BMMR: A Large-Scale Bilingual Multimodal Multi-Discipline Reasoning Dataset
作者: Zhiheng Xi, Guanyu Li, Yutao Fan, Honglin Guo, Yufang Liu, Xiaoran Fan, Jiaqi Liu, Jingchao Ding, Wangmeng Zuo, Zhenfei Yin, Lei Bai, Tao Ji, Tao Gui, Qi Zhang, Philip Torr, Xuanjing Huang
分类: cs.CL, cs.AI
发布日期: 2025-07-04 (更新: 2025-07-08)
备注: Preprint
💡 一句话要点
提出BMMR:一个大规模双语多模态多学科推理数据集,用于评估和提升大型多模态模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 多学科推理 大型数据集 双语数据集 知识推理 模型评估 自然语言处理
📋 核心要点
- 现有大型多模态模型在跨学科知识推理方面存在不足,缺乏高质量、大规模的多学科数据集进行训练和评估。
- 论文构建了一个大规模双语多模态多学科推理数据集BMMR,包含高质量的问题和推理路径,覆盖广泛的学科领域。
- 实验表明,即使是最先进的模型在BMMR数据集上仍有提升空间,且模型存在学科偏差,微调可以缩小开源模型与专有模型的差距。
📝 摘要(中文)
本文介绍BMMR,一个大规模双语、多模态、多学科推理数据集,旨在促进社区开发和评估大型多模态模型(LMMs)。BMMR包含11万个大学水平的问题,涵盖联合国教科文组织定义的300个学科,问题形式多样,包括选择题、填空题和开放式问答,数据来源于书籍、考试和测验等印刷和数字媒体。所有数据都经过人工循环和可扩展框架的整理和过滤,并且每个实例都配有高质量的推理路径。该数据集分为两部分:BMMR-Eval包含20458个高质量实例,用于全面评估LMMs在中英文多学科知识和推理能力;BMMR-Train包含88991个实例,支持进一步研究和开发,将当前对数学推理的关注扩展到不同的学科和领域。此外,我们提出了基于过程的多学科验证器(即BMMR-Verifier),用于准确和细粒度地评估推理路径。对24个模型的广泛实验表明:(i)即使是SOTA模型(例如,o3和Gemini-2.5-Pro)在BMMR-Eval上仍有很大的提升空间;(ii)推理模型表现出学科偏差,仅在特定学科上优于LMMs;(iii)开源模型仍然落后于其专有模型;(iv)在BMMR-Train上进行微调可以缩小这种差距。此外,我们使用BMMR-Verifier和其他深入研究进行了推理链分析,揭示了LMMs目前在多学科推理中面临的挑战。我们将发布数据,并希望我们的工作能够为社区提供见解和贡献。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在处理需要跨多个学科知识进行推理的问题时表现不佳。缺乏一个足够大、涵盖足够广学科范围、并且具有高质量推理路径的数据集,使得LMMs难以学习和评估其多学科推理能力。现有数据集往往集中在数学推理或特定领域,无法满足对通用多学科推理能力的需求。
核心思路:论文的核心思路是构建一个大规模、高质量、双语(中英文)的多模态多学科推理数据集BMMR。通过覆盖广泛的学科领域,提供多样的问题形式和高质量的推理路径,来促进LMMs在多学科知识推理方面的学习和评估。数据集的设计目标是能够全面评估LMMs的知识储备、推理能力以及对不同学科的理解程度。
技术框架:BMMR数据集的构建流程主要包括以下几个阶段:1) 数据收集:从书籍、考试、测验等多种来源收集数据,涵盖联合国教科文组织定义的300个学科。2) 数据清洗和过滤:采用人工循环的方式,对收集到的数据进行清洗、过滤和筛选,确保数据的质量和准确性。3) 推理路径生成:为每个问题生成高质量的推理路径,详细描述解决问题的步骤和逻辑。4) 数据集划分:将数据集划分为BMMR-Eval和BMMR-Train两部分,分别用于模型评估和训练。5) 验证器构建:构建基于过程的多学科验证器(BMMR-Verifier),用于准确评估推理路径的质量。
关键创新:BMMR数据集的关键创新在于其大规模、多学科和双语特性,以及高质量的推理路径。与现有数据集相比,BMMR覆盖了更广泛的学科领域,提供了更全面的问题类型,并且提供了详细的推理路径,有助于LMMs学习和理解问题的解决过程。此外,BMMR-Verifier的提出,为推理路径的评估提供了一种更准确和细粒度的方法。
关键设计:BMMR数据集包含11万个大学水平的问题,涵盖300个学科。问题形式包括选择题、填空题和开放式问答。数据集分为BMMR-Eval(20458个实例)和BMMR-Train(88991个实例)两部分。BMMR-Verifier采用基于过程的方法,对推理路径的每一步进行验证,从而实现对推理过程的细粒度评估。论文中没有明确提及具体的参数设置、损失函数或网络结构,因为BMMR主要是一个数据集,而非特定的模型或算法。
🖼️ 关键图片
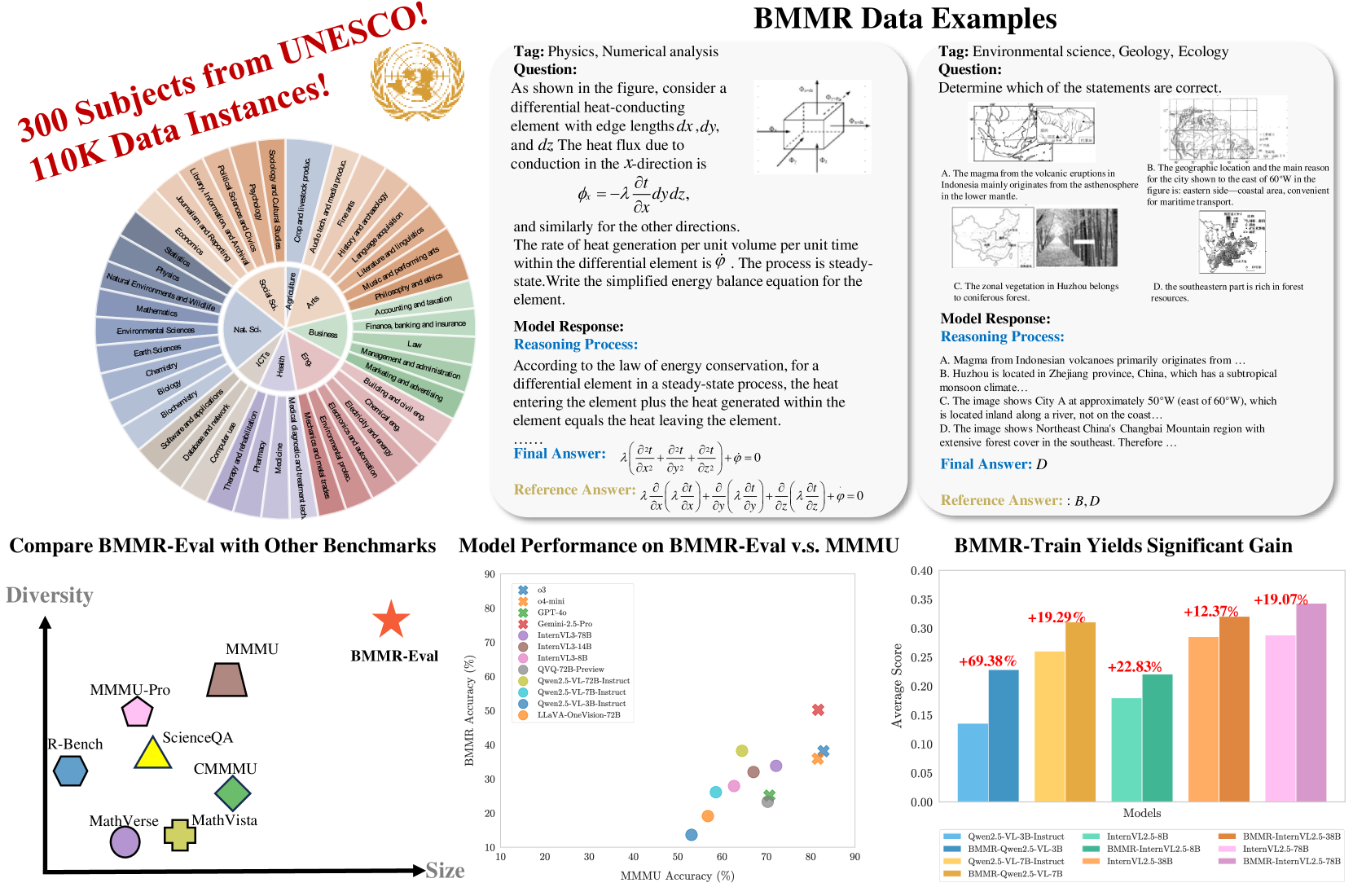
📊 实验亮点
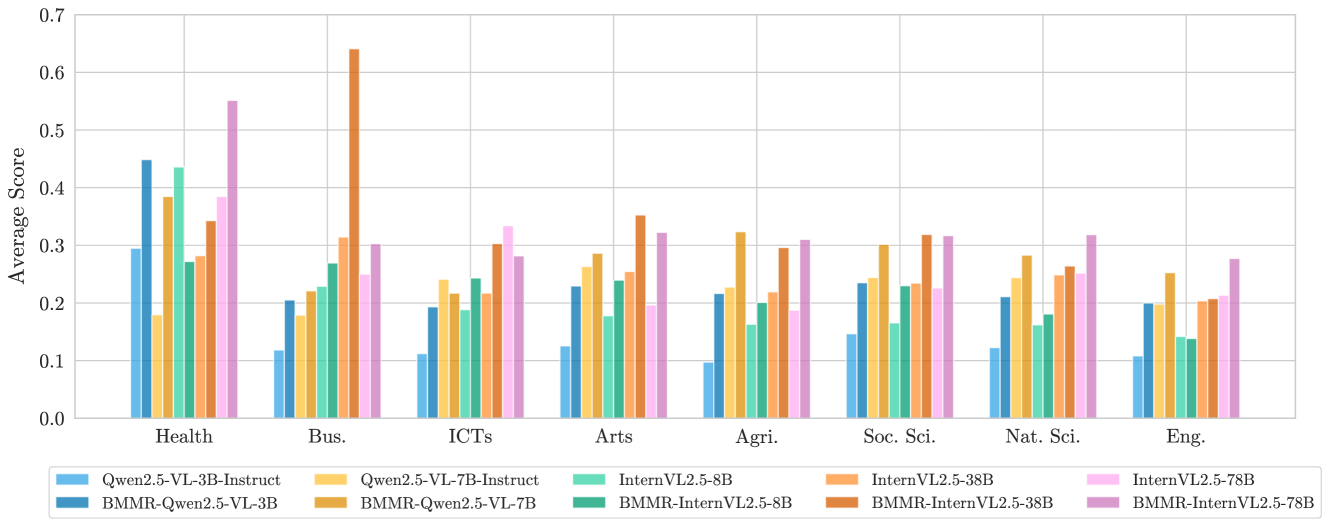
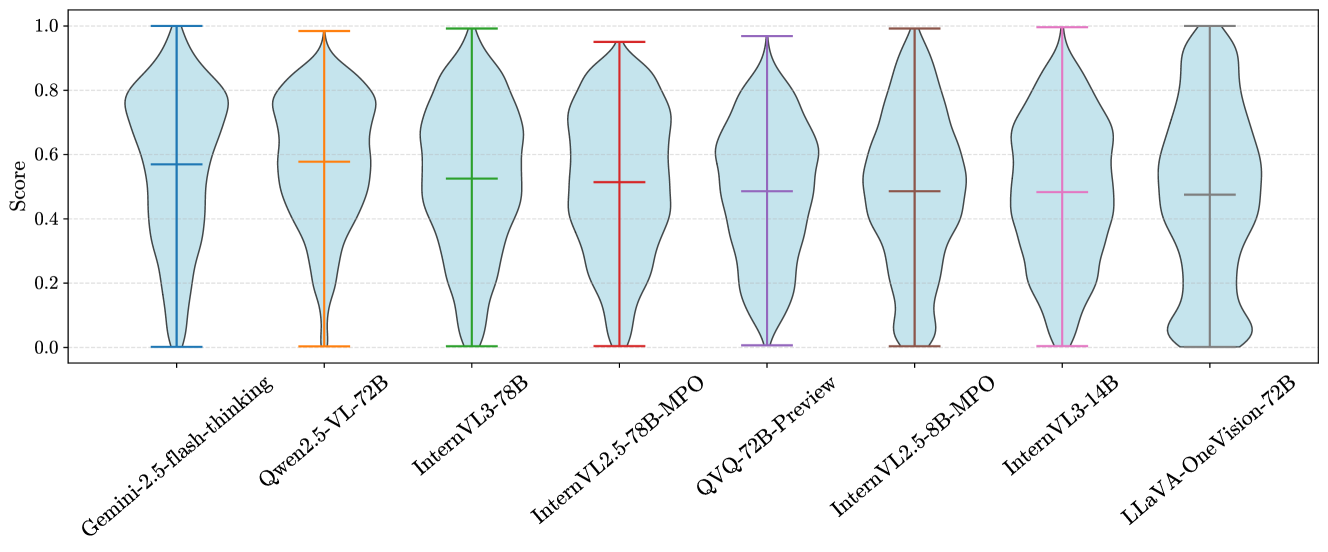
实验结果表明,即使是SOTA模型(如o3和Gemini-2.5-Pro)在BMMR-Eval上仍有很大的提升空间。推理模型表现出学科偏差,仅在特定学科上优于LMMs。开源模型仍然落后于其专有模型,但在BMMR-Train上进行微调可以缩小这种差距。这些结果揭示了LMMs在多学科推理方面面临的挑战,并为未来的研究方向提供了指导。
🎯 应用场景
BMMR数据集可广泛应用于大型多模态模型的训练和评估,尤其是在需要跨学科知识推理的场景中。例如,智能问答系统、教育辅助工具、科研助手等。该数据集能够促进LMMs在更广泛的领域中应用,并提升其解决复杂问题的能力。未来,BMMR可以扩展到更多语言和学科,进一步提升LMMs的通用性和智能化水平。
📄 摘要(原文)
In this paper, we introduce BMMR, a large-scale bilingual, multimodal, multi-disciplinary reasoning dataset for the community to develop and evaluate large multimodal models (LMMs). BMMR comprises 110k college-level questions spanning 300 UNESCO-defined subjects, spanning diverse formats-multiple-choice, fill-in-the-blank, and open-ended QA-and sourced from both print and digital media such as books, exams, and quizzes. All data are curated and filtered via a human-in-the-loop and scalable framework, and each instance is paired with a high-quality reasoning path. The dataset is organized into two parts: BMMR-Eval that comprises 20,458 high-quality instances to comprehensively assess LMMs' knowledge and reasoning across multiple disciplines in both Chinese and English; and BMMR-Train that contains 88,991 instances to support further research and development, extending the current focus on mathematical reasoning to diverse disciplines and domains. In addition, we propose the process-based multi-discipline verifier (i.e., BMMR-Verifier) for accurate and fine-grained evaluation of reasoning paths. Extensive experiments on 24 models reveal that (i) even SOTA models (e.g., o3 and Gemini-2.5-Pro) leave substantial headroom on BMMR-Eval; (ii) reasoning models exhibit discipline bias and outperform LMMs only on specific subjects; (iii) open-source models still trail their proprietary counterparts; and (iv) fine-tuning on BMMR-Train narrows this gap. Additionally, we conduct reasoning-chain analyses using BMMR-Verifier and other in-depth studies, uncovering the challenges LMMs currently face in multidisciplinary reasoning. We will release the data, and we hope our work can offer insights and contributions to the community.