Do LLMs Overthink Basic Math Reasoning? Benchmarking the Accuracy-Efficiency Tradeoff in Language Models
作者: Gaurav Srivastava, Aafiya Hussain, Sriram Srinivasan, Xuan Wang
分类: cs.CL
发布日期: 2025-07-05 (更新: 2025-10-08)
💡 一句话要点
提出Overthinking Score,评估LLM在基础数学推理中的准确率-效率权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 准确率-效率权衡 过度思考 基准测试
📋 核心要点
- 现有LLM在复杂数学问题上表现优异,但在基础数学推理上却常失败,且生成冗余文本,暴露了其推理效率问题。
- 论文提出Overthinking Score,结合准确率和token效率,量化LLM在基础数学推理中的“过度思考”现象。
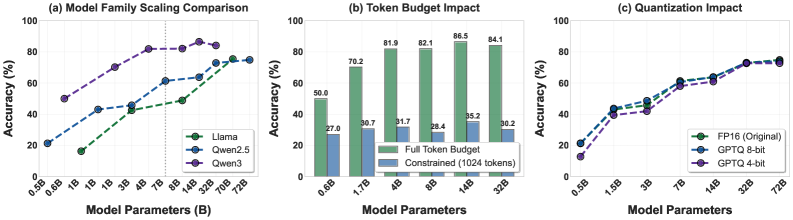
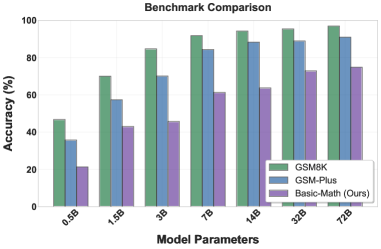
- 实验评估了53个LLM,发现复杂基准上的优异性能不能直接转化为基础数学推理能力,且过度推理可能降低准确率。
📝 摘要(中文)
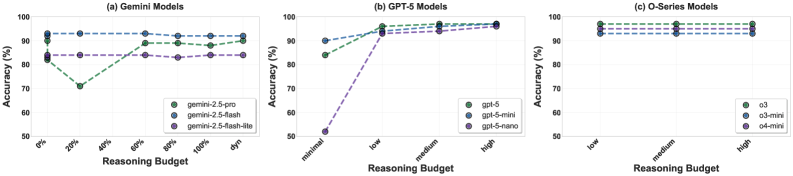
大型语言模型(LLM)在复杂的数学基准测试中表现出色,但有时在基础数学推理中失败,同时生成不必要的冗长响应。本文提出了一个系统的基准和全面的实证研究,以评估LLM推理的效率,重点关注准确率和过度思考之间的基本权衡。首先,形式化了准确率-冗长度权衡。其次,引入了Overthinking Score,这是一个结合准确率和token效率的调和平均指标,用于整体模型评估。第三,建立了一个评估协议,使用跨14个基本数学任务动态生成的数据。第四,进行了一项大规模的实证研究,评估了53个LLM,包括不同推理预算下的推理和量化变体。研究结果表明:1)模型在复杂基准上的性能不能直接转化为基本数学推理;2)推理模型生成约18个以上的token,同时有时会降低准确率,并且在token受限时表现出灾难性的崩溃,下降约28%;3)准确率-冗长度关系是非单调的,扩展的推理预算会产生递减的回报(GPT-5/o-series模型在低->中->高推理努力中显示出零准确率增益)。研究结果挑战了LLM中更长的推理必然会提高数学推理的假设。
🔬 方法详解
问题定义:论文旨在解决LLM在基础数学推理中存在的“过度思考”问题,即模型为了解决简单的数学问题,生成了过多的token,但准确率却没有相应提升,甚至有所下降。现有方法缺乏对LLM推理效率的有效评估,无法衡量准确率和计算成本之间的权衡。
核心思路:论文的核心思路是形式化准确率-冗长度权衡,并提出Overthinking Score来量化这种权衡。通过动态生成不同难度的基础数学问题,并限制LLM的推理预算,来观察模型在不同推理深度下的表现,从而评估其推理效率。
技术框架:论文建立了一个包含数据生成、模型评估和结果分析的完整框架。数据生成模块负责动态生成14种基础数学任务的数据。模型评估模块使用Overthinking Score来评估LLM的性能。结果分析模块则对实验结果进行深入分析,揭示LLM在基础数学推理中的一些问题。
关键创新:论文的关键创新在于提出了Overthinking Score,这是一个结合准确率和token效率的调和平均指标。该指标能够有效地衡量LLM在基础数学推理中的“过度思考”现象,为评估LLM的推理效率提供了一种新的方法。
关键设计:Overthinking Score的计算公式为:2 / (1/Accuracy + 1/Token Efficiency)。其中,Accuracy是模型在给定任务上的准确率,Token Efficiency是模型生成正确答案所需的token数量的倒数。论文还设计了一套动态数据生成方法,可以根据任务难度和模型能力,自动调整生成数据的数量和复杂度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,模型在复杂基准上的性能不能直接转化为基础数学推理能力。推理模型生成约18个以上的token,但有时会降低准确率,且在token受限时,准确率会下降约28%。GPT-5/o-series模型在低->中->高推理努力中显示出零准确率增益,表明过度推理可能适得其反。
🎯 应用场景
该研究成果可应用于LLM的优化和改进,帮助开发者设计更高效、更准确的数学推理模型。此外,该研究提出的评估方法和指标,也可用于评估其他类型的推理任务,促进LLM在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) achieve impressive performance on complex mathematical benchmarks yet sometimes fail on basic math reasoning while generating unnecessarily verbose responses. In this paper, we present a systematic benchmark and comprehensive empirical study to evaluate the efficiency of reasoning in LLMs, focusing on the fundamental tradeoff between accuracy and overthinking. First, we formalize the accuracy-verbosity tradeoff. Second, we introduce the Overthinking Score, a harmonic-mean metric combining accuracy and token-efficiency for holistic model evaluation. Third, we establish an evaluation protocol with dynamically-generated data across 14 basic math tasks. Fourth, we conduct a large-scale empirical study evaluating 53 LLMs, including reasoning and quantized variants across different reasoning budgets. Our findings reveal: 1) model performance on complex benchmarks does not translate directly to basic math reasoning; 2) reasoning models generate ~18 more tokens while sometimes achieving lower accuracy and exhibit catastrophic collapse when token is constrained, dropping by ~28; 3) the accuracy-verbosity relationship is non-monotonic with extended reasoning budgets yielding diminishing returns (GPT-5/o-series models show zero accuracy gain from low -> medium -> high reasoning effort). Our findings challenge the assumption that longer reasoning in LLMs necessarily improves mathematical reasoning.