MOMENTS: A Comprehensive Multimodal Benchmark for Theory of Mind
作者: Emilio Villa-Cueva, S M Masrur Ahmed, Rendi Chevi, Jan Christian Blaise Cruz, Kareem Elzeky, Fermin Cristobal, Alham Fikri Aji, Skyler Wang, Rada Mihalcea, Thamar Solorio
分类: cs.CL
发布日期: 2025-07-06 (更新: 2025-09-21)
💡 一句话要点
提出MoMentS:一个综合性多模态基准,用于评估心智理论能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心智理论 多模态学习 长视频理解 社交智能 基准数据集
📋 核心要点
- 现有方法在理解复杂社交场景和推断人物心理状态方面存在不足,尤其是在多模态信息融合方面。
- MoMentS基准通过构建包含丰富叙事和长视频上下文的短片,提供更真实的社交互动场景,从而评估模型的心智理论能力。
- 实验结果表明,视觉信息通常能提升模型性能,但模型在有效整合多模态信息方面仍面临挑战,音频处理方式对性能影响不显著。
📝 摘要(中文)
为了构建能够感知和解释人类行为的具有社会智能的多模态智能体,理解心智理论至关重要。本文提出了MoMentS(多模态心理状态),这是一个综合性基准,旨在通过短片中呈现的逼真、叙事丰富的场景来评估多模态大型语言模型(LLM)的心智理论能力。MoMentS包含超过2300个多项选择题,涵盖七个不同的心智理论类别。该基准具有长视频上下文窗口和逼真的社交互动,能够更深入地了解角色的心理状态。我们评估了几个MLLM,发现虽然视觉通常可以提高性能,但模型仍然难以有效地整合它。对于音频,将对话作为音频处理的模型并没有始终优于基于文本的输入。我们的研究结果强调需要改进多模态集成,并指出了必须解决的开放性挑战,以推进AI的社会理解。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在理解心智理论(Theory of Mind, ToM)方面的能力评估问题。现有方法缺乏一个综合性的、具有挑战性的基准,无法充分评估模型在复杂社交场景中理解和推断人物心理状态的能力。尤其是在长视频上下文和多模态信息融合方面,现有基准存在不足。
核心思路:论文的核心思路是构建一个更贴近现实世界的、叙事丰富的多模态基准MoMentS,通过短片形式呈现复杂的社交互动场景,并设计多项选择题来评估模型对人物心理状态的理解。通过长视频上下文和多种模态信息的结合,更全面地考察模型的心智理论能力。
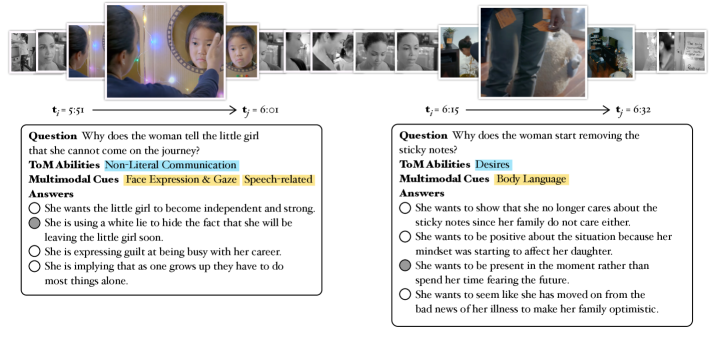
技术框架:MoMentS基准包含以下主要组成部分:1) 短片数据集:包含多个短片,每个短片都设计了复杂的社交互动场景,并围绕特定的人物心理状态展开。2) 多项选择题:针对每个短片,设计了多个多项选择题,涵盖七个不同的心智理论类别,用于评估模型对人物心理状态的理解。3) 评估指标:使用准确率等指标来评估模型在MoMentS基准上的表现。整体流程是,将短片及其对应的问题输入到MLLM中,然后根据模型的回答计算评估指标。
关键创新:MoMentS基准的关键创新在于其综合性和挑战性。它不仅包含了长视频上下文,还涵盖了多种模态信息(视觉、音频、文本),并且设计了复杂的社交互动场景,更贴近现实世界。此外,MoMentS基准还涵盖了七个不同的心智理论类别,可以更全面地评估模型的心智理论能力。
关键设计:MoMentS基准的关键设计包括:1) 短片的设计:短片的设计需要保证场景的真实性和叙事的丰富性,同时要围绕特定的人物心理状态展开。2) 多项选择题的设计:多项选择题的设计需要保证问题的难度和区分度,同时要涵盖不同的心智理论类别。3) 评估指标的选择:评估指标的选择需要能够准确地反映模型的心智理论能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,视觉信息通常能提升模型在MoMentS基准上的性能,但模型在有效整合多模态信息方面仍面临挑战。此外,将对话作为音频处理的模型并没有始终优于基于文本的输入,这表明现有模型在音频理解方面仍有提升空间。这些发现为未来研究提供了重要的方向。
🎯 应用场景
该研究成果可应用于开发更具社会智能的AI智能体,例如社交机器人、虚拟助手等,使其能够更好地理解人类行为、预测人类意图,从而实现更自然、更有效的交互。此外,该基准也可用于评估和提升现有AI模型在社交理解方面的能力,推动AI技术在教育、医疗等领域的应用。
📄 摘要(原文)
Understanding Theory of Mind is essential for building socially intelligent multimodal agents capable of perceiving and interpreting human behavior. We introduce MoMentS (Multimodal Mental States), a comprehensive benchmark designed to assess the ToM capabilities of multimodal large language models (LLMs) through realistic, narrative-rich scenarios presented in short films. MoMentS includes over 2,300 multiple-choice questions spanning seven distinct ToM categories. The benchmark features long video context windows and realistic social interactions that provide deeper insight into characters' mental states. We evaluate several MLLMs and find that although vision generally improves performance, models still struggle to integrate it effectively. For audio, models that process dialogues as audio do not consistently outperform transcript-based inputs. Our findings highlight the need to improve multimodal integration and point to open challenges that must be addressed to advance AI's social understanding.