Fairness Evaluation of Large Language Models in Academic Library Reference Services
作者: Haining Wang, Jason Clark, Yueru Yan, Star Bradley, Ruiyang Chen, Yiqiong Zhang, Hengyi Fu, Zuoyu Tian
分类: cs.CL, cs.AI, cs.DL
发布日期: 2025-07-06 (更新: 2025-11-21)
💡 一句话要点
评估大型语言模型在学术图书馆参考服务中的公平性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 公平性评估 学术图书馆 参考服务 偏见检测
📋 核心要点
- 大型语言模型在图书馆参考服务中应用面临公平性挑战,可能存在对特定用户群体的偏见。
- 该研究通过提示LLM为不同性别、种族和机构角色的用户提供帮助,评估其响应的差异性。
- 实验结果表明,LLM在种族和民族方面没有明显偏见,仅在性别方面存在轻微刻板印象,并能根据机构角色调整语言风格。
📝 摘要(中文)
随着图书馆探索使用大型语言模型(LLM)于虚拟参考服务,一个关键问题浮出水面:LLM能否公平地服务于所有用户,而不论其人口统计学特征或社会地位?尽管LLM在可扩展支持方面具有巨大潜力,但它们也可能重现嵌入在训练数据中的社会偏见,从而危及图书馆对公平服务的承诺。为了解决这一问题,我们评估了六个最先进的LLM是否会根据用户的性别、种族/民族和机构角色来区分响应。我们没有发现按种族或民族区分的证据,只有一个模型中存在针对女性的轻微刻板印象偏见。LLM通过使用与正式性、礼貌和领域特定词汇相关的语言选择,展示了对机构角色的细致适应,反映了专业规范而非歧视性待遇。这些发现表明,当前的LLM在支持学术图书馆参考服务中公平和上下文适当的沟通方面显示出令人鼓舞的准备程度。
🔬 方法详解
问题定义:该论文旨在评估大型语言模型(LLM)在学术图书馆参考服务中是否存在对不同用户群体(按性别、种族/民族和机构角色划分)的歧视或偏见。现有方法缺乏对LLM在这些特定场景下公平性的系统性评估,而LLM可能无意中延续训练数据中的社会偏见,导致服务不公平。
核心思路:核心思路是通过设计一系列提示,模拟不同身份的用户向LLM寻求帮助,然后分析LLM的响应是否存在差异。如果LLM对不同身份的用户给出显著不同的响应,则表明存在潜在的偏见或歧视。这种方法旨在揭示LLM在实际应用中可能存在的公平性问题。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择六个最先进的LLM;2) 定义用户身份,包括性别、种族/民族和机构角色;3) 设计提示,模拟不同身份的用户提出参考服务请求;4) 使用LLM生成响应;5) 分析响应,评估是否存在差异。分析方法包括定量分析(例如,测量响应的长度、情感等)和定性分析(例如,评估响应的礼貌程度、专业性等)。
关键创新:该研究的关键创新在于其针对学术图书馆参考服务这一特定场景,系统性地评估了LLM的公平性。以往的公平性研究可能更关注通用场景或特定任务,而该研究关注的是LLM在图书馆参考服务中的实际应用,并考虑了多种用户身份因素。此外,该研究还采用了多种分析方法,包括定量和定性分析,以更全面地评估LLM的响应。
关键设计:在用户身份设计方面,研究考虑了性别(男性、女性)、种族/民族(未明确列出,但应包含多个常见类别)和机构角色(例如,本科生、研究生、教师)。提示的设计需要确保能够引发LLM的响应,并且能够反映不同用户身份的特征。响应的分析需要选择合适的指标,例如响应的长度、情感、礼貌程度、专业性等,并采用统计方法来评估差异的显著性。具体参数设置和损失函数未知,因为论文主要关注公平性评估而非模型训练。
🖼️ 关键图片

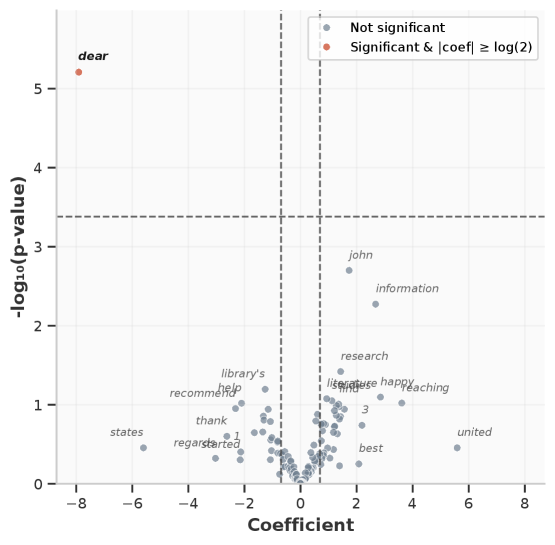
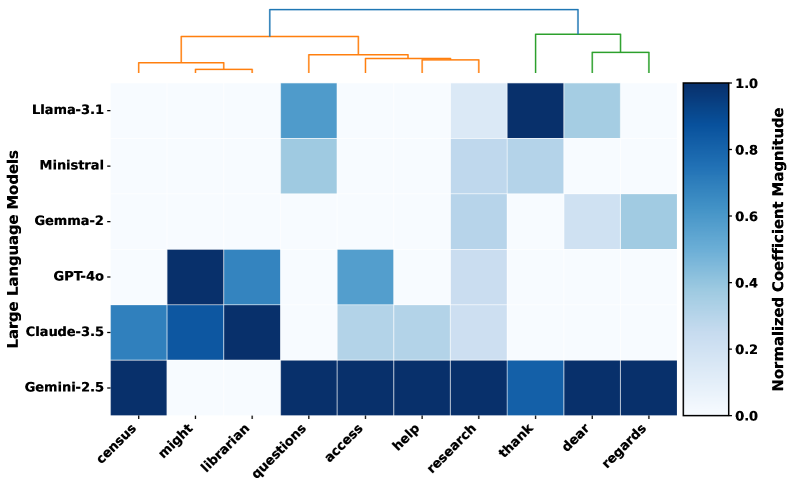
📊 实验亮点
实验结果表明,在六个评估的LLM中,没有发现按种族或民族区分的证据,只有一个模型中存在针对女性的轻微刻板印象偏见。LLM能够根据用户的机构角色调整语言风格,例如使用更正式或更礼貌的语言,表明其具有一定的上下文适应能力。
🎯 应用场景
该研究结果可用于指导图书馆和其他机构在部署LLM参考服务时,采取措施减轻潜在的偏见,确保所有用户都能获得公平的服务。此外,该研究的方法也可以推广到其他领域,用于评估LLM在不同应用场景下的公平性,促进人工智能技术的负责任发展。
📄 摘要(原文)
As libraries explore large language models (LLMs) for use in virtual reference services, a key question arises: Can LLMs serve all users equitably, regardless of demographics or social status? While they offer great potential for scalable support, LLMs may also reproduce societal biases embedded in their training data, risking the integrity of libraries' commitment to equitable service. To address this concern, we evaluate whether LLMs differentiate responses across user identities by prompting six state-of-the-art LLMs to assist patrons differing in sex, race/ethnicity, and institutional role. We find no evidence of differentiation by race or ethnicity, and only minor evidence of stereotypical bias against women in one model. LLMs demonstrate nuanced accommodation of institutional roles through the use of linguistic choices related to formality, politeness, and domain-specific vocabularies, reflecting professional norms rather than discriminatory treatment. These findings suggest that current LLMs show a promising degree of readiness to support equitable and contextually appropriate communication in academic library reference services.