No Language Data Left Behind: A Comparative Study of CJK Language Datasets in the Hugging Face Ecosystem
作者: Dasol Choi, Woomyoung Park, Youngsook Song
分类: cs.CL
发布日期: 2025-07-06 (更新: 2025-10-15)
备注: Accepted to EMNLP 2025 MRL Workshop
💡 一句话要点
CJK语言数据集对比研究:揭示Hugging Face生态中的数据集特征与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CJK语言 数据集分析 Hugging Face 自然语言处理 大型语言模型
📋 核心要点
- 高质量数据集是构建大型语言模型的关键,但CJK语言的数据集资源相对匮乏,质量参差不齐。
- 该研究通过分析Hugging Face生态中CJK语言数据集的特征,揭示文化、环境和机构因素对数据集的影响。
- 研究发现中文数据集规模大且机构驱动,韩语数据集社区主导,日语数据集则侧重娱乐亚文化。
📝 摘要(中文)
自然语言处理(NLP)的最新进展强调了高质量数据集在构建大型语言模型(LLM)中的关键作用。然而,尽管英语拥有广泛的资源和分析,但东亚语言(特别是中文、日语和韩语(CJK))的资源环境仍然分散且未被充分探索,尽管这些语言的使用者超过16亿。为了解决这一差距,我们从跨语言的角度研究了Hugging Face生态系统,重点关注文化规范、研究环境和机构实践如何影响数据集的可用性和质量。通过分析超过3300个数据集,我们采用定量和定性方法来检验这些因素如何驱动中文、日语和韩语NLP社区中不同的创建和管理模式。我们的研究结果突出了中文数据集的大规模和通常由机构驱动的性质,韩语NLP中由基层社区主导的开发,以及日语集合中对娱乐和亚文化的关注。通过揭示这些模式,我们揭示了增强数据集文档、许可清晰度和跨语言资源共享的实用策略,最终指导在东亚地区开发更有效和文化上协调的LLM。最后,我们讨论了未来数据集管理和协作的最佳实践,旨在加强所有三种语言的资源开发。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在很大程度上依赖于高质量的数据集进行训练。虽然英语数据集资源丰富且研究深入,但对于中文、日语和韩语(CJK)等东亚语言,数据集的可用性、质量和特征仍然缺乏系统的研究和比较分析。这阻碍了针对CJK语言的LLM的有效开发和应用。现有方法未能充分考虑文化规范、研究环境和机构实践等因素对CJK语言数据集的影响,导致数据集的创建和管理模式存在差异,资源共享和跨语言协作面临挑战。
核心思路:本研究的核心思路是从跨语言的视角,深入分析Hugging Face生态系统中CJK语言数据集的特征,揭示文化、研究环境和机构实践等因素对数据集创建和管理模式的影响。通过定量和定性相结合的方法,识别不同语言数据集的优势和不足,为改进数据集质量、促进资源共享和跨语言协作提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 数据收集:从Hugging Face生态系统中收集超过3300个CJK语言数据集。 2. 定量分析:对数据集的规模、类型、许可协议等进行统计分析,揭示不同语言数据集的总体特征。 3. 定性分析:深入分析数据集的文档、来源、标注质量等,评估数据集的质量和适用性。 4. 案例研究:选取代表性的数据集进行案例研究,分析其创建和管理模式,以及文化、环境和机构因素的影响。 5. 模式识别:总结不同语言数据集的共性和差异,识别影响数据集质量和可用性的关键因素。 6. 策略建议:基于分析结果,提出改进数据集质量、促进资源共享和跨语言协作的策略建议。
关键创新:该研究的关键创新在于: 1. 跨语言视角:首次从跨语言的视角系统地比较分析了Hugging Face生态系统中CJK语言数据集的特征。 2. 多因素分析:综合考虑了文化规范、研究环境和机构实践等多种因素对数据集的影响。 3. 定量与定性结合:采用定量和定性相结合的方法,全面评估数据集的质量和适用性。 4. 实用性指导:提出了改进数据集质量、促进资源共享和跨语言协作的实用策略建议。
关键设计:研究的关键设计包括: 1. 数据集选择:选择Hugging Face生态系统作为研究对象,因为它是一个流行的开源平台,拥有大量的CJK语言数据集。 2. 指标选择:选择数据集规模、类型、许可协议、文档质量、标注质量等指标,全面评估数据集的特征和质量。 3. 分析方法:采用统计分析、文本分析、案例研究等多种方法,深入分析数据集的创建和管理模式。 4. 专家访谈:与CJK语言NLP领域的专家进行访谈,了解数据集的实际应用情况和面临的挑战。
🖼️ 关键图片

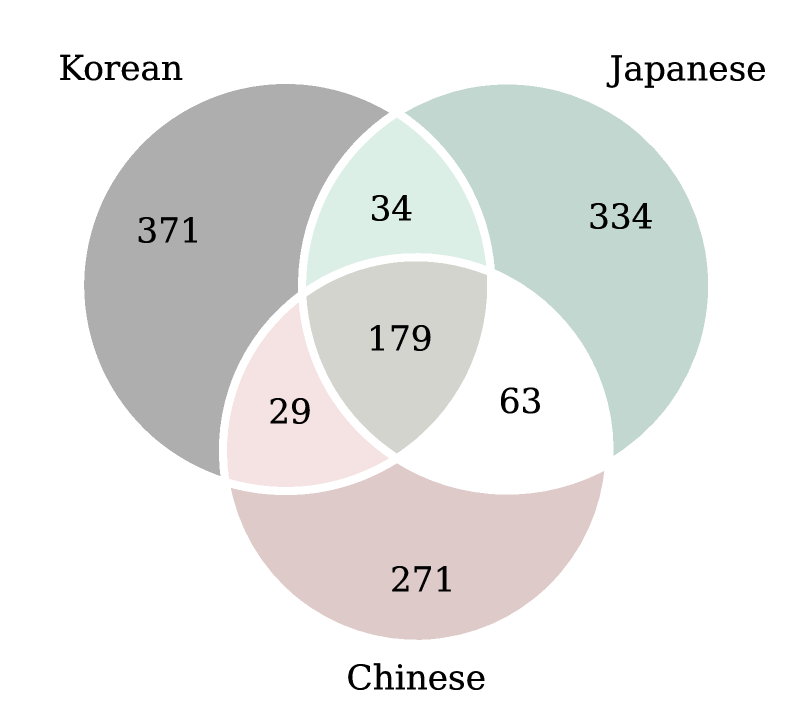
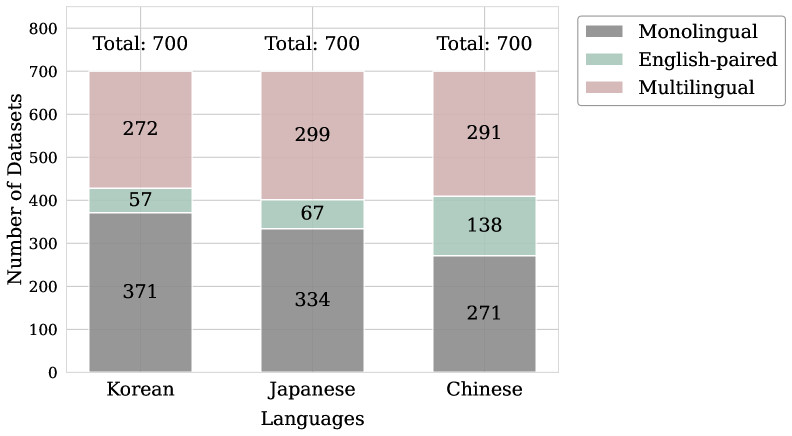
📊 实验亮点
该研究分析了超过3300个CJK语言数据集,揭示了中文数据集规模大且机构驱动,韩语数据集社区主导,日语数据集则侧重娱乐亚文化。研究还提出了增强数据集文档、许可清晰度和跨语言资源共享的实用策略,为CJK语言LLM的开发提供了重要参考。
🎯 应用场景
该研究成果可应用于提升CJK语言大型语言模型的性能,例如中文、日语、韩语的聊天机器人、机器翻译、文本生成等。通过优化数据集的质量、规模和多样性,可以提高模型的泛化能力和鲁棒性。此外,该研究提出的数据集管理和协作策略,有助于促进CJK语言NLP社区的资源共享和知识交流,加速相关技术的发展。
📄 摘要(原文)
Recent advances in Natural Language Processing (NLP) have underscored the crucial role of high-quality datasets in building large language models (LLMs). However, while extensive resources and analyses exist for English, the landscape for East Asian languages - particularly Chinese, Japanese, and Korean (CJK) - remains fragmented and underexplored, despite these languages together serving over 1.6 billion speakers. To address this gap, we investigate the HuggingFace ecosystem from a cross-linguistic perspective, focusing on how cultural norms, research environments, and institutional practices shape dataset availability and quality. Drawing on more than 3,300 datasets, we employ quantitative and qualitative methods to examine how these factors drive distinct creation and curation patterns across Chinese, Japanese, and Korean NLP communities. Our findings highlight the large-scale and often institution-driven nature of Chinese datasets, grassroots community-led development in Korean NLP, and an entertainment- and subculture-focused emphasis on Japanese collections. By uncovering these patterns, we reveal practical strategies for enhancing dataset documentation, licensing clarity, and cross-lingual resource sharing - ultimately guiding more effective and culturally attuned LLM development in East Asia. We conclude by discussing best practices for future dataset curation and collaboration, aiming to strengthen resource development across all three languages.