STRUCTSENSE: A Task-Agnostic Agentic Framework for Structured Information Extraction with Human-In-The-Loop Evaluation and Benchmarking
作者: Tek Raj Chhetri, Yibei Chen, Puja Trivedi, Dorota Jarecka, Saif Haobsh, Patrick Ray, Lydia Ng, Satrajit S. Ghosh
分类: cs.CL, cs.AI
发布日期: 2025-07-04 (更新: 2025-08-05)
备注: -
💡 一句话要点
提出StructSense框架,利用领域知识和人机协同提升LLM在结构化信息抽取中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化信息抽取 大型语言模型 领域知识 人机协同 本体 agentic框架 神经科学 知识图谱
📋 核心要点
- 现有LLM在特定领域结构化信息抽取中效果不佳,且跨任务泛化能力弱,限制了其应用。
- StructSense利用领域本体知识引导LLM,并通过agentic自评估和人机协同进行迭代优化。
- 实验表明,StructSense能有效提升LLM在神经科学信息抽取任务中的性能,并具备良好的跨任务泛化能力。
📝 摘要(中文)
从非结构化来源(如自由文本和科学文献)中提取结构化信息的能力对于加速科学发现和知识综合至关重要。大型语言模型(LLM)在各种自然语言处理任务(包括结构化信息提取)中表现出了卓越的能力。然而,在需要细致理解和专家级领域知识的特定领域环境中,它们的有效性通常会降低。此外,现有的基于LLM的方法通常表现出较差的跨任务和跨领域迁移能力,限制了它们的可扩展性和适应性。为了解决这些挑战,我们引入了StructSense,这是一个基于LLM的模块化、任务无关、开源的结构化信息提取框架。StructSense由本体中编码的领域特定符号知识引导,使其能够更有效地处理复杂的领域内容。它还通过自评估判断器融入了agentic能力,形成迭代改进的反馈循环,并包含人机协同机制以确保质量和验证。我们证明了StructSense可以克服领域敏感性和缺乏跨任务泛化性的限制,这通过其在各种神经科学信息提取任务中的应用得到了证明。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在特定领域结构化信息抽取任务中表现不佳,以及跨任务泛化能力不足的问题。现有方法在处理需要专业领域知识和细致理解的复杂内容时,效果会显著下降。此外,它们在不同任务和领域之间的迁移能力有限,难以扩展和适应新的应用场景。
核心思路:StructSense的核心思路是利用领域特定的符号知识(通过本体编码)来引导LLM,使其能够更有效地理解和处理复杂的领域内容。同时,引入agentic能力,通过自评估判断器形成反馈循环,迭代优化抽取结果。此外,加入人机协同机制,确保抽取结果的质量和可靠性。
技术框架:StructSense是一个模块化的框架,主要包含以下几个核心模块:1) 领域知识编码模块:将领域知识编码为本体,为LLM提供结构化的知识指导。2) LLM驱动的抽取模块:利用LLM进行初始的信息抽取,并根据领域知识进行约束。3) 自评估判断模块:使用自评估判断器对抽取结果进行评估,并生成反馈信号。4) 人机协同模块:允许人工干预和验证抽取结果,确保质量。5) 迭代优化模块:根据反馈信号和人工验证结果,迭代优化LLM的抽取策略。
关键创新:StructSense的关键创新在于其将领域知识、agentic自评估和人机协同机制有机结合,形成一个闭环的迭代优化系统。与传统的LLM方法相比,StructSense能够更好地利用领域知识,提高抽取精度和泛化能力。同时,通过自评估和人机协同,能够有效地解决LLM在复杂场景下的幻觉问题,提高抽取结果的可靠性。
关键设计:StructSense的关键设计包括:1) 领域本体的设计:需要根据具体的领域知识,构建合适的本体结构,定义实体、关系和属性。2) 自评估判断器的设计:需要设计合适的评估指标和判断逻辑,能够准确评估抽取结果的质量。3) 人机协同界面的设计:需要提供友好的用户界面,方便人工干预和验证抽取结果。4) 迭代优化策略的设计:需要设计合适的优化算法,能够根据反馈信号和人工验证结果,有效地优化LLM的抽取策略。
🖼️ 关键图片

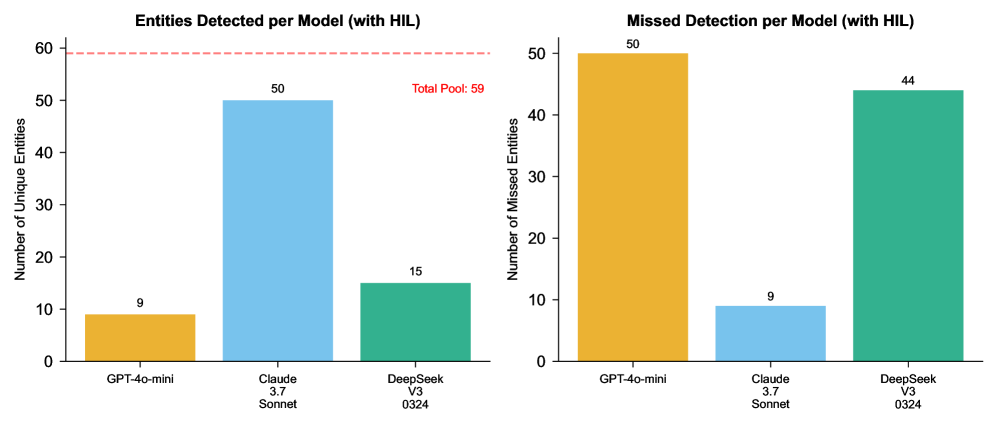
📊 实验亮点
论文通过在多个神经科学信息提取任务上的实验,验证了StructSense的有效性。实验结果表明,StructSense能够显著提高LLM在这些任务上的性能,并具备良好的跨任务泛化能力。具体性能数据未知,但强调了StructSense在克服领域敏感性和缺乏跨任务泛化性方面的优势。
🎯 应用场景
StructSense可应用于各种需要从非结构化文本中提取结构化信息的领域,如生物医学、金融、法律等。它能够帮助研究人员和专业人士快速获取和整合领域知识,加速科学发现和决策过程。未来,StructSense有望成为构建领域知识图谱和智能问答系统的关键技术。
📄 摘要(原文)
The ability to extract structured information from unstructured sources-such as free-text documents and scientific literature-is critical for accelerating scientific discovery and knowledge synthesis. Large Language Models (LLMs) have demonstrated remarkable capabilities in various natural language processing tasks, including structured information extraction. However, their effectiveness often diminishes in specialized, domain-specific contexts that require nuanced understanding and expert-level domain knowledge. In addition, existing LLM-based approaches frequently exhibit poor transferability across tasks and domains, limiting their scalability and adaptability. To address these challenges, we introduce StructSense, a modular, task-agnostic, open-source framework for structured information extraction built on LLMs. StructSense is guided by domain-specific symbolic knowledge encoded in ontologies, enabling it to navigate complex domain content more effectively. It further incorporates agentic capabilities through self-evaluative judges that form a feedback loop for iterative refinement, and includes human-in-the-loop mechanisms to ensure quality and validation. We demonstrate that StructSense can overcome both the limitations of domain sensitivity and the lack of cross-task generalizability, as shown through its application to diverse neuroscience information extraction tasks.