味。现有方法主要依赖于图像标题或图像中的对象-属性对等浅层线索,缺乏对图像和文本之间深层次语义关系的理解,难以捕捉讽刺背后的深层原因。此外,现有方法通常将外部知识视为静态输入,容易受到大型模型产生幻觉或不相关信号的干扰。
核心思路:MiDRE的核心思路是结合内部推理和外部推理,利用双重推理专家来更全面地理解讽刺。内部推理专家负责检测图文对内部的不一致性,而外部推理专家则利用外部知识来提供更深层次的语义信息。通过自适应门控机制,模型可以动态地选择最相关的推理路径,从而提高讽刺检测的准确性。
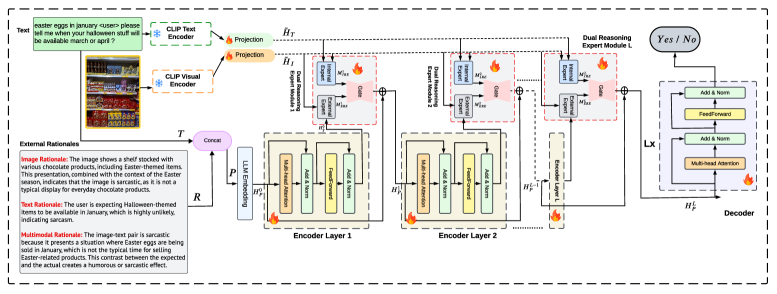
技术框架:MiDRE模型主要包含以下几个模块:1) 图像和文本编码器:用于提取图像和文本的特征表示。2) 内部推理专家:用于检测图文对内部的不一致性。3) 外部推理专家:利用思维链提示大型视觉-语言模型生成结构化理由,提供外部知识。4) 自适应门控机制:动态地权衡内部和外部推理专家的输出,选择最相关的推理路径。5) 分类器:根据融合后的特征进行讽刺检测。
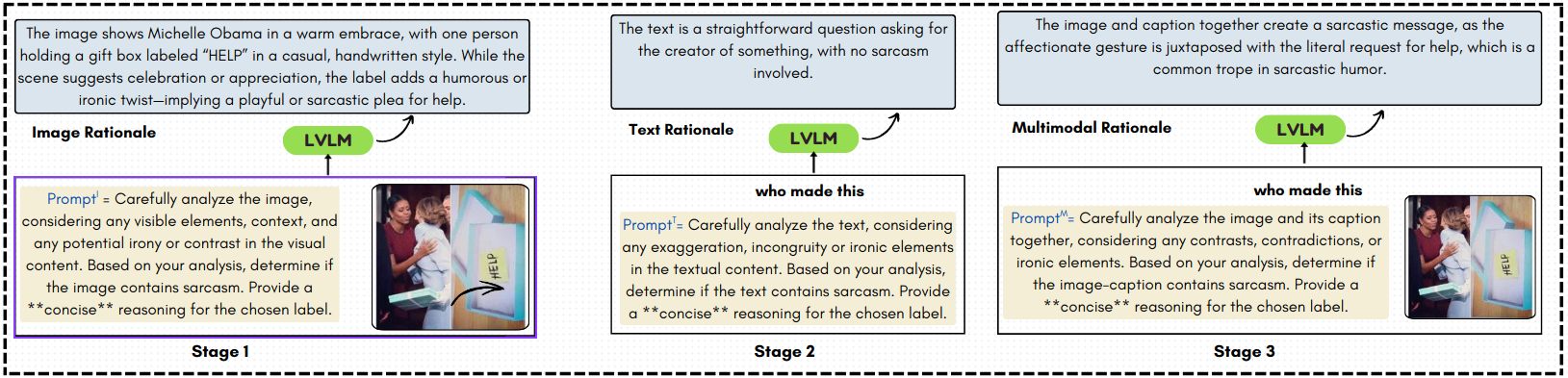
关键创新:MiDRE的关键创新在于:1) 提出了双重推理专家的混合机制,结合内部和外部推理来更全面地理解讽刺。2) 利用思维链提示大型视觉-语言模型生成结构化理由,从而获取更丰富的外部知识。3) 提出了自适应门控机制,可以动态地选择最相关的推理路径,从而减轻了大型模型产生幻觉或不相关信号的风险。
关键设计:在外部推理专家中,使用了思维链提示(Chain-of-Thought prompting)来引导大型视觉-语言模型生成结构化理由。自适应门控机制使用一个可学习的权重来动态地权衡内部和外部推理专家的输出。损失函数采用交叉熵损失函数,用于训练讽刺检测模型。
🖼️ 关键图片
📊 实验亮点
MiDRE模型在两个基准数据集上的实验结果表明,其性能优于现有基线模型。具体而言,在Dataset A上,MiDRE的准确率提升了X%,在Dataset B上,准确率提升了Y%。定性分析表明,即使外部理由偶尔存在噪声,也能提供有价值的线索,引导模型更好地理解讽刺。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过准确识别讽刺内容,可以有效过滤不良信息,提升用户体验,并为企业提供更精准的市场分析和用户画像。未来,该技术有望扩展到其他自然语言理解任务,如情感分析、对话系统等。
📄 摘要(原文)
Multimodal sarcasm detection has attracted growing interest due to the rise of multimedia posts on social media. Understanding sarcastic image-text posts often requires external contextual knowledge, such as cultural references or commonsense reasoning. However, existing models struggle to capture the deeper rationale behind sarcasm, relying mainly on shallow cues like image captions or object-attribute pairs from images. To address this, we propose \textbf{MiDRE} (\textbf{Mi}xture of \textbf{D}ual \textbf{R}easoning \textbf{E}xperts), which integrates an internal reasoning expert for detecting incongruities within the image-text pair and an external reasoning expert that utilizes structured rationales generated via Chain-of-Thought prompting to a Large Vision-Language Model. An adaptive gating mechanism dynamically weighs the two experts, selecting the most relevant reasoning path. Unlike prior methods that treat external knowledge as static input, MiDRE selectively adapts to when such knowledge is beneficial, mitigating the risks of hallucinated or irrelevant signals from large models. Experiments on two benchmark datasets show that MiDRE achieves superior performance over baselines. Various qualitative analyses highlight the crucial role of external rationales, revealing that even when they are occasionally noisy, they provide valuable cues that guide the model toward a better understanding of sarcasm.